ndvi归一化植被指数详解(定义、计算公式、优缺点)
本文围绕“ndvi归一化植被指数详解(定义、计算公式、优缺点)”展开,面向 GIS 学生、遥感入门用户和空间数据分析人员,重点讲清楚 NDVI 是什么、怎么计算、结果如何解释,以及在实际项目中容易踩哪些坑。
引言:为什么 GIS 分析中经常使用 NDVI归一化植被指数
NDVI归一化植被指数是遥感和 GIS 中最常见的植被监测指标之一。无论是农作物长势评估、林地覆盖变化、城市绿地分析,还是生态环境监测,NDVI 都经常作为第一步分析结果。
很多初学者的问题不是不会点击软件按钮,而是不清楚 NDVI 的含义:为什么用红光和近红外波段计算?NDVI 值为什么在 -1 到 1 之间?NDVI 越高是否一定代表植被越好?如果不理解这些问题,后续在 QGIS、ArcGIS Pro、ENVI、Google Earth Engine 或 Python 中做分析时,很容易得到看似正确但解释错误的结果。
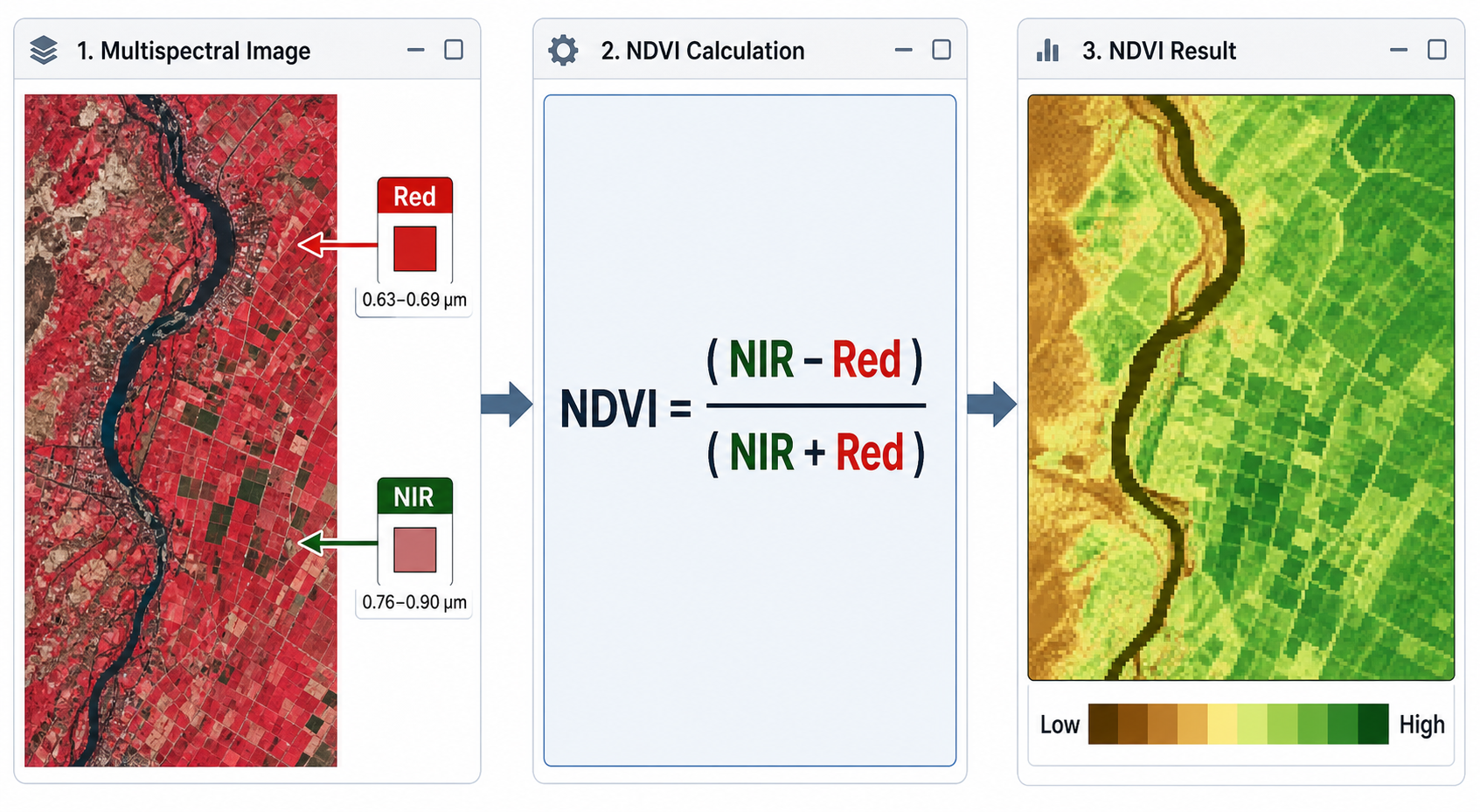
背景:NDVI 是什么,适合解决什么 GIS 问题
NDVI 的英文全称是 Normalized Difference Vegetation Index,中文通常译为归一化植被指数。它是一种基于多光谱遥感影像的植被指数,用于描述地表植被的相对活力和覆盖状况。
NDVI 的基本思想很简单:健康植被通常会强烈吸收红光,同时强烈反射近红外光。红光波段与近红外波段的差异越明显,通常说明该区域植被越茂盛。
在 GIS 实践中,NDVI归一化植被指数常用于以下场景:
- 农田作物长势监测,例如识别长势较弱的地块。
- 林地、草地、湿地等生态区域的植被覆盖分析。
- 城市绿化水平评价,例如比较不同街区或行政区的绿地状况。
- 灾害影响评估,例如火灾、干旱、病虫害前后的植被变化。
- 遥感分类前的辅助特征构建,例如将 NDVI 作为分类模型输入变量。
需要注意的是,NDVI 不是“植被面积”的直接等价物,也不是“产量”的直接等价物。它更适合表达植被相对状态,需要结合时间、区域、传感器和地面情况一起解释。
原理:NDVI计算公式为什么这样写
NDVI计算公式如下:
NDVI = (NIR - Red) / (NIR + Red)其中,NIR 表示近红外波段反射率,Red 表示红光波段反射率。
这个公式包含两个关键点:
- NIR – Red:突出植被对近红外强反射、对红光强吸收的差异。
- NIR + Red:对结果进行归一化,减少整体亮度差异、地形阴影和传感器增益差异带来的影响。
由于采用差值与和值的比值,NDVI值理论范围通常为 -1 到 1。常见解释可以参考下表:
| NDVI值范围 | 常见地物或状态 | 解释建议 |
|---|---|---|
| 小于 0 | 水体、云影、部分建筑阴影 | 通常不是健康植被,需要结合影像和地物判断。 |
| 0 到 0.2 | 裸地、建设用地、稀疏植被 | 植被覆盖较低,可能受土壤背景影响明显。 |
| 0.2 到 0.5 | 草地、农田、灌丛、一般植被 | 存在一定植被覆盖,可用于区域比较。 |
| 0.5 到 0.8 | 较茂盛植被、健康农作物、森林 | 通常表示植被状况较好。 |
| 接近 1 | 极高植被覆盖或非常强的近红外响应 | 需要检查是否存在饱和、传感器或预处理问题。 |
上表只是经验范围,不应直接作为所有地区、所有季节、所有传感器的固定判定标准。不同作物、不同生长期、不同影像来源的 NDVI值可能差异很大。
步骤:如何在 GIS 软件中计算 NDVI归一化植被指数
步骤一:确认影像是否包含红光和近红外波段
计算 NDVI 的前提是影像必须包含 Red 和 NIR 波段。常见卫星影像的波段对应关系如下:
| 数据源 | 红光波段 Red | 近红外波段 NIR | 说明 |
|---|---|---|---|
| Landsat 8/9 OLI | Band 4 | Band 5 | 常用于中分辨率长期变化分析。 |
| Sentinel-2 MSI | Band 4 | Band 8 | 10 米分辨率,适合农业和生态监测。 |
| GF 系列多光谱数据 | 需查元数据 | 需查元数据 | 不同传感器波段编号可能不同,不能凭经验套用。 |
| 无人机多光谱影像 | 需查相机说明 | 需查相机说明 | 必须确认相机是否包含近红外通道。 |
在实际工作中,最容易出错的是把波段编号记错。尤其是 Landsat 5/7、Landsat 8/9、Sentinel-2 的波段编号不同,计算前应先查看官方元数据或影像说明。
步骤二:优先使用地表反射率数据
NDVI计算公式理论上使用的是反射率,而不是原始 DN 值。DN 值是传感器记录的数字量,受太阳高度、传感器设置、大气条件影响较大。
如果只是做教学演示,使用 DN 值也能得到一个近似图层;但如果用于跨日期、跨区域或正式报告,建议使用经过辐射定标和大气校正的地表反射率产品。
常见建议如下:
- 使用 Landsat Collection 2 Surface Reflectance 产品。
- 使用 Sentinel-2 Level-2A 地表反射率产品。
- 如果只有 Level-1 数据,应先完成大气校正或说明误差来源。
- 多时相 NDVI 对比时,应尽量选择同一传感器、同一季节、相近成像条件的数据。
步骤三:在 QGIS 中用栅格计算器计算 NDVI
在 QGIS 中计算 NDVI归一化植被指数,可以使用“栅格计算器”。以 Sentinel-2 为例,Red 为 Band 4,NIR 为 Band 8,表达式可以写成:
("B8@1" - "B4@1") / ("B8@1" + "B4@1")基本操作流程:
- 将红光波段和近红外波段加载到 QGIS。
- 打开“栅格”菜单中的“栅格计算器”。
- 输入 NDVI计算公式。
- 设置输出路径和输出格式,建议使用 GeoTIFF。
- 运行后检查输出栅格的最小值和最大值是否大致在 -1 到 1 之间。
- 给结果设置合适的颜色带,例如低值为棕色或灰色,高值为绿色。
如果输出结果出现极端大值、全黑、全白或大量空值,通常说明波段选错、数据类型处理不当、NoData 没处理好,或者输入影像范围不一致。
步骤四:在 ArcGIS Pro 中用栅格函数或栅格计算器计算
在 ArcGIS Pro 中,可以使用 Raster Calculator 或栅格函数来计算 NDVI。假设近红外图层为 NIR,红光图层为 Red,表达式为:
Float("NIR" - "Red") / Float("NIR" + "Red")使用 Float 的目的是避免整数除法导致结果异常。如果输入是整数型栅格,直接相除可能得到不符合预期的结果。
ArcGIS Pro 中也可以使用内置 NDVI 栅格函数。它的优点是配置方便、可视化快速;缺点是初学者可能忽略具体波段对应关系。因此,即使用工具自动计算,也建议手动确认 Red 和 NIR 的输入是否正确。
步骤五:用 Python 批量计算 NDVI
如果需要批量处理多景影像,可以使用 Python 的 rasterio 库。下面是一个简化示例,适合已对齐、同分辨率、同范围的红光和近红外 GeoTIFF:
import rasterio
import numpy as np
red_path = "red.tif"
nir_path = "nir.tif"
out_path = "ndvi.tif"
with rasterio.open(red_path) as red_src:
red = red_src.read(1).astype("float32")
profile = red_src.profile
with rasterio.open(nir_path) as nir_src:
nir = nir_src.read(1).astype("float32")
denominator = nir + red
ndvi = np.where(denominator == 0, np.nan, (nir - red) / denominator)
profile.update(dtype=rasterio.float32, count=1, nodata=np.nan)
with rasterio.open(out_path, "w", **profile) as dst:
dst.write(ndvi.astype("float32"), 1)这个示例中特别处理了分母为 0 的情况,避免生成无穷大结果。实际项目中还应检查 NoData、投影、像元大小和栅格对齐情况。
常见坑:NDVI值看起来不对时先检查这些问题
坑一:把红光和近红外波段选反
如果把 Red 和 NIR 选反,NDVI值可能整体变成负值,植被区域反而显得很低。遇到这种情况,应先查看原始影像波段说明,而不是急着调整颜色带。
坑二:用错不同卫星的波段编号
Landsat 8/9 的 NIR 是 Band 5,但 Sentinel-2 常用 NIR 是 Band 8。不同传感器不能简单套用同一个波段编号。NDVI计算公式虽然一样,但波段输入必须根据数据源确认。
坑三:未处理 NoData 和云
云、云影、影像边缘 NoData 会明显干扰 NDVI 结果。尤其在区域统计时,如果没有先进行云掩膜或 NoData 处理,平均 NDVI 会被拉低或产生异常。
坑四:直接比较不同季节的 NDVI
植被具有明显季节性。春季、夏季、秋季的 NDVI差异可能来自物候变化,而不一定是生态退化或作物受损。做变化分析时,应尽量选择相同季节或同一生长期影像。
坑五:忽略 NDVI 饱和问题
在高覆盖、高叶面积指数的森林或茂密作物区,NDVI 可能出现饱和现象,也就是植被继续变好,但 NDVI 提升不明显。此时可以考虑结合 EVI、NDRE、LAI 或其他指标分析。
方法比较:NDVI 与其他植被指数怎么选
NDVI归一化植被指数的优点是简单、稳定、资料多、可解释性强。但它不是所有植被问题的最佳答案。下面是几个常见植被指数的简单比较:
| 指标 | 主要用途 | 优点 | 局限 |
|---|---|---|---|
| NDVI | 通用植被覆盖和长势分析 | 公式简单,数据需求低,应用广泛。 | 高植被覆盖区易饱和,受土壤背景和大气影响。 |
| EVI | 高植被覆盖区和大气影响较明显场景 | 对高覆盖植被更敏感,改善部分大气影响。 | 需要蓝光波段,公式更复杂。 |
| SAVI | 稀疏植被和裸土背景明显区域 | 能减弱土壤背景影响。 | 需要设置土壤调节参数。 |
| NDRE | 农作物氮素和中后期长势监测 | 对部分作物中后期状态更敏感。 | 需要红边波段,不是所有影像都有。 |
如果你的目标是快速判断植被覆盖变化,NDVI 通常足够。如果研究区是茂密森林或高产农田,且你关心更细微的植被活力差异,可以考虑引入 EVI 或红边相关指数。
检查清单:发布 NDVI 分析结果前应确认什么
- 是否确认了数据源和传感器类型。
- 是否查清 Red 和 NIR 的正确波段编号。
- 是否使用了地表反射率数据,或明确说明使用 DN 值的限制。
- 是否完成云、云影、NoData 区域处理。
- 输出 NDVI值是否主要落在 -1 到 1 范围内。
- 是否检查了结果图层的坐标系、范围和像元大小。
- 是否使用合理的颜色带,而不是让颜色误导判断。
- 区域统计前是否排除了水体、建筑、云和无效值。
- 多时相对比是否选择了相近季节或相同生长期。
- 结论中是否避免把 NDVI 直接等同于产量、 biomass 或植被面积。
FAQ:NDVI归一化植被指数常见问题
1. NDVI值越高就一定代表植被越好吗?
不一定。一般来说,较高 NDVI值常表示较强植被信号,但它也受季节、地物类型、传感器、大气校正、土壤背景和云影影响。不同区域之间比较时,必须保证数据条件尽量一致。
2. NDVI计算公式中的 NIR 和 Red 可以用任意近红外、红光波段吗?
不能随意替换。应根据具体传感器的波段定义选择对应的红光和近红外波段。尤其是 Sentinel-2 有多个近红外或红边相关波段,常规 NDVI 一般使用 Band 8 作为 NIR,Band 4 作为 Red。
3. 为什么我算出的 NDVI 不在 -1 到 1 之间?
常见原因包括波段选错、输入数据未转为浮点数、NoData 未处理、分母接近 0、影像未正确对齐,或者使用了不合适的比例因子。应先检查原始波段值范围和计算表达式。
4. 用 NDVI 可以直接提取植被面积吗?
可以作为一种简化方法,但不能机械套用固定阈值。不同地区和季节的阈值不同。更稳妥的做法是结合样本点、目视解译、土地利用数据或分类模型确定阈值。
5. NDVI 和绿地率有什么区别?
NDVI 是从遥感影像计算出的植被指数,表达植被光谱响应;绿地率通常是规划或土地利用统计指标,表达某类绿地面积占比。两者相关,但不是同一个概念。
6. 做 NDVI 时间序列分析需要注意什么?
应尽量使用同一传感器或经过一致化处理的数据,保持相近季节或生长期,处理云和云影,并避免将单景影像中的异常值直接解释为趋势变化。
结论:正确理解 NDVI,比会点击工具更重要
NDVI归一化植被指数的核心并不复杂:利用近红外和红光反射差异,通过 NDVI计算公式得到 -1 到 1 之间的植被指数结果。它简单、直观、应用广泛,是 GIS 和遥感分析中非常适合入门和实战的指标。
但在真实项目中,NDVI 的价值取决于数据质量和解释方式。计算前要确认波段,计算中要处理 NoData、云和数据类型,计算后要结合地物、季节和区域背景解释 NDVI值。只有这样,NDVI 结果才不只是漂亮的绿色图层,而是可以支撑空间分析和业务判断的可靠信息。