WebGIS 实战
把地图前端、空间服务和数据排障串成完整项目能力
围绕 OpenLayers、Cesium、GeoServer、PostGIS 和前端工程化,优先解决真实项目里最常遇到的地图加载、坐标、性能和发布问题。
进入 WebGIS 路线
围绕 OpenLayers、Cesium、GeoServer、PostGIS 和前端工程化,优先解决真实项目里最常遇到的地图加载、坐标、性能和发布问题。
进入 WebGIS 路线从基础概念、桌面工具、WebGIS 开发到空间自动化,按当前任务进入。
优先展示能直接解决问题、串起下一步阅读的高价值文章。
从学习成本、投影支持、数据服务、交互编辑和长期维护角度,...
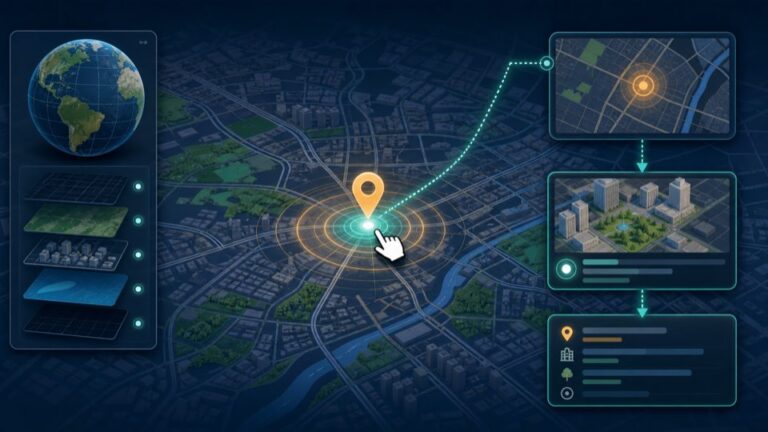
讲解 WebGIS 坐标拾取功能的前端事件、坐标转换、展...
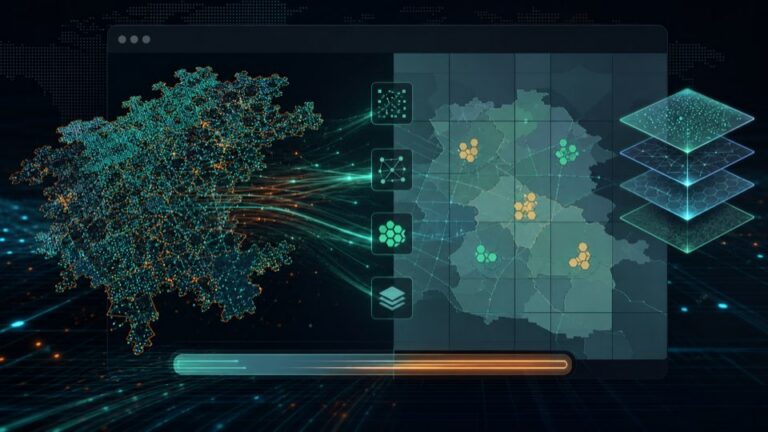
从文件体积、浏览器解析、渲染压力和数据服务化四个维度,讲...
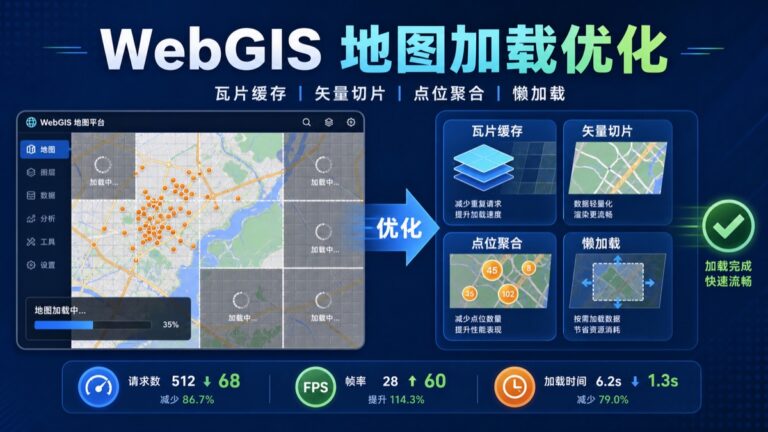
WebGIS 地图加载慢,通常和底图瓦片、业务图层、接口...
优先展示能直接解决问题、串起下一步阅读的高价值文章。

解释 Python 读取 Shapefile 中文乱码的...

解释 GeoPandas buffer 距离单位异常的根...
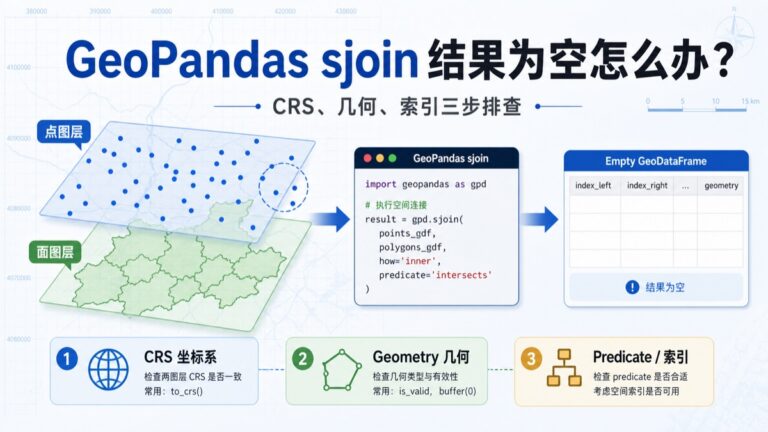
GeoPandas 使用 sjoin 做空间连接时,明明...
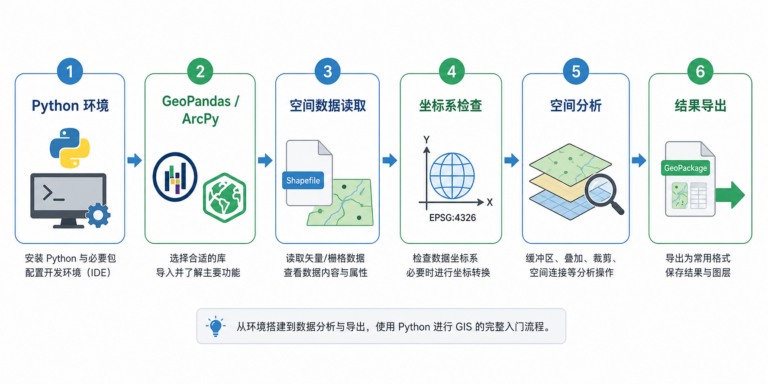
引言:gis python 开发入门全解析,gis Py...
优先展示能直接解决问题、串起下一步阅读的高价值文章。