PostGIS空间查询慢?空间索引和ST_Intersects排查
PostGIS空间查询慢?先查空间索引和 ST_Intersects
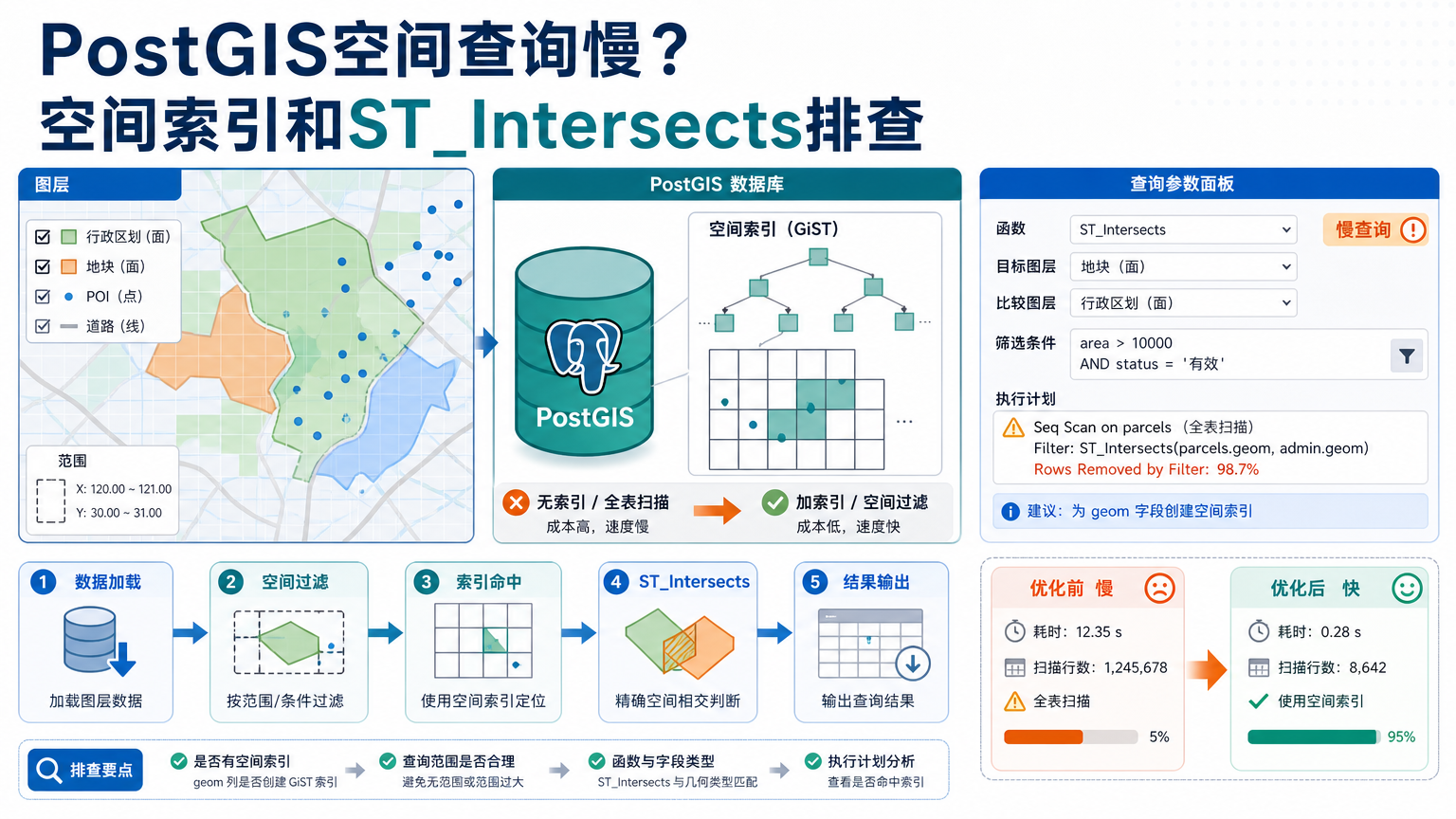
做地块叠加道路、POI 落行政区、管线穿越保护区、网格匹配监测点时,PostGIS空间查询一慢,很多人会先怀疑数据库性能不够。实际项目里,更常见的原因是空间索引没有生效、查询条件写法让索引用不上,或者 ST_Intersects 面对过大的候选集做了太多精确几何判断。
本文按 Dr.GIS 的排查习惯,把 PostGIS查询慢 拆成可验证的几步:先确认数据和索引,再看执行计划,最后改写 SQL。不要一开始就调数据库参数,先证明慢在哪里。
问题背景:PostGIS查询慢通常慢在什么地方
PostGIS空间查询慢,不一定表现为数据库完全卡死。常见现象包括:一条叠加查询运行几分钟没有结果,QGIS 连接 PostGIS 图层时地图缩放很卡,WebGIS 后端接口因为空间过滤超时,或者同样的数据在小范围内很快,全市、全省范围一查就慢。
这些问题背后通常有三类原因。第一,空间表没有可用的 PostGIS空间索引,数据库只能逐行扫描几何字段。第二,虽然建了索引,但 SQL 写法让优化器很难使用它。第三,索引已经筛掉一部分数据,但进入 ST_Intersects 的候选几何仍然太多,精确拓扑判断成本过高。
因此,排查 PostGIS查询慢 不要只问“要不要加内存”。更应该问:当前查询读了多少行?有没有走 GiST 索引?候选范围是否先被属性条件、空间范围和边界框过滤缩小?
核心原理:PostGIS空间索引不是直接替你算相交
PostGIS空间索引常用 GiST 索引。它主要存储几何对象的外包矩形,也就是 bounding box。查询时,数据库可以先用外包矩形快速筛出可能相交的候选对象,再交给 ST_Intersects 做更精确的几何关系判断。
这意味着空间索引解决的是“先少看一些对象”,不是把所有空间关系判断都变成零成本。一个很大的行政区面、一个复杂岸线面、一个跨城道路缓冲区,即使经过索引过滤,仍可能和大量候选对象发生外包矩形重叠。候选集越大,精确判断越慢。
理解 PostGIS 性能时,要把空间查询拆成两段:索引先做粗过滤,空间函数再做精确判断。慢查询往往不是单个函数的问题,而是进入精确判断的数据太多。
ST_Intersects 在常规写法中会利用可用的空间索引做边界框预筛选,但前提是索引存在、统计信息可靠、几何表达式能被优化器识别,并且查询条件足够明确。
第一步:确认空间字段、SRID 和基础数据质量
在优化 SQL 之前,先确认空间表本身没有基础问题。很多慢查询其实混着坐标系错误、空几何、无效面、过大的多部件几何和错误字段名。
SELECT
ST_SRID(geom) AS srid,
GeometryType(geom) AS geom_type,
COUNT(*) AS row_count
FROM public.parcels
GROUP BY ST_SRID(geom), GeometryType(geom)
ORDER BY row_count DESC;如果一张表里混有多个 SRID,或者有些数据 SRID 是 0,后续空间叠加就很容易出现结果异常和查询写法混乱。再检查空几何和无效几何:
SELECT
COUNT(*) AS total_rows,
COUNT(*) FILTER (WHERE geom IS NULL) AS null_geom_rows,
COUNT(*) FILTER (WHERE geom IS NOT NULL AND NOT ST_IsValid(geom)) AS invalid_geom_rows
FROM public.parcels;无效几何不一定让所有查询失败,但会增加排查难度。生产库里不要直接批量修复原表,建议先复制样本或在加工表中测试 ST_MakeValid,确认修复后的面类型、面积和业务含义没有被破坏。
第二步:检查空间索引是否存在并更新统计信息
确认空间表有可用索引,是排查 PostGIS空间查询 的基本动作。不要只看“以前好像建过”,直接查系统目录。
SELECT
schemaname,
tablename,
indexname,
indexdef
FROM pg_indexes
WHERE schemaname = 'public'
AND tablename IN ('parcels', 'roads')
ORDER BY tablename, indexname;如果 geom 字段没有 GiST 索引,可以在维护窗口创建索引。数据量较大、业务库不能长时间锁表时,要评估是否使用并发建索引。
CREATE INDEX parcels_geom_gix
ON public.parcels
USING GIST (geom);
CREATE INDEX roads_geom_gix
ON public.roads
USING GIST (geom);
ANALYZE public.parcels;
ANALYZE public.roads;建完索引后要执行 ANALYZE,让 PostgreSQL 更新统计信息。统计信息过旧时,优化器可能低估或高估候选行数,导致本该使用索引的查询走了顺序扫描。
第三步:用 EXPLAIN 看 PostGIS ST_Intersects 有没有走索引
优化 PostGIS ST_Intersects 查询,不能靠感觉。先在测试环境或小范围条件下查看执行计划。EXPLAIN 只展示计划,EXPLAIN ANALYZE 会实际运行 SQL,生产库上要谨慎使用。
EXPLAIN (ANALYZE, BUFFERS)
SELECT
p.id AS parcel_id,
r.id AS road_id
FROM public.parcels AS p
JOIN public.roads AS r
ON ST_Intersects(p.geom, r.geom)
WHERE p.city_code = '330100'
AND r.road_level = '主干路';看执行计划时,重点关注几件事:是否出现 Index Scan、Bitmap Index Scan,是否对空间表做了大范围 Seq Scan,实际行数和估计行数差距是否很大,Buffers 读了多少数据页。
如果属性条件可以明显缩小范围,却没有对应普通 B-tree 索引,也会拖慢空间查询。空间索引只负责几何过滤,城市代码、道路等级、数据版本、状态字段这些高频过滤条件,也需要按实际查询模式建立普通索引。
第四步:给 ST_Intersects 加明确的候选集过滤
很多 PostGIS空间查询 慢,是因为一开始就让两张大表互相做空间连接。更稳妥的写法是先用属性条件、空间范围和边界框过滤缩小候选集,再进入精确相交判断。
SELECT
p.id AS parcel_id,
r.id AS road_id
FROM public.parcels AS p
JOIN public.roads AS r
ON p.geom && r.geom
AND ST_Intersects(p.geom, r.geom)
WHERE p.city_code = '330100'
AND r.road_level = '主干路'
AND p.status = '有效';&& 是外包矩形相交操作符,用来表达边界框预筛选。虽然 ST_Intersects 通常会自动包含这类预筛选,显式写出它可以帮助你在排查时更清楚地表达“先粗过滤,再精确判断”的意图,也便于观察执行计划。
如果查询来自 WebGIS 接口,通常还应该带上当前视图范围,而不是每次都查全库:
SELECT
id,
name
FROM public.parcels
WHERE geom && ST_MakeEnvelope(120.10, 30.10, 120.30, 30.30, 4326)
AND ST_Intersects(
geom,
ST_MakeEnvelope(120.10, 30.10, 120.30, 30.30, 4326)
);这里的坐标只是写法示例。真实项目中,视图范围的 SRID 必须与表中 geom 的 SRID 一致,或者先在外部统一坐标系,避免在大表字段上反复做转换。
第五步:避免在空间字段外面包函数
一个常见错误,是在查询条件里直接对表字段写 ST_Transform、ST_Buffer、ST_Simplify 等函数。这样做可能让已有索引很难发挥作用,尤其是函数作用在大表的 geom 字段上时。
SELECT id
FROM public.parcels
WHERE ST_Intersects(
ST_Transform(geom, 3857),
ST_Transform(ST_GeomFromText('POLYGON((...))', 4326), 3857)
);上面这种写法在排查阶段要警惕。更推荐的思路是:把查询几何转换到数据表的 SRID,再和原始 geom 查询;或者为长期固定的投影表达式建立函数索引;再或者在 ETL 阶段生成投影后的加工表。
WITH query_area AS (
SELECT ST_Transform(
ST_GeomFromText('POLYGON((...))', 4326),
4549
) AS geom
)
SELECT p.id
FROM public.parcels AS p
JOIN query_area AS q
ON p.geom && q.geom
AND ST_Intersects(p.geom, q.geom);原则很简单:尽量不要让数据库对大表每一行临时计算新几何,再做空间判断。能提前处理的坐标转换、缓冲区生成和几何简化,尽量前置到参数、临时表或加工表。
第六步:大面和复杂几何要考虑 ST_Subdivide
如果一个行政区、流域、生态红线或海岸线面特别大、特别复杂,它的外包矩形可能覆盖大量对象。此时即使有索引,候选集仍然很大。对这类数据,可以把大面切成较小片段后再查询。
CREATE TABLE public.districts_sub AS
SELECT
id,
(ST_Dump(ST_Subdivide(geom, 256))).geom AS geom
FROM public.districts;
CREATE INDEX districts_sub_geom_gix
ON public.districts_sub
USING GIST (geom);
ANALYZE public.districts_sub;切分后,空间索引能用更小的外包矩形过滤候选对象,减少进入 ST_Intersects 的几何数量。这个方法适合读多写少、经常被拿来做叠加的边界类数据。
需要注意,切分表只是查询加速结构,不应随意替代原始业务边界。最终统计时可能需要按原始 id 汇总,避免同一对象因为跨多个切片而重复计数。
常见坑点:这些写法会让 PostGIS空间查询变慢
- 只给主键建索引,没有给 geom 建 GiST 索引。普通主键索引不能替代空间索引。
- 建了索引但没有更新统计信息。大量导入、删除、更新后,应对相关表执行
ANALYZE。 - 在大表 geom 上直接套 ST_Transform。优先转换查询参数,或使用加工表、函数索引。
- 用 ST_Intersects 做距离查询。“附近 500 米”更适合
ST_DWithin,不要先生成大量 buffer 再相交。 - 两张大表直接全量空间连接。先加城市、类型、状态、时间版本、视图范围等过滤条件。
- 复杂大面没有切分。行政边界、流域边界、海岸线和保护区面可以考虑
ST_Subdivide加速候选过滤。 - 输出字段太多。接口查询不要
SELECT *,只返回业务需要的字段。 - 把慢全部归因于数据库。有时慢在网络传输、QGIS 渲染、GeoJSON 序列化或前端加载,而不是 SQL 本身。
方法对比:ST_Intersects、边界框、ST_DWithin 怎么选
不同空间函数解决的问题不同。选错函数,既可能结果不准,也可能让查询变慢。
| 方法 | 适合场景 | 排查重点 |
|---|---|---|
ST_Intersects |
判断点线面是否相交、落入、穿越或有接触关系 | 确认空间索引、候选集大小、几何复杂度和 SRID |
&& 边界框过滤 |
先粗筛可能相交的对象,配合精确空间函数使用 | 只能说明外包矩形相交,不能替代精确空间关系 |
ST_DWithin |
查询一定距离范围内的对象,如道路 500 米范围内地块 | 确认距离单位和投影坐标系,不要混用经纬度度数和米 |
ST_Contains / ST_Within |
严格包含、落入关系,例如点是否在行政区内部 | 边界点可能与业务直觉不同,需要和 ST_Intersects 对比测试 |
ST_Subdivide 加工表 |
复杂大面被反复用于空间叠加和范围过滤 | 注意后续按原始对象 ID 汇总,避免切片造成重复统计 |
对于多数业务系统,推荐先用 ST_Intersects 表达真实空间关系,再通过索引、过滤条件和数据加工来降低候选量。不要为了速度把精确判断全部替换成边界框判断,否则会得到误匹配。
实用排查清单:从慢 SQL 到可复现优化
- 记录原始 SQL。保留完整查询、参数、表名、过滤条件和调用来源,避免只凭口头描述排查。
- 确认数据范围。检查行数、SRID、几何类型、空几何、无效几何和大面复杂度。
- 检查索引。确认空间字段有 GiST 索引,高频属性过滤字段有合适的普通索引。
- 更新统计信息。导入或大批量更新后执行
ANALYZE,再看执行计划。 - 查看执行计划。用
EXPLAIN或测试环境中的EXPLAIN ANALYZE判断是否走索引、是否读了过多数据页。 - 缩小候选集。增加城市、分类、状态、时间、视图范围、边界框等过滤条件。
- 改写函数位置。避免在大表
geom上临时套转换、缓冲、简化函数。 - 处理复杂大面。反复查询的大边界可以建立切分后的查询表,并保留原始 ID。
- 验证结果正确性。优化后抽样对比数量、空间位置和业务字段,防止为了速度牺牲空间关系。
FAQ:PostGIS空间查询、空间索引和 ST_Intersects 常见问题
PostGIS空间查询一定要手写 && 吗?
不一定。ST_Intersects 在常规情况下会包含边界框预筛选,并可使用可用空间索引。排查慢 SQL 时显式写 &&,主要是为了让候选集过滤更直观,也方便阅读执行计划。最终是否保留,要结合实际计划和结果正确性判断。
PostGIS空间索引已经建了,为什么查询还是慢?
空间索引只能减少候选对象,不会消除所有几何计算。如果查询范围太大、两张表都是全量连接、几何特别复杂、统计信息过旧,或者 SQL 在 geom 外面包了函数,查询仍然会慢。此时应看执行计划,而不是重复建同一个索引。
PostGIS查询慢是不是 ST_Intersects 本身的问题?
多数情况下不是。查询变慢更常见的原因是进入 ST_Intersects 的候选行太多。先用属性条件、视图范围、边界框和空间索引缩小候选集,再判断函数本身是否仍然是瓶颈。
PostGIS ST_Intersects 和 ST_DWithin 应该怎么选?
PostGIS ST_Intersects适合判断几何是否相交、接触或落入。若业务问题是“距离某对象多少米以内”,优先考虑 ST_DWithin。距离查询还要确认坐标系单位,米制距离最好在合适的投影坐标系下处理。
能不能在 WHERE 条件里直接 ST_Transform(geom)?
可以写,但不一定适合性能敏感查询。频繁对大表字段执行 ST_Transform(geom),可能让原始 geom 上的索引难以发挥作用。更稳妥的做法是转换查询参数、使用统一 SRID 的加工表,或为固定表达式建立经过验证的函数索引。
结论:先证明索引和候选集,再优化 PostGIS空间查询
PostGIS空间查询慢时,最有效的处理方式不是盲目加配置,而是按证据排查。先确认 SRID、几何质量和索引,再用执行计划判断是否走索引,最后通过过滤条件、边界框、大面切分和 SQL 改写减少候选集。
如果记住一句话,就是:空间索引负责粗筛,ST_Intersects负责精确判断。让粗筛尽量有效,让精确判断面对更少、更干净的几何对象,PostGIS 的空间查询性能才会稳定下来。