ArcGIS热点分析怎么做?空间关系概念化和结果解释
做犯罪点、投诉点、病虫害点、门店销售额或事故数量分析时,很多人会直接打开符号系统做“热力图”。但如果项目需要判断哪里是真正显著的高值聚集区,就应该使用 ArcGIS热点分析。它不是简单把点画得更红,而是用统计检验回答一个问题:某个位置附近的高值或低值聚集,是否强到不太可能由随机分布造成。
本文围绕操作流程、空间关系选择和结果解读三个常见问题,给出一套适合 ArcGIS Pro 和 ArcMap 思路迁移的实操流程。重点不是背工具参数,而是把分析单元、分析字段、距离阈值和结果字段解释清楚。
问题背景:热点分析解决的不是普通制图问题
这类工具常用于寻找高值聚集和低值聚集。例如城市管理投诉是否集中在某些街区,交通事故是否沿特定道路片区聚集,疾病病例是否在某些网格内显著偏高,或者销售额较低的门店是否成片分布。它适合回答“空间聚集是否显著”,不适合只回答“哪里看起来颜色更深”。
很多错误结果来自一开始的问题定义不清。点事件多,不代表热点一定显著;某个行政区数值高,也不代表它周边形成高值聚集。热点分析看的是每个要素和它邻近要素组成的局部统计关系。如果只把原始点直接丢进工具,或者把人口规模不同的行政区直接用总量比较,结果很容易被采样密度、行政区大小和人口基数误导。
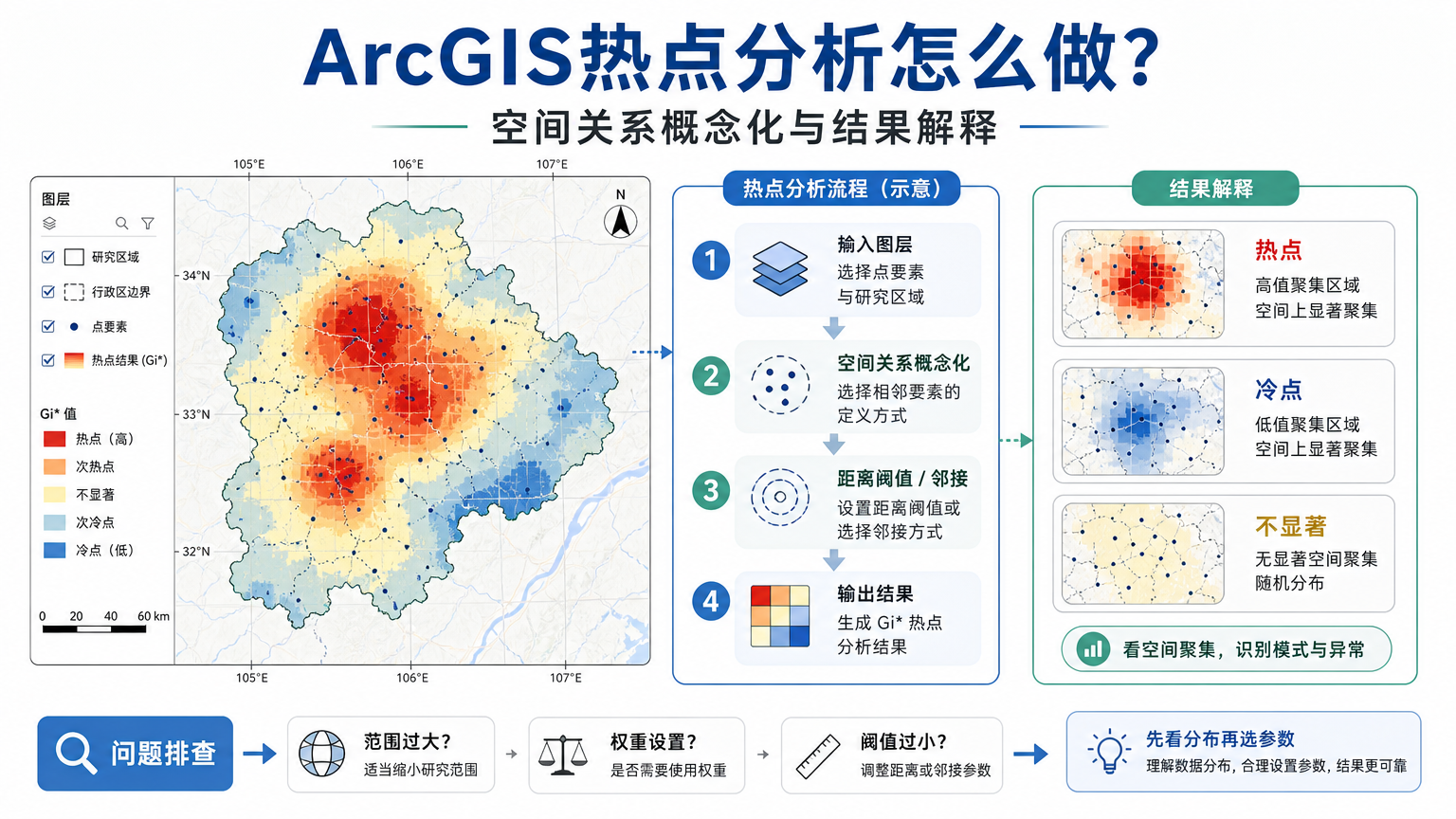
因此,做热点分析之前要先确定三件事:分析对象是点还是面,分析指标是总量还是比率,空间邻近关系按距离、邻接还是自定义权重来定义。只有这三项合理,后面的统计结果才有解释价值。
核心原理:热点分析看的是局部高低值聚集
常用工具是 Hot Spot Analysis (Getis-Ord Gi*)。它会对每个要素计算一个局部统计量,把该要素及其邻近要素的值与全局平均水平进行比较。如果某个要素周围都是较高值,并且这种聚集达到统计显著性,就会被识别为热点;如果周围都是较低值,并且显著低于整体水平,就会被识别为冷点。
这里有一个关键点:单个要素的值很高,不等于它一定是热点。热点要求高值周围还有高值,并且这种局部聚集不是随机噪声。相反,一个值很高但周边都很低的孤立异常点,可能是值得调查的异常值,但未必会成为热点。
- 分析字段:用于计算热点的数值字段,例如事故数量、投诉率、病例率、销售额、污染浓度。
- 邻近关系:决定哪些要素会被当作某个要素的邻居,例如一定距离内、相邻面、共享边界或自定义权重。
- 显著性:通过 z 值和 p 值判断局部高低值聚集是否足够强。
- 结果分级:通常通过 Gi_Bin 字段表达热点、冷点和不显著区域。
实务判断可以这样读:热点不是“这个地方值最大”,而是“这个地方及其邻近范围共同形成了显著高值聚集”。
ArcGIS热点分析怎么做:从数据准备到工具运行
如果你搜索的是“ArcGIS热点分析怎么做”,建议不要从工具按钮开始,而是按数据准备、分析单元、字段设置、空间关系和结果检查五步走。下面的流程更适合项目复现,也方便排错。
- 明确业务问题。先写清楚要找的是高值聚集、低值聚集,还是事件密集区。例如“识别 2025 年交通事故数量显著偏高的街区”,比“做一张事故热点图”更可分析。
- 检查输入数据。删除空几何、重复点、明显错误坐标和无效字段值。点数据要检查是否存在大量完全重叠点,面数据要检查是否有拓扑错误或异常大面。
- 使用合适的投影坐标系。热点分析涉及距离和邻域关系,正式计算前建议把数据投影到适合研究区的投影坐标系,不要依赖地理坐标系下的经纬度距离。
- 确定分析单元。事件点可以先聚合到行政区、规则网格、六边形网格或道路分段;面数据则要确认每个面代表相同或可比较的统计单元。
- 准备分析字段。字段应是数值型。人口、面积或门店数量差异很大时,优先使用标准化后的比率或密度,而不是直接使用总量。
- 打开热点分析工具。在 Spatial Statistics Tools 的 Mapping Clusters 工具组中使用 Hot Spot Analysis (Getis-Ord Gi*),设置 Input Features、Analysis Field 和 Output Feature Class。
- 设置空间关系概念化。根据数据类型和业务尺度选择距离带、邻接关系或空间权重文件。不要只保留默认值后直接出图。
- 运行并检查输出。查看输出图层中的 Gi_Bin、GiZScore、GiPValue 等字段,确认热点、冷点和不显著区域是否符合数据背景。
点事件很多时,不建议把每个原始事件点都当成一个独立分析要素。更稳的做法是先用网格、六边形或行政区统计每个单元内的事件数量,再对这些单元做统计热点识别。这样每个要素都有可比较的数值字段,结果也更适合解释和制图。
ArcGIS热点分析空间关系的概念化怎么选择
ArcGIS热点分析空间关系的概念化怎么选择,本质上是在回答“谁是某个要素的邻居”。这个参数会直接影响热点边界、显著性和结论范围。相同的数据,用不同空间关系可能得到不同热点图,所以它不能随便选。
| 空间关系概念化 | 适合数据 | 选择建议 |
|---|---|---|
| 固定距离带 | 点、网格、规则采样点、同尺度面中心点 | 最常用。适合有明确作用距离的场景,例如 500 米服务范围、1 公里事故影响范围。要保证大多数要素都有邻居。 |
| 反距离或反距离平方 | 距离衰减明显的连续空间现象 | 近邻权重更高,远邻影响更弱。适合污染、房价、可达性等随距离衰减的问题,但对孤立点和尺度选择敏感。 |
| 无差别区 | 阈值内影响相近、阈值外逐渐衰减的现象 | 适合“近距离内都算强影响,超过阈值后影响减弱”的场景,例如社区服务半径或设施吸引范围。 |
| 邻接边 | 行政区、街区、规则面单元 | 只把共享边界的面看作邻居。适合县区、街道、地块等面状统计单元,结果解释直观。 |
| 邻接边和角 | 规则网格、六边形以外的紧密面单元 | 共享边或共享角点都算邻居。适合格网分析,但在不规则行政区中可能让斜角接触的区域被过度连接。 |
| 从空间权重文件获取 | 网络距离、K 近邻、自定义业务关系 | 适合道路网络、河流上下游、商圈等级或跨区域联系等普通欧氏距离无法表达的关系。 |
如果没有明确业务距离,常见做法是先探索距离尺度。可以从平均最近邻距离、增量空间自相关结果、研究区业务半径或采样间距中选择候选距离,再比较输出结果是否稳定。不要为了得到“更好看”的热点而反复调距离,距离阈值应能被业务逻辑解释。
对面数据来说,如果分析单元是行政区、街道或地块,邻接关系通常比固定距离更容易解释。对规则网格或六边形,固定距离带和邻接关系都可以用,但需要保持整个研究区的邻居数量不要过于失衡。对点数据或点聚合后的网格,固定距离带通常是最容易复现的选择。
距离阈值怎么定:不要让孤立要素破坏结果
空间关系选定后,距离阈值仍然很关键。距离太小,很多要素没有足够邻居,结果会碎片化,显著性不稳定;距离太大,局部差异被全局平均稀释,热点范围会变得过宽。一个合理的阈值应当让每个要素都有一定数量的邻居,同时又不把相距很远的区域硬连在一起。
可以按下面顺序确定距离阈值。
- 先看业务尺度。例如居民步行投诉影响范围可能是 500 米,县域产业集聚可能是几十公里,道路事故可能更适合沿道路分段而不是直线距离。
- 再看数据间距。统计最近邻距离、网格边长或行政区平均尺度,避免阈值明显小于数据间距。
- 检查邻居数量。输出结果中如果大量要素邻居数过少,要重新考虑距离带或聚合单元。
- 做敏感性比较。用两个或三个有业务意义的距离运行,对比核心热点是否稳定,而不是只看某一次结果。
如果研究区边界很不规则,边缘要素天然邻居较少,需要在解释时说明边界效应。不要把边界上的不显著结果简单解释为“没有问题”,它也可能只是邻域信息不足。
ArcGIS热点分析结果解释:Gi_Bin、z 值和 p 值
ArcGIS热点分析结果解释不能只看颜色。输出图层通常会包含 GiZScore、GiPValue 和 Gi_Bin 等字段。它们共同说明某个要素附近的高值或低值聚集是否显著,以及显著程度有多高。
| 字段或结果 | 含义 | 解释方法 |
|---|---|---|
| GiZScore | 局部高低值聚集的标准化统计量 | 正值越大,越倾向高值聚集;负值越小,越倾向低值聚集。 |
| GiPValue | 显著性概率 | 值越小,说明当前聚集由随机过程产生的可能性越低。 |
| Gi_Bin | 热点和冷点显著性分级 | 正数表示热点,负数表示冷点,0 通常表示不显著。 |
| 热点 | 高值要素及其高值邻居形成显著聚集 | 适合标注为高风险、高需求、高强度或高关注区域,但要结合业务字段解释。 |
| 冷点 | 低值要素及其低值邻居形成显著聚集 | 适合解释为低风险、低需求、低强度或低发生区域,也可能代表数据采集不足。 |
Gi_Bin 为 3、2、1 时,通常表示不同置信水平下的热点;Gi_Bin 为 -3、-2、-1 时,通常表示不同置信水平下的冷点;Gi_Bin 为 0 表示未达到显著性要求。写报告时不要只写“红色区域是热点”,而应说明分析字段、分析单元、空间关系、距离阈值和显著性等级。
例如,可以这样解释:以 1 公里固定距离带定义邻域、以街区事故率为分析字段时,中心城区若干街区形成 95% 置信水平以上的事故热点,说明这些街区及其邻近街区的事故率共同高于全市随机分布预期。这个解释比“中心城区事故多”更严谨。
常见坑点:热点分析结果看起来漂亮但不能直接下结论
- 把热力图当成热点分析。热力图是可视化密度表达,热点分析工具做的是统计显著性检验。两者可以互相参考,但不能等同。
- 用总量比较不同规模区域。人口越多、面积越大或门店越多的区域,总量往往更高。需要时应改用人均值、发生率、密度或标准化指标。
- 原始事件点没有聚合。每个点都只有一个事件时,直接分析可能无法表达事件强度。先聚合到网格或面单元通常更稳。
- 空间关系没有业务解释。固定距离、邻接关系和权重文件代表不同的邻居定义。无法解释邻居定义,就很难解释结果。
- 坐标系不适合距离计算。经纬度坐标下直接设置米或公里尺度,容易造成距离解释混乱。应先投影到合适的平面坐标系。
- 忽略多重检验和显著性含义。结果显著不代表因果关系成立,只说明局部空间聚集强于随机预期。
- 只截取热点区域汇报。冷点、不显著区域、边界区域和异常值同样需要说明,否则报告容易偏向结论。
工具对比:Hot Spot Analysis、Optimized Hot Spot Analysis 和热力图怎么选
ArcGIS 中与热点相关的工具和制图方式不少,但适用目标不同。选择工具时,先判断你要的是统计检验、自动化探索,还是只是做一张密度可视化图。
| 方法 | 适合场景 | 注意事项 |
|---|---|---|
| Hot Spot Analysis (Getis-Ord Gi*) | 已经有明确分析字段、分析单元和空间关系,需要可解释的统计热点结果 | 参数可控,但要求你理解空间关系概念化、距离阈值和结果字段。 |
| Optimized Hot Spot Analysis | 初步探索事件点或面数据,希望工具辅助选择部分参数 | 适合快速探索,但正式报告仍要说明工具如何聚合数据、如何确定尺度。 |
| Kernel Density 或热力图符号 | 展示事件密度、发现大致分布趋势、做制图表达 | 不是显著性检验,不能直接写成统计意义上的热点。 |
| Cluster and Outlier Analysis | 同时关注高值聚集、低值聚集和空间异常值 | 适合识别高值被低值包围、低值被高值包围等异常格局。 |
新手可以先用 Optimized Hot Spot Analysis 做探索,理解数据是否存在明显聚集,再用 Hot Spot Analysis (Getis-Ord Gi*) 按项目要求明确设置分析字段、空间关系和距离阈值。正式成果中,建议优先交付参数可复现的热点分析结果。
实践检查清单:提交热点分析成果前看这 10 项
- 研究问题是否明确到“什么指标在哪个空间单元上发生显著聚集”。
- 输入数据是否清理了空几何、重复点、异常坐标和缺失值。
- 是否使用适合研究区的投影坐标系。
- 点事件是否已经按网格、行政区、六边形或业务单元合理聚合。
- 分析字段是否为数值型,并且能代表业务强度。
- 总量字段是否需要转换为比率、密度或标准化指标。
- 空间关系概念化是否能用业务逻辑解释。
- 距离阈值是否保证大多数要素有足够邻居。
- 是否检查了 Gi_Bin、GiZScore、GiPValue,而不是只看默认配色。
- 报告中是否说明分析字段、邻近关系、距离阈值、显著性等级和限制条件。
FAQ:操作、空间关系和结果解释
ArcGIS热点分析怎么做才算完整?
完整流程应包括数据清理、投影坐标系检查、确定分析单元、准备数值型分析字段、选择空间关系概念化、设置距离阈值、运行 Hot Spot Analysis (Getis-Ord Gi*),最后解释 Gi_Bin、z 值和 p 值。只打开工具运行一次,不说明这些参数,不能算完整的分析成果。
ArcGIS热点分析空间关系的概念化怎么选择最稳?
如果是点或规则网格,固定距离带通常最容易解释;如果是行政区或街道面,邻接边或邻接边和角更直观;如果研究对象沿道路、河流或业务联系传播,可以考虑空间权重文件。核心是让邻居定义符合数据生成机制,而不是追求某种固定选项。
ArcGIS热点分析结果解释时,Gi_Bin 等于 0 是什么意思?
Gi_Bin 等于 0 通常表示该要素及其邻近范围没有形成统计显著的热点或冷点。它不是“没有数据”,也不是“一定没有问题”,而是在当前分析字段、空间关系和距离阈值下,局部聚集没有达到显著性要求。
结果解读可以只看红色和蓝色吗?
不建议。红色和蓝色只是符号化结果。严谨的结果解读应同时说明 GiZScore、GiPValue、Gi_Bin、分析字段、空间关系和距离阈值。尤其在写报告时,要把“显著高值聚集”和“值很高”区分开。
点数据可以直接做热点分析吗?
可以,但要看点数据含义。如果每个点都有一个可分析的数值字段,例如门店销售额或监测浓度,可以直接分析。如果每个点只是一次事件记录,例如一起事故或一次投诉,通常应先聚合到网格、行政区或其他统计单元,再用事件数量、发生率或密度做分析字段。
热点分析和核密度分析有什么区别?
核密度分析主要生成平滑的密度表面,用于表达事件哪里密集;热点分析则对局部高低值聚集做统计显著性检验。项目中可以先用核密度看大致趋势,再判断哪些区域是真正显著的高值或低值聚集。
为什么换一个距离阈值后热点范围变了?
因为距离阈值改变了每个要素的邻居集合。邻居变了,局部统计量也会变。出现这种情况并不一定说明工具错误,而是说明热点结果对空间尺度敏感。正式成果应选择有业务依据的距离,并说明结果在该尺度下成立。
总结
这类分析的关键不是把图做红,而是把统计问题定义清楚。先明确分析单元和分析字段,再选择能解释的空间关系概念化,最后用 Gi_Bin、z 值和 p 值解释热点、冷点和不显著区域。把操作流程、邻居定义和显著性结果连起来,热点图才真正能服务项目判断,而不是只停留在漂亮的制图效果上。