亿级轨迹数据查询慢?ES性能如何优化?
如果你正在排查“亿级轨迹数据查询慢?ES性能如何优化?”这个问题,通常不是简单把 Elasticsearch 集群机器加大就能解决。轨迹数据的特点是点多、时间连续、空间范围查询频繁、用户或车辆 ID 过滤频繁,一旦索引设计、分片、时间分区和查询方式不合理,亿级轨迹数据查询慢会很快暴露出来。
本文面向 GIS 工程师、WebGIS 开发者和空间数据分析人员,重点讲清楚:为什么 ES 查询轨迹会慢,如何从索引建模、分片策略、空间时间查询、冷热数据、聚合统计和前端返回量几个方面做性能优化。
引言:亿级轨迹数据查询慢最常见的表现
在 WebGIS 项目中,轨迹数据通常来自车辆 GPS、人员定位、船舶 AIS、物联网设备或移动端打点。数据量达到亿级后,常见现象包括:
- 按车辆 ID 查询一天轨迹需要十几秒甚至超时。
- 地图框选一个区域后,返回点位过多,前端地图直接卡死。
- 按时间范围查询时 CPU 飙高,磁盘 IO 很高。
- 轨迹回放接口在高峰期不稳定。
- 统计某区域内设备数量、停留点或里程时响应很慢。
这些问题背后往往不是单一原因。亿级轨迹数据查询慢,通常是索引设计、查询条件、分片规划和返回结果控制共同造成的。
背景:为什么 GIS 轨迹数据在 ES 中容易变慢
Elasticsearch 适合做海量文档检索和过滤,也支持 geo_point、geo_shape 等空间字段。但轨迹数据和普通日志不一样,它具有明显的 GIS 特征:
- 时间维度强:大多数查询都会带开始时间和结束时间。
- 空间维度强:常见查询包括地图范围、行政区范围、缓冲区范围、附近点查询。
- 对象维度强:经常按车辆 ID、人员 ID、设备 ID 查询完整轨迹。
- 点数量密集:一个对象一天可能产生几百到几万条轨迹点。
- 前端展示有限:地图上并不适合一次渲染几十万点。
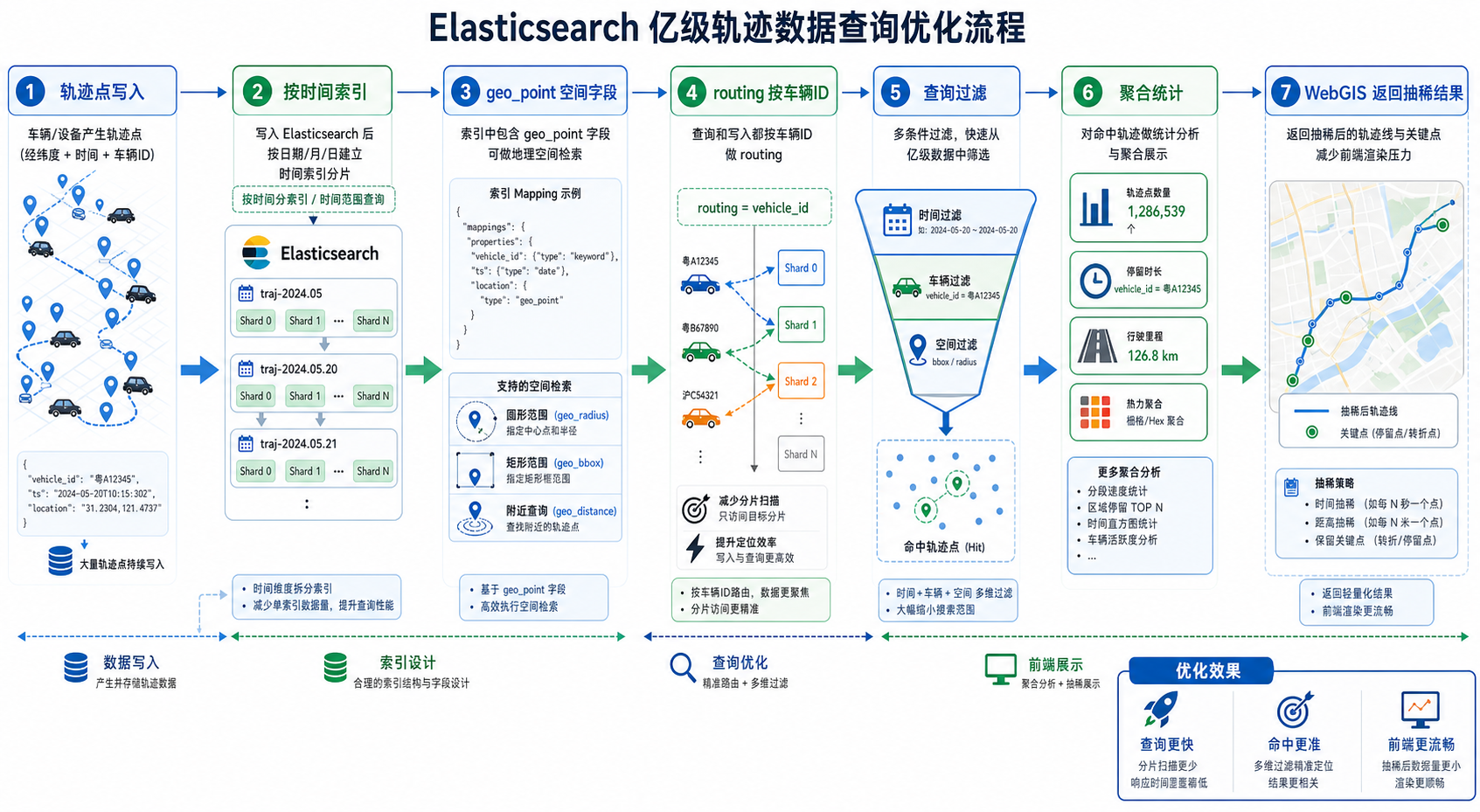
如果直接把所有轨迹点写进一个大索引,再用默认分片和通用查询,随着数据量增加,查询会越来越慢。亿级轨迹数据查询慢时,第一步不是立刻调 JVM 参数,而是先检查数据模型和查询路径是否合理。
原理:ES 查询轨迹数据的核心优化思路
ES 查询性能优化的核心不是“让所有查询都扫得更快”,而是尽量让查询扫描更少的数据。对于轨迹数据,建议围绕四个维度优化:
- 按时间减少索引范围:用按天、按月或按业务周期拆分索引,避免跨全量索引查询。
- 按对象减少分片扫描:对车辆 ID、设备 ID 等高频过滤字段使用合理的 routing 或字段设计。
- 按空间减少候选点:使用
geo_point字段和合适的空间过滤条件。 - 按展示控制返回量:轨迹回放、地图点展示、热力图统计不能都返回原始全量点。
在 ES 中,轨迹点一般建议建模为一条点记录,而不是把一整条轨迹塞进一个超大文档。典型字段如下:
{
"device_id": "car_10001",
"loc": {
"lat": 31.2304,
"lon": 121.4737
},
"timestamp": "2025-01-10T08:30:00Z",
"speed": 42.5,
"direction": 128,
"status": "normal"
}其中 loc 使用 geo_point,timestamp 使用 date,device_id 使用 keyword。这是后续做 ES 性能优化的基础。
步骤:亿级轨迹数据查询慢的 ES 性能优化流程
步骤一:先确认慢查询是哪一类
优化前先分类,否则容易盲目调参。轨迹查询通常可以分为以下几类:
| 查询类型 | 典型场景 | 主要瓶颈 |
|---|---|---|
| 单对象轨迹查询 | 查询某辆车一天轨迹 | 时间范围、device_id过滤、排序 |
| 地图范围查询 | 当前视野内显示车辆点 | 空间过滤、返回量过大 |
| 轨迹回放 | 按时间顺序播放历史轨迹 | 排序、分页、点数过多 |
| 空间统计 | 区域内车辆数量、热力图 | 聚合计算、空间候选集过大 |
| 异常分析 | 超速、停留、越界 | 条件组合复杂、历史数据扫描大 |
建议先打开 ES 慢查询日志,并用 profile 分析具体慢在哪个阶段。不要只看接口总耗时,因为前端渲染、网络传输、应用层组装也可能占用大量时间。
步骤二:使用按时间拆分索引,避免单个巨型索引
亿级轨迹数据查询慢,最常见原因之一是所有数据写入同一个索引。轨迹查询大多带时间条件,所以索引应按时间拆分。
常见设计如下:
- 日索引:
trajectory-2025.01.10,适合写入量大、查询多集中在最近几天。 - 月索引:
trajectory-2025.01,适合日写入量中等、查询跨度较长。 - 冷热分层索引:近期数据用热节点,历史数据用冷节点或归档策略。
例如查询某辆车 2025 年 1 月 10 日的轨迹时,只访问当天索引,而不是访问所有历史轨迹索引。
GET trajectory-2025.01.10/_search
{
"query": {
"bool": {
"filter": [
{ "term": { "device_id": "car_10001" } },
{
"range": {
"timestamp": {
"gte": "2025-01-10T00:00:00Z",
"lte": "2025-01-10T23:59:59Z"
}
}
}
]
}
},
"sort": [
{ "timestamp": "asc" }
],
"size": 10000
}如果业务允许,前端查询时应先根据时间范围计算要访问的索引名,而不是直接查询通配符 trajectory-*。
步骤三:正确设置轨迹字段 mapping
轨迹数据 mapping 不合理,会直接影响 ES 性能优化效果。建议显式创建索引模板,避免 ES 自动推断字段类型。
PUT _index_template/trajectory_template
{
"index_patterns": ["trajectory-*"],
"template": {
"mappings": {
"properties": {
"device_id": { "type": "keyword" },
"loc": { "type": "geo_point" },
"timestamp": { "type": "date" },
"speed": { "type": "float" },
"direction": { "type": "short" },
"status": { "type": "keyword" }
}
}
}
}重点检查:
device_id不要用text,应使用keyword。timestamp必须是date,不要存成字符串。- 经纬度字段应使用
geo_point,不要只存两个普通数值字段。 - 不需要全文检索的字段不要开启过多分析能力。
步骤四:用 filter 上下文替代不必要的评分查询
轨迹查询大多数是过滤,不需要相关性评分。因此应尽量使用 bool.filter,而不是把所有条件放进 must 里进行评分计算。
GET trajectory-2025.01.10/_search
{
"query": {
"bool": {
"filter": [
{ "term": { "device_id": "car_10001" } },
{
"range": {
"timestamp": {
"gte": "2025-01-10T08:00:00Z",
"lte": "2025-01-10T10:00:00Z"
}
}
},
{
"geo_bounding_box": {
"loc": {
"top_left": {
"lat": 31.35,
"lon": 121.30
},
"bottom_right": {
"lat": 31.10,
"lon": 121.70
}
}
}
}
]
}
},
"sort": [
{ "timestamp": "asc" }
],
"size": 5000
}对于地图视野查询,geo_bounding_box 通常比复杂多边形过滤更轻。如果只是当前地图窗口内查点,优先使用矩形范围。
步骤五:控制返回字段和返回数量
很多亿级轨迹数据查询慢,其实慢在返回量太大。ES 查到了几十万点,应用服务再序列化成 JSON,浏览器再渲染,整个链路都会变慢。
建议使用 _source 过滤,只返回前端需要的字段:
GET trajectory-2025.01.10/_search
{
"_source": ["device_id", "loc", "timestamp", "speed"],
"query": {
"bool": {
"filter": [
{ "term": { "device_id": "car_10001" } },
{
"range": {
"timestamp": {
"gte": "2025-01-10T00:00:00Z",
"lte": "2025-01-10T23:59:59Z"
}
}
}
]
}
},
"sort": [
{ "timestamp": "asc" }
],
"size": 5000
}如果一天轨迹点很多,不建议一次返回全部原始点。可以按地图比例尺或回放速度做抽稀,例如:
- 缩小比例尺时只返回每隔 N 个点。
- 按时间间隔抽样,例如每 10 秒或 30 秒返回一个点。
- 用后端预处理生成简化轨迹。
- 轨迹分析用全量数据,地图展示用简化数据。
步骤六:对高频单对象查询考虑 routing
如果业务中大量查询都是“按设备 ID 查询轨迹”,可以考虑使用 routing,让同一设备的数据尽量落到同一分片。这样查询时不必扫描所有分片。
写入时指定 routing:
POST trajectory-2025.01.10/_doc?routing=car_10001
{
"device_id": "car_10001",
"loc": {
"lat": 31.2304,
"lon": 121.4737
},
"timestamp": "2025-01-10T08:30:00Z",
"speed": 42.5
}查询时也指定同样的 routing:
GET trajectory-2025.01.10/_search?routing=car_10001
{
"query": {
"bool": {
"filter": [
{ "term": { "device_id": "car_10001" } },
{
"range": {
"timestamp": {
"gte": "2025-01-10T00:00:00Z",
"lte": "2025-01-10T23:59:59Z"
}
}
}
]
}
},
"sort": [
{ "timestamp": "asc" }
]
}但 routing 不是万能的。如果某些设备数据量特别大,可能造成分片热点。使用前要确认设备数据分布是否均衡。
步骤七:合理设置分片数量,不要盲目越多越好
分片过少会导致单分片过大,分片过多会导致查询协调开销增加。轨迹数据的分片数应根据单日写入量、索引大小、节点数量和查询并发来定。
实践中可以遵循几个原则:
- 不要长期使用默认分片配置而不评估。
- 单个分片过大时,恢复、迁移和查询都会变慢。
- 小索引过多、分片过多,会造成集群元数据和协调开销增加。
- 按时间拆索引后,分片数量也要随数据量调整。
如果日数据量不大,日索引加过多主分片反而会拖慢查询。亿级轨迹数据查询慢时,需要同时看单索引大小、分片大小、分片数量和节点资源。
步骤八:地图查询优先返回聚合或抽稀结果
WebGIS 地图展示不应直接加载海量原始轨迹点。当前端只是需要看分布,可以用网格聚合、瓦片聚合或后端抽稀。
例如做空间分布统计时,可以使用 ES 的地理网格聚合能力:
GET trajectory-2025.01.10/_search
{
"size": 0,
"query": {
"bool": {
"filter": [
{
"range": {
"timestamp": {
"gte": "2025-01-10T00:00:00Z",
"lte": "2025-01-10T23:59:59Z"
}
}
},
{
"geo_bounding_box": {
"loc": {
"top_left": {
"lat": 31.35,
"lon": 121.30
},
"bottom_right": {
"lat": 31.10,
"lon": 121.70
}
}
}
}
]
}
},
"aggs": {
"grid": {
"geotile_grid": {
"field": "loc",
"precision": 12
}
}
}
}这种方式适合热力图、点密度图、区域概览。真正需要轨迹线时,再按对象 ID 和时间范围请求详细数据。
常见坑:ES 优化轨迹数据时容易踩的问题
坑一:把经纬度存成字符串
经纬度如果存成字符串,ES 无法高效执行空间查询。应使用 geo_point,并保证坐标顺序正确。GeoJSON 常用顺序是经度、纬度,而 geo_point 对象写法通常是 lat 和 lon。
坑二:查询时间范围过大
用户在页面上选择“一年轨迹”,后端直接查一年原始点,这是非常危险的。应在接口层限制最大查询范围,或者改为异步任务、离线导出、分段加载。
坑三:地图缩放级别很低仍返回原始点
全国或全省范围下返回所有轨迹点没有意义。低缩放级别应返回聚合结果,高缩放级别再返回局部明细点。
坑四:只优化 ES,不优化应用层
有时 ES 查询只需 300 毫秒,但接口总耗时 5 秒,原因可能是应用层对象转换、JSON 序列化、网络传输或前端渲染过慢。排查时要分段记录耗时。
坑五:排序字段和分页方式不合理
轨迹查询通常按时间排序。如果深分页使用很大的 from,性能会明显下降。大量滚动读取或导出任务应考虑 search_after 或异步批处理,而不是普通分页接口。
方法比较:ES、PostGIS、时序数据库如何选择
轨迹数据不一定全部都适合放在 ES 中。不同工具适合不同任务。
| 方案 | 适合场景 | 不适合场景 |
|---|---|---|
| Elasticsearch | 海量点过滤、时间空间检索、近实时查询、地图概览 | 复杂拓扑分析、严格事务、多表空间关系计算 |
| PostGIS | 空间关系分析、缓冲区、叠加分析、轨迹线处理、SQL分析 | 超高并发日志式检索、海量实时写入压力较大时 |
| 时序数据库 | 设备时序指标、连续时间窗口统计、监控类数据 | 复杂 GIS 空间查询能力通常有限 |
| 对象存储加离线计算 | 历史轨迹归档、离线分析、批量导出 | 实时交互式地图查询 |
比较稳妥的架构是:近期高频查询轨迹放 ES,复杂空间分析放 PostGIS,历史低频数据归档到对象存储或数据湖。不要把 ES 当成所有 GIS 分析的唯一数据库。
检查清单:排查亿级轨迹数据查询慢
可以按下面清单逐项检查:
- 是否按时间拆分索引,而不是所有轨迹点写入一个大索引?
device_id是否为keyword类型?timestamp是否为date类型?- 经纬度是否使用
geo_point? - 查询是否使用
bool.filter,避免不必要评分? - 查询是否准确命中少量时间索引,而不是通配全量索引?
- 是否限制了最大时间范围和最大返回数量?
- 地图展示是否使用聚合、抽稀或分级加载?
- 是否使用慢查询日志和 profile 定位瓶颈?
- 分片数量是否符合当前数据量和节点规模?
- 热点设备是否造成 routing 或分片倾斜?
- 前端是否一次渲染过多点或轨迹线?
经验上,ES 性能优化最有效的做法往往不是某个高级参数,而是减少查询扫描范围、减少返回数据量、减少无意义的实时计算。
FAQ:亿级轨迹数据 ES 性能优化常见问题
ES 适合存亿级轨迹数据吗?
适合做轨迹点的快速过滤、时间范围查询、空间范围查询和近实时检索。但如果要做复杂空间叠加、拓扑关系、路径网络分析,PostGIS 或专业空间计算框架通常更合适。
亿级轨迹数据查询慢,先加机器有用吗?
可能有用,但不是第一优先级。如果索引没有按时间拆分、查询总是扫全量索引、前端一次请求几十万点,加机器只能暂时缓解。应先优化索引设计和查询方式。
轨迹查询应该用 geo_point 还是 geo_shape?
单个轨迹点建议使用 geo_point。如果存储的是区域、多边形或复杂线面对象,才考虑 geo_shape。轨迹点检索场景使用 geo_point 更直接。
按车辆 ID 查询轨迹很慢怎么办?
先确认 device_id 是否为 keyword,查询是否限定时间索引,是否按时间过滤,返回点数是否过大。如果单对象查询非常高频,可以评估 routing,但要注意数据倾斜。
WebGIS 地图上展示轨迹点应该返回多少数据?
没有固定数字,但原则是不要让前端一次渲染不可控的海量点。低缩放级别返回聚合结果,高缩放级别返回局部明细;轨迹回放可以按时间窗口分段加载。
ES 能不能直接替代 PostGIS 做轨迹分析?
不建议完全替代。ES 更适合检索和过滤,PostGIS 更适合空间分析和关系计算。实际项目中经常是 ES 承担在线查询,PostGIS 承担精确空间分析。
结论:优化 ES 轨迹查询要从数据模型开始
“亿级轨迹数据查询慢?ES性能如何优化?”的核心答案是:先减少查询扫描范围,再控制返回数据量,最后再调整集群资源和参数。对于 GIS 轨迹场景,按时间拆索引、正确 mapping、使用 geo_point、采用 bool.filter、限制查询范围、地图端聚合抽稀,是最值得优先落地的优化方向。
如果你的系统已经出现亿级轨迹数据查询慢,不要只盯着 ES CPU 和内存。建议从一次真实慢查询出发,沿着“索引范围、过滤条件、分片扫描、排序分页、返回字段、前端渲染”这条链路逐段排查,通常能更快找到真正瓶颈。