GIS在空间模式分析中的应用:平均最近邻(Average Nearest Neighbor)
引言
GIS在空间模式分析中的应用:平均最近邻(Average Nearest Neighbor),主要解决一个很常见的问题:一组点要素到底是“聚集分布”“随机分布”,还是“离散分布”?在犯罪点位、门店选址、病虫害样点、事故点、公共设施分布等分析中,平均最近邻可以帮助我们用统计量而不是肉眼判断空间模式。
很多初学者会直接看地图下结论:点看起来很密集,所以就是聚集。但GIS分析不能只靠视觉判断。平均最近邻分析会比较“实际最近邻距离”和“随机分布下的期望最近邻距离”,再结合Z得分和P值判断这种模式是否具有统计显著性。
背景
平均最近邻,也常写作Average Nearest Neighbor,简称ANN,是空间模式分析中最基础、也最容易被误用的点模式分析方法之一。它适用于研究点要素在一个分析范围内的整体空间分布特征。
典型应用场景包括:
- 判断盗窃案件点是否呈现空间聚集。
- 分析便利店、充电桩、医院等设施是否分布均衡。
- 识别地质灾害点、火灾点、交通事故点是否集中在某些区域。
- 比较不同年份事件点的空间分布是否从随机变为聚集。
- 评估采样点是否覆盖均匀,是否存在明显扎堆。
在ArcGIS Pro中,可以使用“Average Nearest Neighbor”工具完成分析;在QGIS中,虽然界面工具名称可能因版本和插件不同而有所差异,但可以通过最近邻距离、点密度、空间统计插件或Python脚本实现类似计算。
需要注意的是,平均最近邻分析回答的是“整体点模式”问题,而不是告诉你“哪里聚集”。如果你想找具体热点区域,应进一步使用核密度分析、热点分析、局部Moran’s I或DBSCAN聚类等方法。
原理
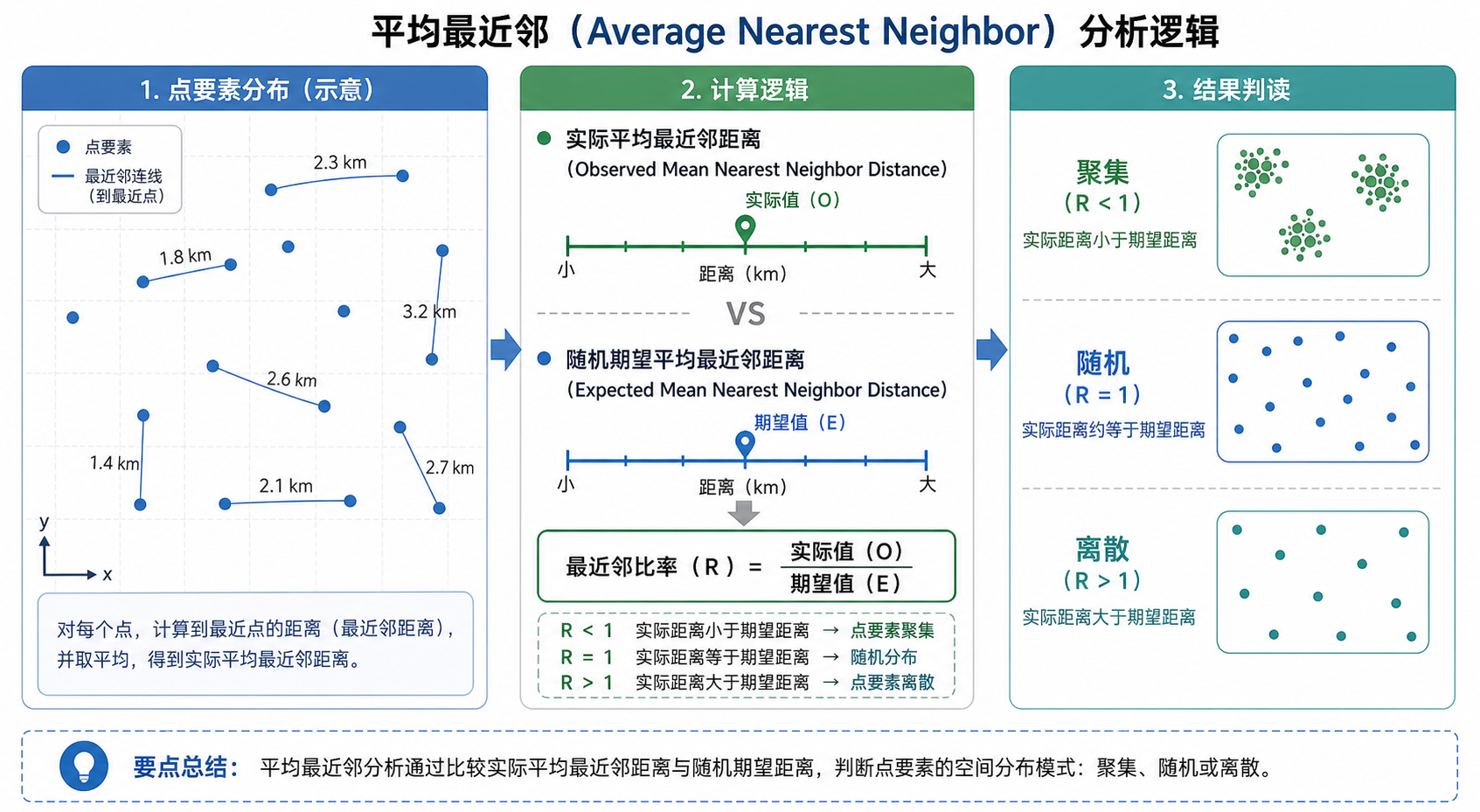
平均最近邻的核心思想很直接:对每一个点,找到距离它最近的另一个点,记录这个最近距离;然后计算所有点的最近距离平均值,得到实际平均最近邻距离。
接着,工具会基于研究区面积和点数量,计算在完全空间随机分布假设下的期望平均最近邻距离。然后用实际值与期望值相除,得到最近邻比率。
| 指标 | 含义 | 解释 |
|---|---|---|
| Observed Mean Distance | 实际平均最近邻距离 | 所有点到最近点距离的平均值 |
| Expected Mean Distance | 期望平均最近邻距离 | 随机分布条件下理论上的平均最近邻距离 |
| Nearest Neighbor Ratio | 最近邻比率 | 实际平均距离除以期望平均距离 |
| Z-score | 标准化统计量 | 用于判断偏离随机分布的程度 |
| P-value | 显著性概率 | 用于判断结果是否具有统计显著性 |
最近邻比率是阅读结果时最关键的指标:
- 比率小于1:点之间比随机分布更近,倾向于聚集分布。
- 比率接近1:点模式接近随机分布。
- 比率大于1:点之间比随机分布更远,倾向于离散或均匀分布。
但是,不能只看最近邻比率。平均最近邻分析还必须结合Z-score和P-value。如果比率小于1但P值很大,说明这种聚集可能只是随机波动造成的,不能轻易下结论。
步骤
1. 准备点要素数据
首先确认你的输入数据是点要素,例如犯罪事件点、门店点、采样点或事故点。平均最近邻不适合直接分析线或面要素。如果数据是面要素,可以先提取质心点,但要清楚质心点是否能代表原始对象的位置。
数据准备时建议检查:
- 是否存在重复点或完全重叠点。
- 是否存在明显错误坐标,例如落在研究区外的点。
- 是否包含不同类型的点,如果混在一起分析是否合理。
- 点数量是否过少,过少样本会导致统计判断不稳定。
2. 使用合适的投影坐标系
平均最近邻依赖距离计算,所以坐标系非常重要。不要直接在经纬度坐标系下计算距离,尤其不要用度作为距离单位解释结果。
正确做法是将数据投影到适合研究区的投影坐标系,例如:
- 中国城市尺度分析可考虑CGCS2000高斯克吕格投影带。
- 小区域项目可使用当地常用投影坐标系。
- 跨国家或大范围区域分析时,需要谨慎选择等距或适合距离计算的投影。
在ArcGIS Pro中,可以使用“Project”工具生成投影后的副本。不要只在图层属性中修改坐标系定义,那只是定义数据坐标含义,不会真正重投影坐标值。
3. 明确研究区范围
平均最近邻对研究区面积很敏感。相同的一组点,如果研究区范围不同,期望平均最近邻距离就会变化,最终的最近邻比率和显著性判断也可能不同。
常见的研究区范围选择包括:
- 行政区边界,例如某市、某区、某街道。
- 业务服务范围,例如门店可达区域、巡逻责任区。
- 自然边界,例如流域、保护区、矿区范围。
- 经过合理裁剪后的有效分析区域,排除海域、无人区或不可达区域。
如果软件工具允许设置研究区面积,应优先使用真实业务边界面积,而不是简单使用点要素外包矩形范围。
4. 在ArcGIS Pro中运行Average Nearest Neighbor
在ArcGIS Pro中,可以按照以下流程操作:
- 打开“Geoprocessing”窗格。
- 搜索“Average Nearest Neighbor”。
- 将点要素图层设置为Input Feature Class。
- 根据需要选择距离方法,常见为Euclidean Distance。
- 如果工具提供研究区面积参数,应根据真实分析边界填写或确认。
- 运行工具并查看Messages中的结果报告。
输出结果通常包括Observed Mean Distance、Expected Mean Distance、Nearest Neighbor Ratio、Z-score和P-value。部分版本还会生成统计图或结果摘要。
5. 用Python理解计算逻辑
如果你希望理解平均最近邻的基本计算逻辑,可以使用GeoPandas和scikit-learn做一个简化版计算。下面代码只演示实际平均最近邻距离,不包含完整显著性检验。
import geopandas as gpd
from sklearn.neighbors import NearestNeighbors
gdf = gpd.read_file("points.shp")
# 确保是投影坐标系,单位通常为米
if gdf.crs is None:
raise ValueError("数据缺少坐标系,请先定义并投影。")
if gdf.crs.is_geographic:
raise ValueError("当前为经纬度坐标系,请先投影到米制坐标系。")
coords = [(geom.x, geom.y) for geom in gdf.geometry]
# n_neighbors=2,因为第一个最近邻是点本身
model = NearestNeighbors(n_neighbors=2)
model.fit(coords)
distances, indices = model.kneighbors(coords)
# 每个点到最近其他点的距离
nearest_distances = distances[:, 1]
observed_mean_distance = nearest_distances.mean()
print("Observed Mean Distance:", observed_mean_distance)这个脚本适合帮助你检查工具结果是否大致合理。如果要严格复现Average Nearest Neighbor,还需要加入研究区面积、期望距离、标准误、Z-score和P-value等计算。
6. 解释分析结果
分析结果不要只写“点呈聚集分布”。更规范的表达应包含比率、Z-score、P-value和业务解释。
例如:
平均最近邻分析结果显示,研究区内事故点的实际平均最近邻距离小于随机分布下的期望距离,最近邻比率小于1;同时Z-score为负且P-value小于0.05,说明事故点在统计意义上呈显著聚集分布。
如果P-value不显著,可以这样写:
虽然最近邻比率略小于1,但P-value未达到常用显著性水平,因此不能认为该点集存在显著聚集模式。当前结果更适合解释为接近随机分布或证据不足。
常见坑
1. 在经纬度坐标系下直接计算距离
这是平均最近邻分析中最常见的错误。经纬度单位是度,不是米。不同纬度下一度经度对应的实际距离不同,直接计算会导致距离结果失真。
解决方法:先使用合适的投影坐标系,再运行Average Nearest Neighbor。
2. 忽略研究区范围
平均最近邻不是只由点的位置决定,还受研究区面积影响。如果你把研究区设得过大,随机期望距离会变大,结果更容易显示聚集;如果研究区过小,则可能影响判断方向。
解决方法:使用与研究问题一致的业务边界,不要随意使用数据外包矩形。
3. 把整体聚集理解为具体热点
平均最近邻只能说明整体空间模式是否偏向聚集、随机或离散,不能定位聚集中心。即使结果显示显著聚集,你仍然不知道具体哪些区域是热点。
解决方法:结合核密度、热点分析或空间聚类方法进一步识别聚集位置。
4. 混合不同类型点一起分析
如果把住宅区门店、工业区仓库、临时摊点混在一起做平均最近邻,得到的结果可能缺乏解释意义。不同类型点背后的空间生成机制不同,混合分析会掩盖真实规律。
解决方法:先按类型、时间、行政区或业务分组,再分别分析。
5. 样本量过少仍强行解释
点数量太少时,平均最近邻的统计结果不稳定。比如只有十几个点,即使结果显示某种趋势,也应谨慎解释。
解决方法:增加样本量,或把结果作为探索性分析,而不是最终证据。
方法比较
平均最近邻适合做整体空间模式判断,但它不是所有点模式问题的唯一选择。实际项目中,应根据问题选择合适方法。
| 方法 | 适合回答的问题 | 优点 | 局限 |
|---|---|---|---|
| 平均最近邻 | 点整体是聚集、随机还是离散 | 简单直观,结果易解释 | 不能指出聚集位置,对研究区范围敏感 |
| 核密度分析 | 哪里点更密集 | 适合生成热点表面 | 带宽参数影响明显,不提供同样的显著性判断 |
| 热点分析 | 哪些区域是显著高值或低值聚集 | 可结合统计显著性识别热点 | 通常需要聚合单元或权重字段 |
| DBSCAN聚类 | 哪些点形成空间簇 | 能识别簇和噪声点 | 参数eps和min_samples需要谨慎设置 |
| Ripley’s K函数 | 不同尺度下是否聚集 | 可分析多尺度空间模式 | 理解和解释成本较高 |
如果你的目标是写一段总体空间分布结论,平均最近邻很合适;如果你的目标是做选址、巡查布点或精确定位热点,仅使用平均最近邻是不够的。
检查清单
在提交平均最近邻分析结果前,建议按下面清单逐项检查:
- 输入数据是否为点要素。
- 点位是否经过错误坐标、重复点和异常值检查。
- 是否使用投影坐标系,而不是经纬度坐标系。
- 投影坐标系是否适合研究区范围和距离计算。
- 研究区边界是否与业务问题一致。
- 是否记录Observed Mean Distance、Expected Mean Distance、Nearest Neighbor Ratio、Z-score和P-value。
- 是否同时解释最近邻比率和显著性结果。
- 是否避免把整体聚集结果误解为具体热点位置。
- 是否说明数据时间范围、点类型和筛选条件。
- 是否在必要时结合核密度、热点分析或聚类方法补充解释。
FAQ
平均最近邻结果中比率小于1就一定是聚集吗?
不一定。比率小于1表示实际平均最近邻距离小于随机期望距离,倾向于聚集。但是否能说“显著聚集”,还要看Z-score和P-value。如果P-value不显著,最好不要下强结论。
Average Nearest Neighbor适合分析面数据吗?
平均最近邻本质上是点模式分析方法,不适合直接分析面要素。如果必须分析面对象,可以提取面质心后分析,但要确认质心能否代表该面对象的位置。例如行政区面质心通常不适合直接代表人口或事件分布。
为什么同一批点在不同研究区范围下结果不同?
因为期望平均最近邻距离依赖研究区面积。研究区越大,在随机分布假设下点之间的期望距离通常越大。因此,研究区范围会直接影响最近邻比率和显著性判断。
平均最近邻和核密度分析有什么区别?
平均最近邻回答整体点模式是否偏向聚集、随机或离散;核密度分析回答哪里点更密集。一个偏统计检验,一个偏空间可视化。实际项目中,两者经常搭配使用。
ArcGIS Pro中的Average Nearest Neighbor结果应该怎么写进报告?
建议至少写清楚输入数据、研究范围、距离单位、最近邻比率、Z-score和P-value,并结合业务场景解释。例如:“在某市行政边界范围内,交通事故点呈显著聚集分布,说明事故发生位置存在空间集中趋势。”
平均最近邻可以比较两个年份的空间模式吗?
可以,但要保证两个年份使用相同的研究区范围、相同的坐标系、相近的数据采集标准,并分别报告结果。否则,差异可能来自数据处理方式,而不是空间模式真实变化。
结论
平均最近邻是GIS空间模式分析中非常实用的基础方法,适合快速判断点要素整体上是聚集、随机还是离散。它的优势是结果清晰、指标明确,特别适合在ArcGIS Pro、Python GIS或空间统计入门场景中使用。
但在实际项目中,平均最近邻不能脱离坐标系、研究区范围和显著性检验来解释。正确的工作流应该是:先清洗点数据,再投影到合适坐标系,明确研究边界,运行Average Nearest Neighbor,最后结合最近邻比率、Z-score和P-value给出谨慎结论。
如果你的分析目标只是判断整体空间模式,平均最近邻已经足够;如果还需要回答“哪里聚集”“聚集范围多大”“哪些点属于同一簇”,则应继续使用核密度、热点分析、DBSCAN或Ripley’s K函数等方法进行补充分析。