Python GIS自动化:批量处理矢量数据和制图导出
Python GIS自动化:批量处理矢量数据和制图导出,适合已经会一点 Python、但还在手动打开软件、逐个图层检查字段和导出成果的 GIS 学习者。本文不追求炫技,而是给出一套可复用的自动化思路:先把输入数据整理成清单,再用脚本完成检查、转换、统计和制图导出。
引言
很多 GIS 项目真正耗时的地方,不是某一个复杂算法,而是重复劳动:几十个行政区边界要统一坐标系,几百个图斑文件要检查字段,多个专题图要按同一版式导出。Python GIS自动化的价值,就是把这些可描述、可重复、可检查的步骤交给脚本。
这篇文章围绕一个常见任务展开:批量读取一个目录下的矢量数据,检查坐标系和字段,修复常见几何问题,输出清洗后的 GeoPackage,并为后续制图导出准备统计结果。
背景
在 GIS 工作中,Python 通常不是替代 QGIS 或 ArcGIS Pro,而是补上批处理和质量控制这一环。桌面软件适合交互检查和人工判断,Python 适合处理规则明确的大量文件。
常见的 Python GIS 自动化工具包括 GeoPandas、Shapely、Fiona、pyogrio、GDAL、Rasterio 和 ArcPy。开源流程通常使用 GeoPandas 与 GDAL,ArcGIS Pro 项目内的企业流程则常用 ArcPy。无论选哪一套,核心思想都是一样的:把人工操作拆成输入、处理、检查、输出四个阶段。
原理
一个稳定的 Python GIS 自动化流程,通常要先回答四个问题。
- 输入在哪里:数据目录、文件格式、图层命名规则是否固定。
- 质量怎么判断:坐标系、字段、空几何、无效几何、重复编号是否需要检查。
- 结果输出什么:是 Shapefile、GeoPackage、PostGIS 表,还是 PDF 地图和 Excel 统计表。
- 失败如何记录:脚本不能只报错退出,还要写出哪个文件失败、失败原因是什么。
因此,自动化脚本不是把软件按钮翻译成代码,而是把项目规范写成可执行的检查规则。
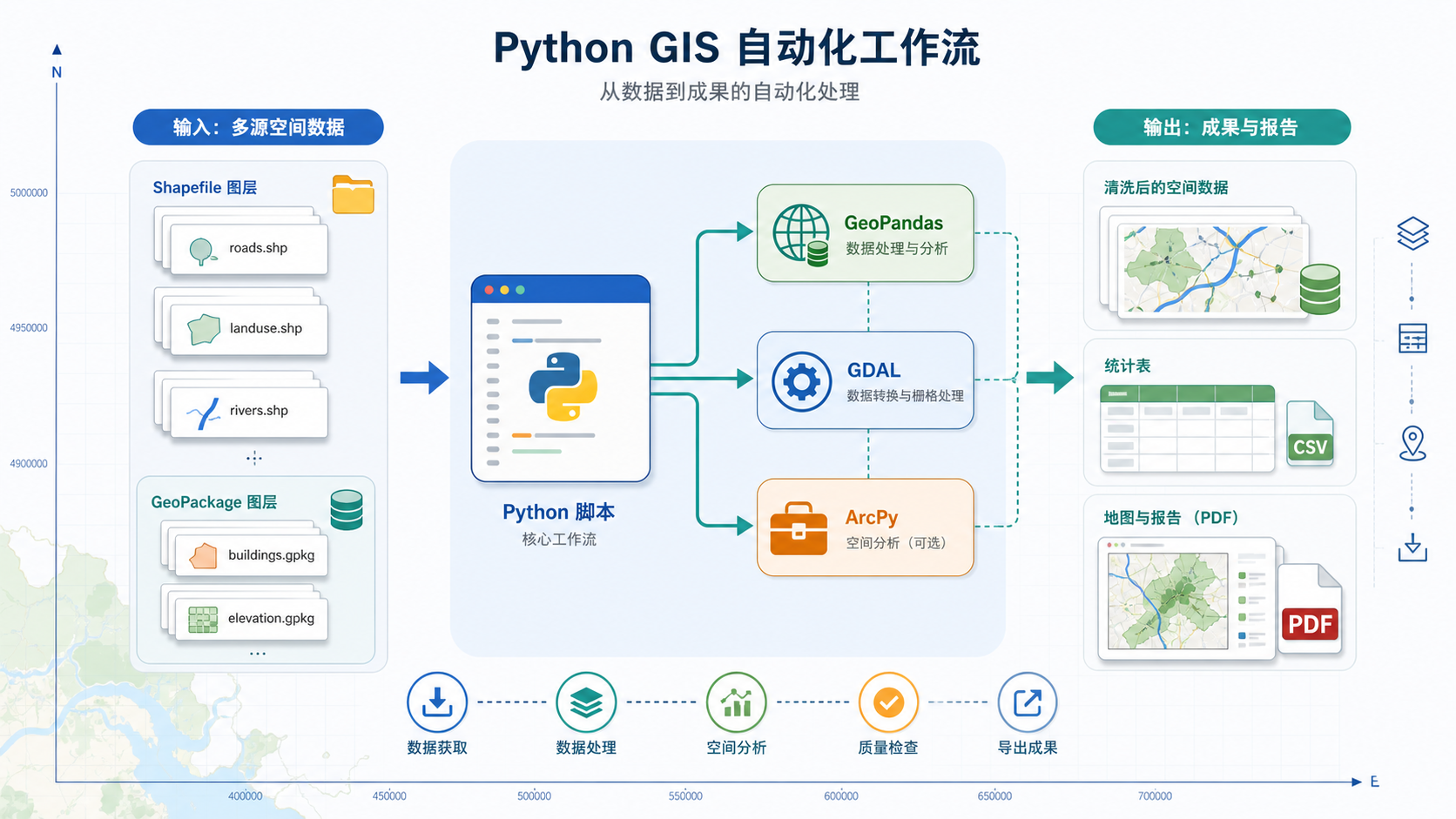
步骤
步骤一:整理项目目录
建议先建立清晰的目录结构,不要让脚本直接在原始数据上反复覆盖。
project/
input/
county_a.shp
county_b.shp
output/
logs/
scripts/
batch_vector_process.pyinput 保存原始数据,output 保存清洗后的成果,logs 保存检查记录。这样即使脚本中途失败,也能回到原始状态重新处理。
步骤二:批量读取矢量文件
下面的示例使用 GeoPandas 批量读取 Shapefile。实际项目中,如果数据量较大,也可以优先考虑 GeoPackage 或数据库表,减少 Shapefile 字段名长度和编码带来的问题。
from pathlib import Path
import geopandas as gpd
input_dir = Path("project/input")
files = sorted(input_dir.glob("*.shp"))
for path in files:
gdf = gpd.read_file(path)
print(path.name, len(gdf), gdf.crs)这一步不要急着处理数据,先确认脚本能稳定遍历所有文件,并输出每个文件的要素数量和坐标系。
步骤三:检查坐标系和必要字段
批处理最容易出问题的地方,是不同文件看起来类似,但字段名、坐标系或几何类型并不一致。可以先写一个检查函数。
required_fields = {"name", "code"}
target_crs = "EPSG:4490"
missing = required_fields - set(gdf.columns)
if missing:
raise ValueError(f"{path.name} 缺少字段: {missing}")
if gdf.crs is None:
raise ValueError(f"{path.name} 没有定义坐标系")
if gdf.crs.to_string() != target_crs:
gdf = gdf.to_crs(target_crs)这里要区分两个概念:定义坐标系 是告诉软件数据原本是什么坐标系,投影转换 是把坐标值真正转换到另一个坐标系。很多面积不准、叠加错位问题都来自这一步混淆。
步骤四:修复无效几何并输出结果
矢量叠加、裁剪和面积统计前,建议检查空几何和无效几何。不同项目对修复方式要求不同,下面只给出一个常见的入门写法。
gdf = gdf[gdf.geometry.notna()].copy()
invalid_mask = ~gdf.geometry.is_valid
if invalid_mask.any():
gdf.loc[invalid_mask, "geometry"] = gdf.loc[invalid_mask, "geometry"].buffer(0)
out_path = Path("project/output") / f"{path.stem}_clean.gpkg"
gdf.to_file(out_path, layer="clean", driver="GPKG")buffer(0) 可以修复一部分自相交面,但不是所有几何问题的万能方案。正式项目中,应把修复前后的要素数量、面积变化和失败记录写入日志,避免悄悄改变成果。
步骤五:生成统计表和制图输入
清洗后的数据可以继续生成统计结果,例如按行政区代码统计面积。
gdf["area_m2"] = gdf.to_crs("EPSG:3857").area
summary = gdf.groupby("code", as_index=False)["area_m2"].sum()
summary.to_csv("project/output/area_summary.csv", index=False)面积统计必须使用适合面积计算的投影坐标系。上面的坐标系只适合演示,不代表所有地区都应该使用它。实际工作中,应根据项目区域选择合适的等面积投影或本地投影坐标系。
步骤六:自动制图导出
如果使用 ArcGIS Pro,可以用 ArcPy 打开既有工程模板、替换数据源并导出 PDF。如果使用 QGIS,可以通过 PyQGIS 调用布局模板。更稳妥的做法是先由人工设计一个模板,再让 Python 负责批量替换数据和导出。
# ArcPy 思路示例,需在 ArcGIS Pro Python 环境中运行
# aprx = arcpy.mp.ArcGISProject("template.aprx")
# layout = aprx.listLayouts("main")[0]
# layout.exportToPDF("project/output/map.pdf")制图自动化的重点不是把所有地图都做成同一种样子,而是把比例尺、图名、图例、数据源和导出命名这些容易出错的环节标准化。
常见坑
- 路径写死:脚本只能在作者电脑上运行,换一台机器就找不到数据。
- 坐标系未定义:数据没有 CRS,却直接执行投影转换,结果可能完全错误。
- Shapefile 字段被截断:字段名超过限制后被截短,批处理时找不到原字段。
- 覆盖原始数据:脚本运行失败后无法恢复,只能重新找数据源。
- 没有日志:只知道脚本失败,不知道哪个文件、哪个要素、哪一步失败。
- 把示例投影当通用投影:面积、长度和缓冲区分析必须根据项目区域选择合适坐标系。
方法比较
| 方法 | 适合场景 | 注意事项 |
|---|---|---|
| GeoPandas | 矢量数据清洗、字段处理、空间连接、统计分析 | 大数据量时要关注内存占用和文件格式 |
| GDAL/OGR | 格式转换、批量投影、命令行自动化 | 参数多,建议先在少量样例上验证 |
| ArcPy | ArcGIS Pro 工程、企业数据、批量制图导出 | 依赖 ArcGIS Pro 授权和对应 Python 环境 |
| PyQGIS | QGIS 项目、布局模板、开源制图流程 | 运行环境配置比普通 Python 脚本更复杂 |
检查清单
- 是否保留了一份不被脚本覆盖的原始数据。
- 是否明确输入格式、输出格式和命名规则。
- 是否检查了坐标系、字段、空几何和无效几何。
- 是否把失败文件和失败原因写入日志。
- 是否在正式批处理前,用 2 到 3 个样例文件试跑。
- 是否人工抽查了输出数据的位置、属性、面积和制图效果。
FAQ
Python GIS自动化一定要先学 ArcPy 吗?
不一定。如果你的工作主要在 ArcGIS Pro 生态内,ArcPy 很重要。如果你更关注开源数据处理、WebGIS 数据准备或跨平台脚本,GeoPandas、GDAL 和 Rasterio 往往更适合作为起点。
GeoPandas 能处理所有 GIS 批量任务吗?
不能。GeoPandas 很适合中小规模矢量数据处理,但栅格处理通常要用 Rasterio 或 GDAL,大规模空间查询更适合 PostGIS,复杂桌面制图则可能需要 ArcPy 或 PyQGIS。
为什么脚本运行成功,结果还是可能错?
因为脚本只能执行你写进去的规则。如果没有检查坐标系、字段含义、单位和异常几何,程序成功结束也可能只是批量生成了一批错误结果。
初学者应该从哪个自动化任务开始?
建议从批量读取文件、检查字段、统一坐标系和输出 GeoPackage 开始。这类任务足够真实,也比较容易验证结果。
结论
Python GIS自动化的核心不是写一段很长的脚本,而是把重复 GIS 工作拆成可检查的步骤。对于初学者,先从批量处理矢量数据开始,建立目录规范、检查规则、日志记录和输出标准,再逐步扩展到空间分析、PostGIS 入库和自动制图导出。这样写出来的脚本,才真正能在项目里省时间、少出错、可交付。