GeoPandas读取Shapefile:读取SHP文件报错和读取文件失败
GeoPandas读取Shapefile:读取SHP文件报错和读取文件失败
在 Python GIS 项目里,GeoPandas读取Shapefile通常只需要一行 gpd.read_file()。但真正做数据整理时,很多人会遇到 GeoPandas读取SHP文件 找不到文件、中文属性乱码、缺少 .shx、坐标系为空,或者明明 QGIS 能打开,脚本却提示读取文件失败。
本文按 Dr.GIS 的排查习惯,把这类读取流程拆成三个层次:先确认 Shapefile 文件组完整,再确认 Python 环境和读取路径,最后处理编码、坐标系和几何质量问题。目标不是背错误信息,而是让你能稳定判断读取 SHP 报错到底发生在哪一层。
问题背景:为什么 GeoPandas 读一个 SHP 也会失败
Shapefile 看起来像一个 .shp 文件,实际是一组同名文件。至少需要 .shp 保存几何、.shx 保存索引、.dbf 保存属性表;如果有 .prj,GeoPandas 才能读到坐标参考信息;如果有 .cpg,读取中文属性时更容易判断编码。
因此,读取 SHP 失败时,不要只看 Python 代码。先检查文件是不是完整复制、路径是否写对、底层 GDAL/OGR 依赖是否可用,再看数据本身是否存在编码、坐标系或几何问题。
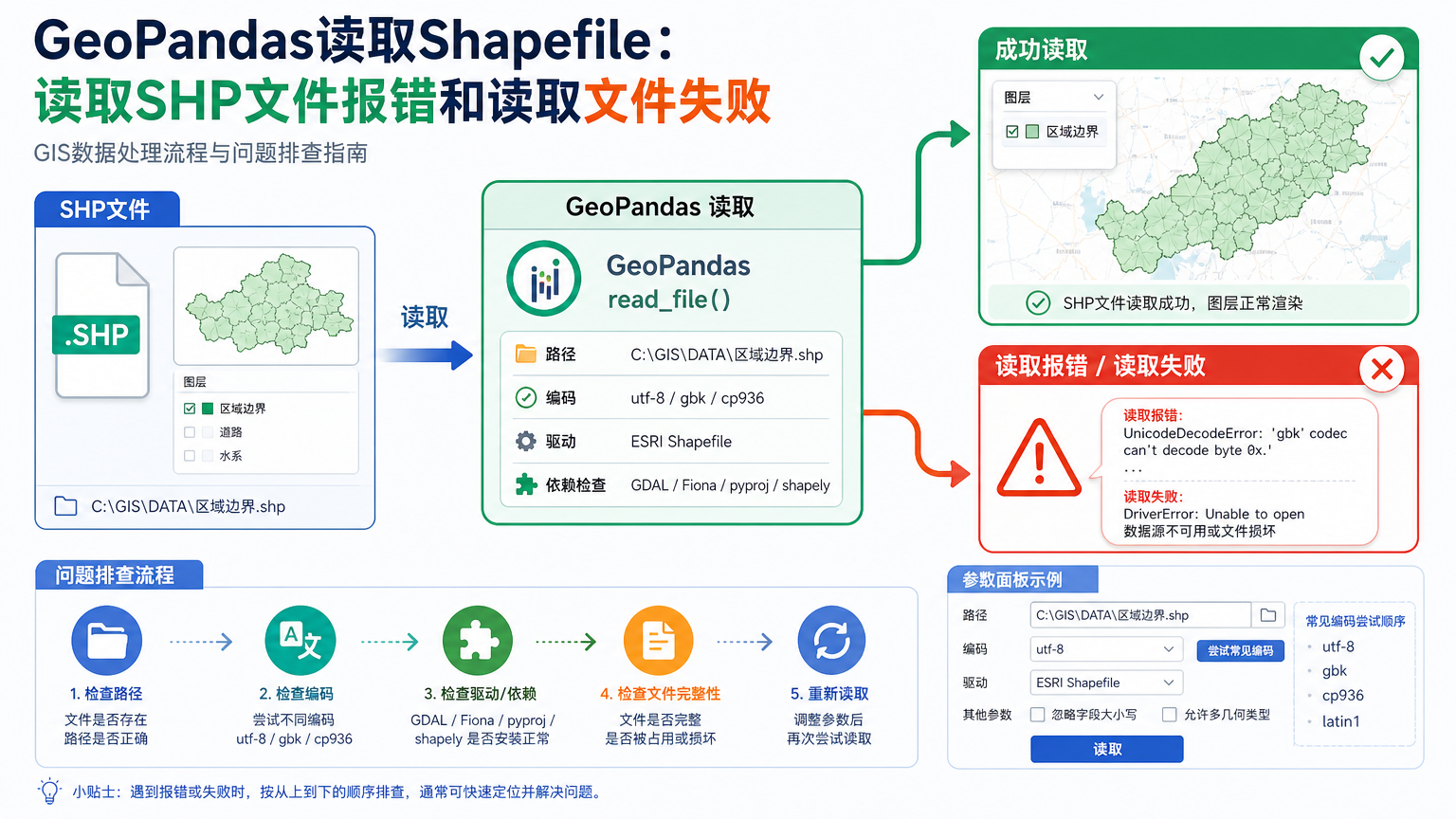
核心原理:GeoPandas读取Shapefile背后的数据链路
GeoPandas 本身负责把空间数据组织成 GeoDataFrame,但读写文件依赖 GDAL/OGR 生态。实际环境中,底层读取引擎可能是 pyogrio 或 Fiona,二者都需要能够识别 Shapefile 这一 OGR 驱动。
这一读取过程可以理解为四步:
- 定位数据源。根据路径找到
.shp,并检查同名文件组。 - 调用底层驱动。GDAL/OGR 读取几何、属性字段和图层元数据。
- 转换为 GeoDataFrame。GeoPandas 把几何列放入
geometry,属性字段放入普通列。 - 附带空间参考。如果
.prj可识别,结果的gdf.crs会有坐标系;否则可能是None。
这条链路任意一段出错,都会表现为 GeoPandas读取文件失败。所以排查时要分清:是路径没找到、驱动没装好、文件组不完整,还是读取成功但数据质量不符合后续分析要求。
第一步:用最小代码完成 GeoPandas读取SHP文件
先不要把读取代码写进复杂项目。新建一个最小脚本,只读一个确定存在的 Shapefile,并打印行数、字段、坐标系和前几行属性。
import geopandas as gpd
shp_path = "data/land.shp"
gdf = gpd.read_file(shp_path)
print(gdf.shape)
print(gdf.columns)
print(gdf.crs)
print(gdf.head())如果这段代码成功,说明基础读取链路是通的。后续问题多半在编码、字段、坐标系、几何或业务逻辑上。如果这段代码都失败,应先回到文件、路径和环境排查,不要急着修改空间分析代码。
建议把 shp_path 写成项目内相对路径或明确的绝对路径。Windows 路径可以使用原始字符串,避免反斜杠被 Python 当作转义字符。
# Windows 推荐写法之一
shp_path = r"D:\gis_project\data\land.shp"
# 或统一使用正斜杠
shp_path = "D:/gis_project/data/land.shp"GeoPandas读取SHP报错:先检查文件组是否完整
很多 GeoPandas读取SHP报错 的根因不是 Python,而是 Shapefile 文件组不完整。只收到一个 .shp 文件时,几何可能存在,但属性表、索引和坐标系信息可能缺失,读取结果就会异常。
from pathlib import Path
base = Path("data/land")
required = [".shp", ".shx", ".dbf"]
optional = [".prj", ".cpg"]
for suffix in required + optional:
file_path = base.with_suffix(suffix)
print(file_path, file_path.exists())至少要保证 .shp、.shx、.dbf 同名且在同一目录。.prj 缺失通常不会让读取立刻失败,但会让 gdf.crs 变成空值,后续面积、长度、叠加和重投影都可能出问题。
如果错误信息里出现无法打开 .shx 或索引文件缺失,最稳妥的处理是向数据提供方索要完整文件组,或用 QGIS、ogr2ogr 从原始数据重新导出一份完整 Shapefile。临时重建索引只适合应急,不适合替代正式数据交付。
第二步:排查 Python 环境和底层驱动
如果文件组完整,但一运行就报缺少依赖、驱动不可用、DLL 加载失败或 GDAL 相关错误,问题通常在 Python GIS 环境。GeoPandas、pyogrio、Fiona、GDAL、PROJ、Shapely 之间存在底层依赖关系,混用多个安装渠道时容易冲突。
建议优先使用同一个渠道创建干净环境。例如在 conda 环境中,尽量从同一渠道安装 GeoPandas 及其空间依赖:
conda create -n pygis python=3.11
conda activate pygis
conda install -c conda-forge geopandas pyogrio fiona shapely pyproj如果你使用 pip,也建议在虚拟环境里安装,并避免把系统 GDAL、QGIS 自带 Python、ArcGIS Pro Python 和项目环境混在一起。环境冲突会让读取失败看起来像数据问题,实际是底层库版本或动态库路径不一致。
可以先用下面的代码确认 GeoPandas 能正常导入,并查看当前读取相关库是否可用:
import geopandas as gpd
print(gpd.__version__)
print(gpd.list_layers("data/land.shp"))如果 list_layers 都不能正常执行,先修环境。如果 list_layers 能识别图层,但 read_file 失败,再继续看编码、字段和几何。
第三步:处理路径错误和工作目录混乱
脚本里最常见的路径问题,是你以为当前目录在项目根目录,实际运行时在 IDE、Notebook 或命令行的另一个目录。结果 data/land.shp 在文件管理器里明明存在,Python 却找不到。
from pathlib import Path
import geopandas as gpd
print("当前工作目录:", Path.cwd())
shp_path = Path("data/land.shp")
print("SHP 是否存在:", shp_path.exists())
print("绝对路径:", shp_path.resolve())
gdf = gpd.read_file(shp_path)如果 exists() 返回 False,就不是 GeoPandas 读取能力的问题,而是路径没有指向真实文件。Notebook 中尤其要注意启动目录;批处理脚本中要注意相对路径是相对谁。
路径中包含中文、空格或网络盘时,现代环境通常可以处理,但为了批量任务稳定,建议把待处理数据放在简单目录下,例如 project/data/raw/land.shp。服务器任务还要检查文件权限,确认运行脚本的账号有读取目录和文件的权限。
GeoPandas读取文件失败:中文乱码和 DBF 编码怎么处理
Shapefile 的属性存放在 DBF 中,中文字段最容易出现编码问题。常见表现是读取没有报错,但字段值变成乱码;也可能在读取时直接触发 Unicode 相关错误。这类 GeoPandas读取文件失败 要从 DBF 编码和 .cpg 文件入手。
可以在读取时显式指定编码:
import geopandas as gpd
gdf = gpd.read_file("data/land.shp", encoding="GBK")
print(gdf[["name"]].head())如果数据来自较新的 Web 系统或跨平台工具,可能是 UTF-8;如果来自较老的中文桌面 GIS、历史测绘数据或 Windows 工程目录,可能是 GBK 或 GB18030。不要在正式流程里靠猜,最好先读取少量样本字段,确认中文名称、地类、地址等关键字段是否正常。
for enc in ["UTF-8", "GBK", "GB18030"]:
try:
gdf = gpd.read_file("data/land.shp", encoding=enc)
print(enc, gdf.head(3))
except Exception as exc:
print(enc, type(exc).__name__, exc)编码问题解决后,建议把数据转换成 GeoPackage 或 Parquet 这类更适合 Python 项目管理的格式,减少后续反复读取 Shapefile 时再次遇到编码差异。
第四步:读取成功后检查 CRS、几何和字段
有些问题不会让读取 Shapefile 失败,但会让后面的分析失败。例如 .prj 缺失导致 CRS 为空,几何字段中有空几何,或者字段名被 Shapefile 的 DBF 限制截断。
import geopandas as gpd
gdf = gpd.read_file("data/land.shp", encoding="GBK")
print("行列数:", gdf.shape)
print("坐标系:", gdf.crs)
print("几何类型:", gdf.geom_type.value_counts(dropna=False))
print("空几何数量:", gdf.geometry.isna().sum())
print("无效几何数量:", (~gdf.geometry.is_valid).sum())如果 gdf.crs 是 None,不要直接重投影。先确认原始数据真实坐标系,再用 set_crs() 写入源坐标系;只有源坐标系正确以后,才用 to_crs() 转换到目标坐标系。
# 数据本来就是 EPSG:4549,但缺少 .prj 时,先定义源 CRS
gdf = gdf.set_crs(epsg=4549)
# 需要用于 Web 地图展示时,再转换到 EPSG:3857
gdf_web = gdf.to_crs(epsg=3857)如果几何无效,读取阶段可能不报错,但叠加、缓冲、面积统计或导出时会失败。可以先定位问题要素,再决定用 QGIS、GeoPandas 或 PostGIS 修复。不要在没有备份的情况下批量覆盖原始数据。
第五步:把常见错误信息翻译成排查动作
遇到读取 SHP 报错,不要只复制最后一行错误。更有效的做法是把错误归类,再执行对应检查。
| 常见现象 | 可能原因 | 排查动作 |
|---|---|---|
No such file or directory |
路径写错、工作目录不对、文件名大小写不一致 | 打印 Path.cwd()、exists() 和绝对路径 |
| 提示无法打开数据源 | 文件组不完整、文件损坏、底层驱动不可用 | 检查 .shp、.shx、.dbf,再用 QGIS 或 ogrinfo 验证 |
缺少 .shx 或索引错误 |
传输或解压时漏文件,索引文件损坏 | 重新获取完整文件组,必要时从原始数据重新导出 |
| 中文字段乱码 | DBF 编码和读取参数不一致 | 尝试 encoding="GBK"、encoding="GB18030" 或 encoding="UTF-8",并检查 .cpg |
gdf.crs 是 None |
缺少 .prj 或空间参考无法识别 |
确认原始坐标系后用 set_crs(),不要盲目 to_crs() |
| 读取成功但分析失败 | 空几何、无效几何、混合几何类型或字段被截断 | 检查 geom_type、is_valid、字段名和空值 |
第六步:用 ogrinfo 或 QGIS 交叉验证数据
如果 GeoPandas 报错信息不清楚,可以用 GDAL 命令行或 QGIS 做交叉验证。这样能判断问题是 Python 环境造成的,还是 Shapefile 本身就有问题。
ogrinfo data/land.shp -so -al如果 ogrinfo 也打不开,优先修数据文件组。如果 ogrinfo 能读、QGIS 也能打开,但 GeoPandas 失败,重点回到 Python 环境、读取引擎、编码参数和路径权限。
也可以先用 QGIS 或 ogr2ogr 把 Shapefile 转成 GeoPackage,再让 GeoPandas 读取。GeoPackage 是单文件,支持更长字段名和更明确的编码管理,适合后续 Python 批处理。
ogr2ogr -f GPKG data/land.gpkg data/land.shpimport geopandas as gpd
gdf = gpd.read_file("data/land.gpkg")常见坑点:读出来不等于可以直接分析
- 把 .shp 当成单文件发送。别人只发一个
.shp给你时,先要求补齐同名文件组。 - 路径问题误判为库问题。先用
Path.exists()验证路径,再讨论 GeoPandas。 - 中文乱码后直接改字段。乱码不是字段内容错了,通常是 DBF 编码解释错了。先调
encoding。 - CRS 为空就直接 to_crs。缺少源坐标系时,
to_crs()没有可靠依据。先定义正确源 CRS。 - 忽略 Shapefile 字段限制。字段名过长会被截断,多个字段可能变得难以区分,正式 ETL 前要建立字段映射。
- 把 QGIS 能打开等同于数据完全正常。QGIS 可能容忍部分问题,但批处理脚本、空间叠加和数据库入库会更严格。
- 混用多个 Python 环境。Notebook、命令行、IDE、QGIS Python 和 ArcGIS Pro Python 可能不是同一个解释器。
工具和方法对比:GeoPandas、QGIS、ogr2ogr 怎么选
解决这类读取失败时,不一定只靠 GeoPandas。不同工具适合不同阶段,交叉验证能更快定位问题。
| 方法 | 适合场景 | 注意点 |
|---|---|---|
| GeoPandas | Python 批处理、字段清洗、空间分析、自动化转换 | 依赖环境要稳定,读取失败时要拆分检查文件、路径、编码和 CRS |
| QGIS | 快速查看图层、人工确认坐标系、检查中文属性和几何位置 | 手工操作要记录实际编码、坐标系和导出参数 |
ogrinfo |
命令行检查图层元数据、几何类型、范围和字段 | 适合判断底层 GDAL 是否能识别数据源 |
ogr2ogr |
格式转换、修复交付格式、批量转 GeoPackage 或 PostGIS | 参数较多,正式批处理前应先用小样本验证 |
实际项目中,推荐流程是:先用 GeoPandas 最小脚本复现问题;如果失败,再用 QGIS 或 ogrinfo 验证数据;如果 Shapefile 本身复杂或历史包袱较多,可以先转成 GeoPackage 再进入 Python 工作流。
实用清单:GeoPandas读取Shapefile稳定流程
- 确认文件组。检查
.shp、.shx、.dbf是否同名同目录,优先保留.prj和.cpg。 - 确认路径。打印当前工作目录、文件是否存在和绝对路径,排除相对路径误判。
- 确认环境。使用干净虚拟环境,避免混用多个 GDAL/PROJ 来源。
- 先写最小脚本。只做
read_file、shape、columns、crs、head检查。 - 处理编码。中文属性异常时显式设置
encoding,并抽查关键字段。 - 检查坐标系。
gdf.crs为空时先确认源 CRS,再使用set_crs。 - 检查几何质量。统计空几何、无效几何和混合几何类型,不要直接进入叠加分析。
- 交叉验证。用 QGIS、
ogrinfo或ogr2ogr判断是数据问题还是 Python 环境问题。 - 转换长期格式。批处理项目中可把外部 SHP 先转换为 GeoPackage 或 Parquet,降低后续读取风险。
FAQ:GeoPandas读取Shapefile、读取SHP报错和读取文件失败
GeoPandas读取Shapefile 只需要 .shp 文件吗?
不够。Shapefile 是文件组,至少要有同名的 .shp、.shx、.dbf。如果缺少 .prj,GeoPandas 可能仍能读出几何和属性,但坐标系会缺失,后续重投影、面积和距离分析会不可靠。
GeoPandas读取SHP文件 提示找不到文件怎么办?
先不要改读取参数。打印 Path.cwd()、Path("data/land.shp").exists() 和绝对路径,确认脚本运行目录与数据目录是否一致。很多这类失败只是相对路径写错。
GeoPandas读取SHP报错 缺少 .shx 怎么办?
优先向数据提供方要完整 Shapefile 文件组,或用 QGIS、ogr2ogr 从原始数据重新导出。缺少 .shx 时,临时重建索引只能作为应急方案;正式项目不应把不完整数据当作可靠来源。
GeoPandas读取文件失败 但 QGIS 可以打开是什么原因?
常见原因是 Python 环境中的 GDAL/PROJ 依赖冲突、读取引擎差异、编码参数没有指定,或者脚本路径和 QGIS 打开的路径不是同一个文件。遇到这种失败,建议用 ogrinfo 交叉验证,再检查虚拟环境和读取参数。
读取后中文属性乱码怎么处理?
在 gpd.read_file() 中显式设置 encoding,常见尝试包括 UTF-8、GBK 和 GB18030。先抽查名称、地址、地类等中文字段,确认正常后再进入正式批处理。
读取成功但 gdf.crs 是 None,可以直接 to_crs 吗?
不建议。gdf.crs 为空说明 GeoPandas 不知道源坐标系。应先从 .prj、数据说明、QGIS 图层属性或数据生产单位确认源 CRS,再用 set_crs() 写入,之后才能用 to_crs() 转换。
结论:把 GeoPandas 读取失败拆成文件、环境和数据三层
GeoPandas读取Shapefile 本身并不复杂,但 Shapefile 文件组、DBF 编码、Python GIS 依赖和坐标系信息都会影响读取结果。遇到错误时,先用最小脚本复现,再按文件完整性、路径、环境、编码、CRS 和几何质量逐项排查。
对长期项目来说,最稳的做法是把外部 SHP 当作原始交换格式:先检查并读取,必要时转成 GeoPackage 或 Parquet,再进入 GeoPandas 批处理流程。这样能减少这类报错的重复发生,也能让团队更容易定位下一次读取文件失败的真实原因。
-
QGIS虚拟图层SQL查询:连接表和空间筛选 2026-06-13 01:55:21
-
DEM流向:水文分析和流域划分前处理 2026-06-13 01:50:34
-
无人机正射影像:航测正射和影像正射流程 2026-06-12 22:19:43
-
无人机航测精度:像控点布设和飞行高度计算 2026-06-12 20:49:03
-
OpenLayers点击事件:图层点击事件和坐标拾取 2026-06-12 01:38:49
-
QGIS Processing报错:Processing错误和处理工具箱打不开 2026-06-11 20:55:46
-
Sentinel2云掩膜:大气校正、GEE去云和NDVI检查 2026-06-11 13:42:34
-
ArcGIS Pro字段计算器:数值涵义和顺序编号 2026-06-11 11:39:27
-
ArcPy栅格计算:arcpy.sa和栅格计算器排查 2026-06-11 10:48:22
-
ArcPy字段计算:AddField、字段映射和更新游标 2026-06-11 09:49:34
-
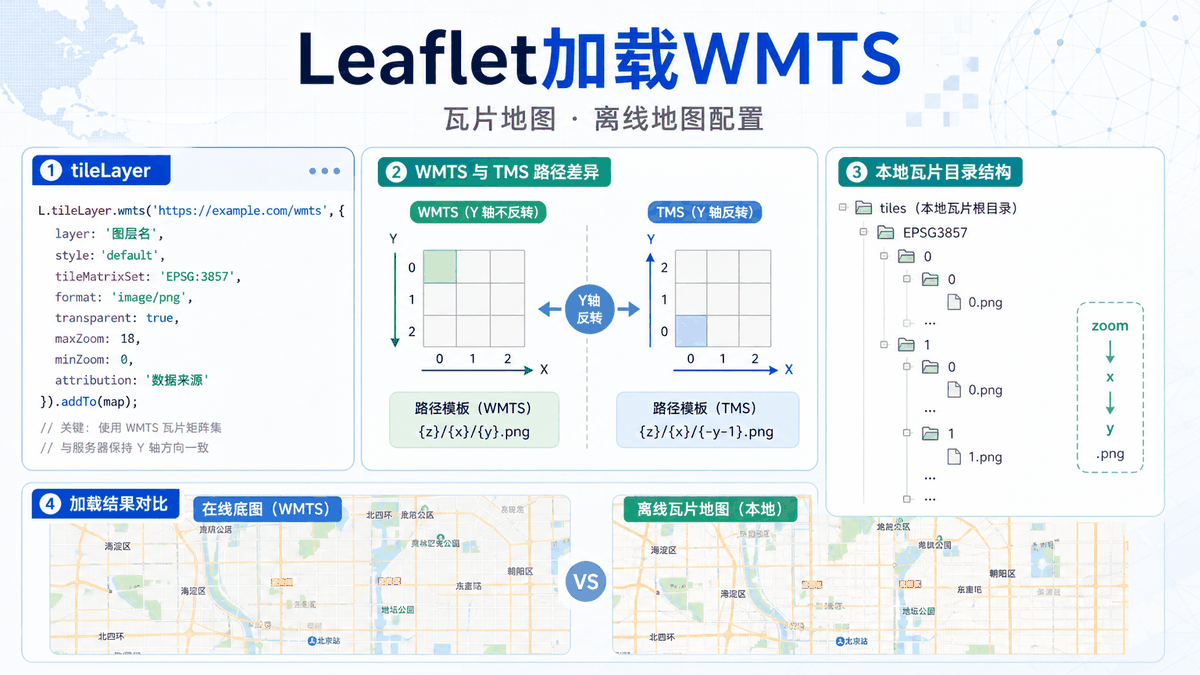
Leaflet加载WMTS:瓦片地图和离线地图配置 2026-06-11 03:40:08
-
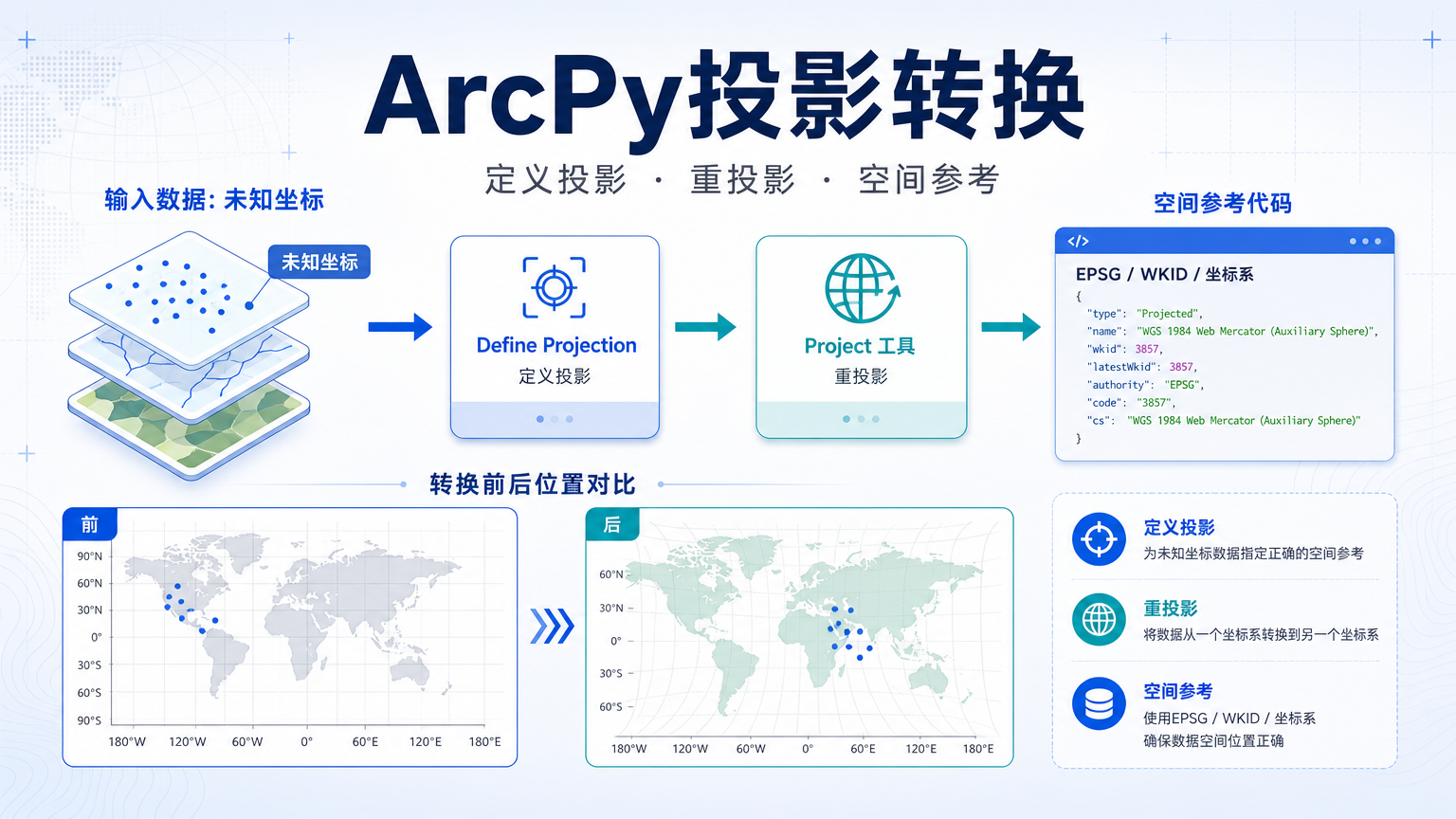
ArcPy投影转换:定义投影、重投影和空间参考 2026-06-10 20:51:20
-
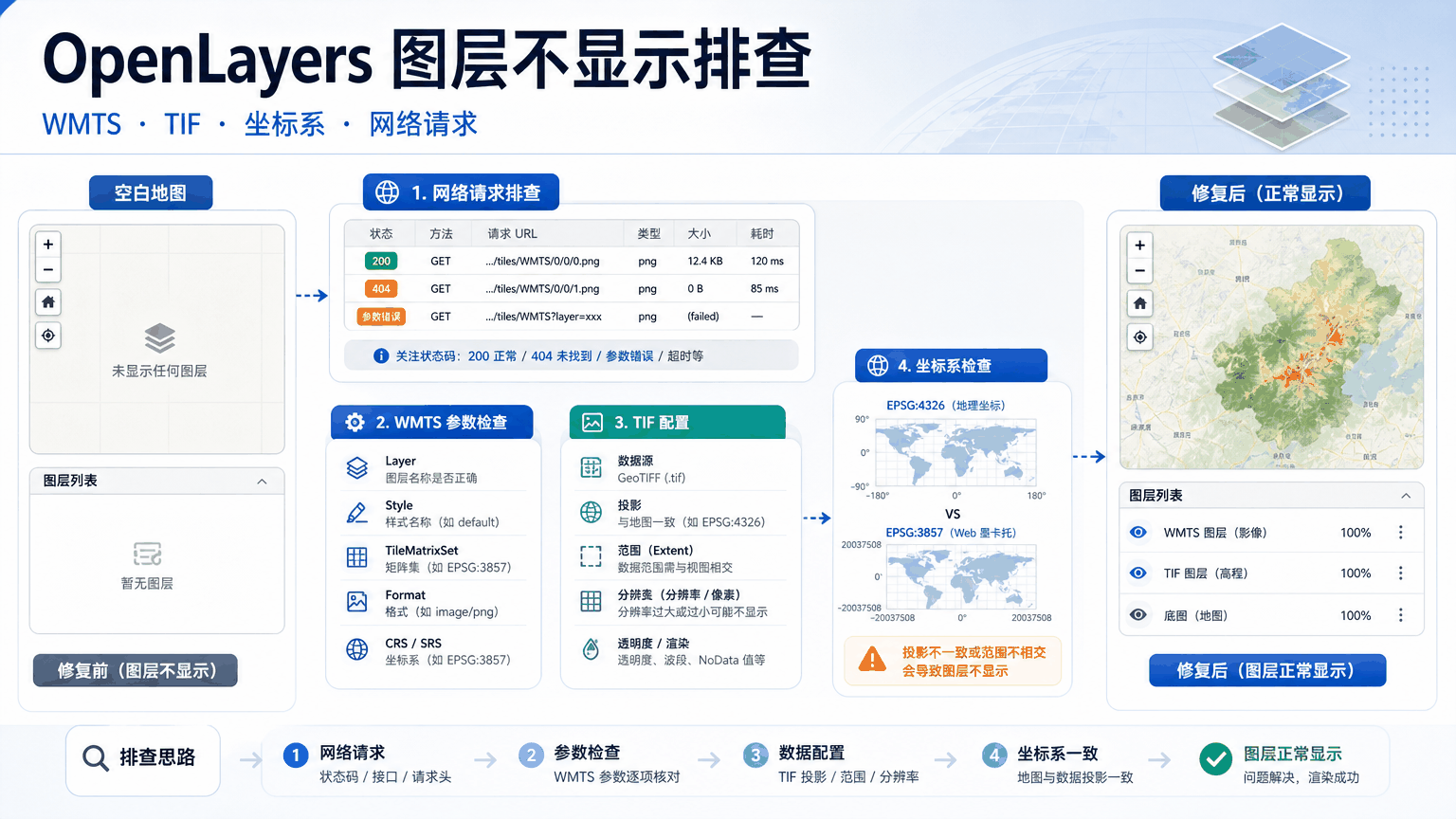
OpenLayers图层不显示:WMTS、TIF加载和原因排查 2026-06-10 19:22:44
-
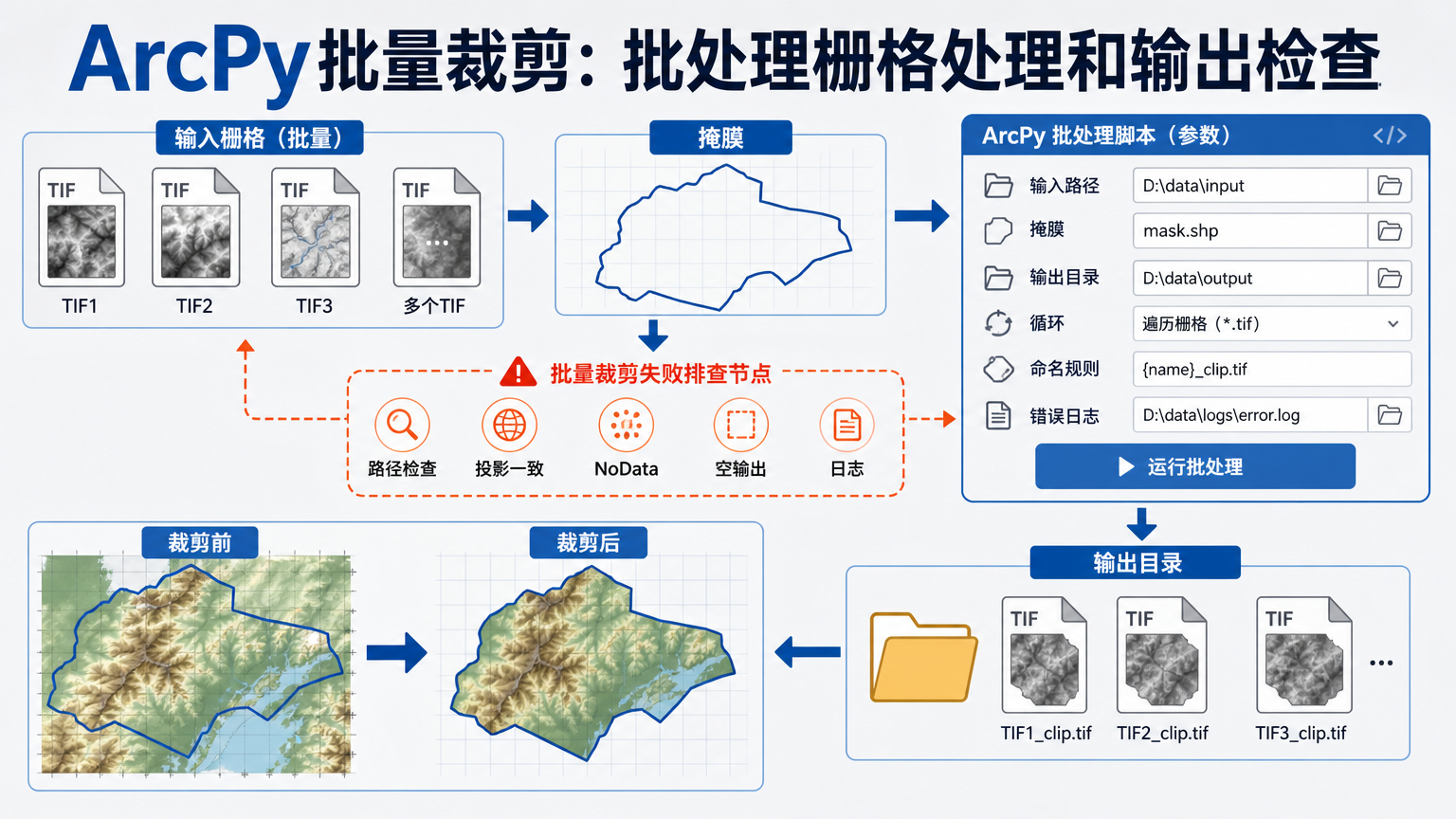
ArcPy批量裁剪:批处理栅格处理和输出检查 2026-06-10 18:47:40
-
GeoPandas裁剪:clip、读取SHP和GeoJSON裁剪流程 2026-06-10 08:45:06
-
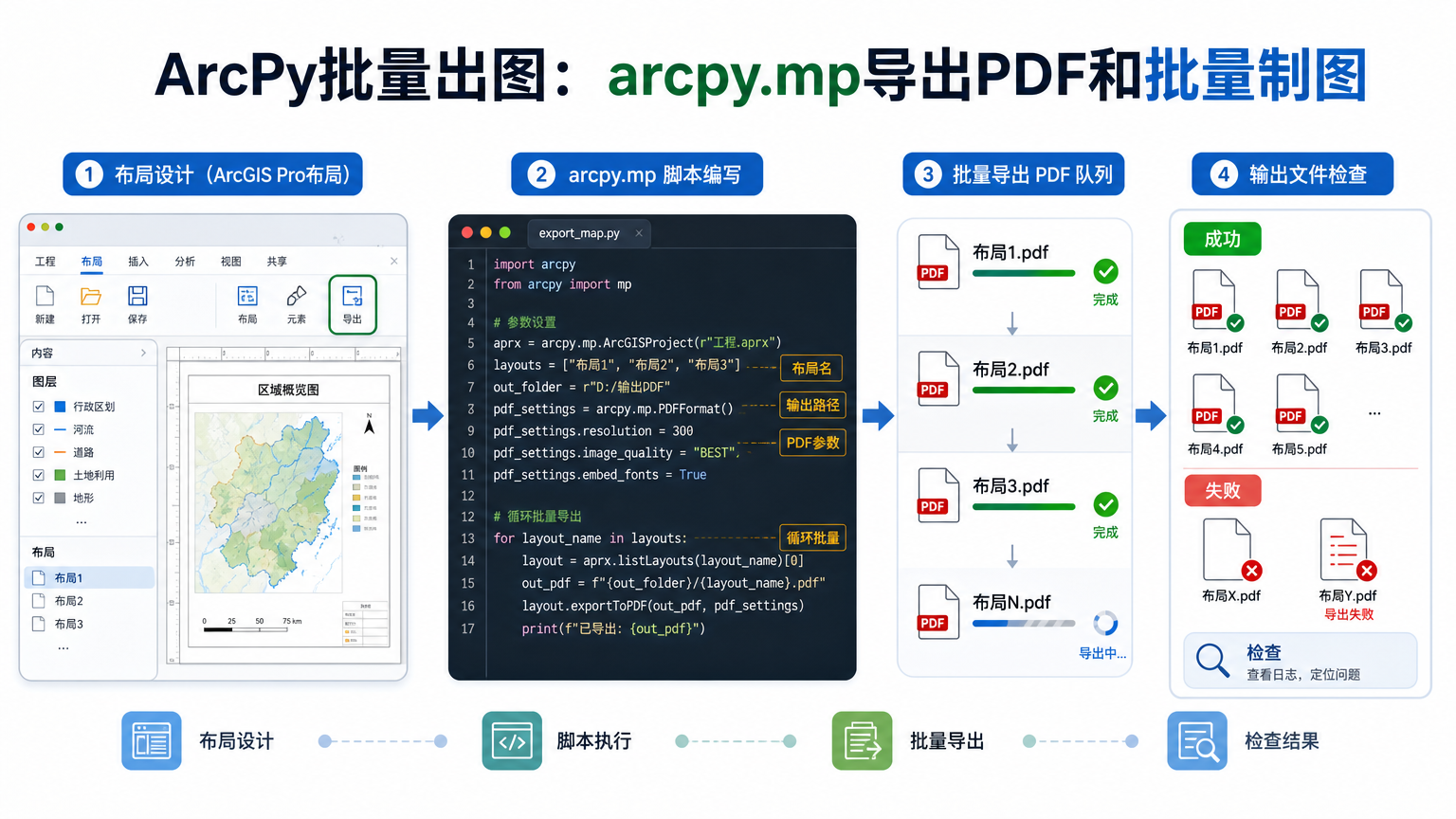
ArcPy批量出图:arcpy.mp导出PDF和批量制图 2026-06-10 08:40:05
-
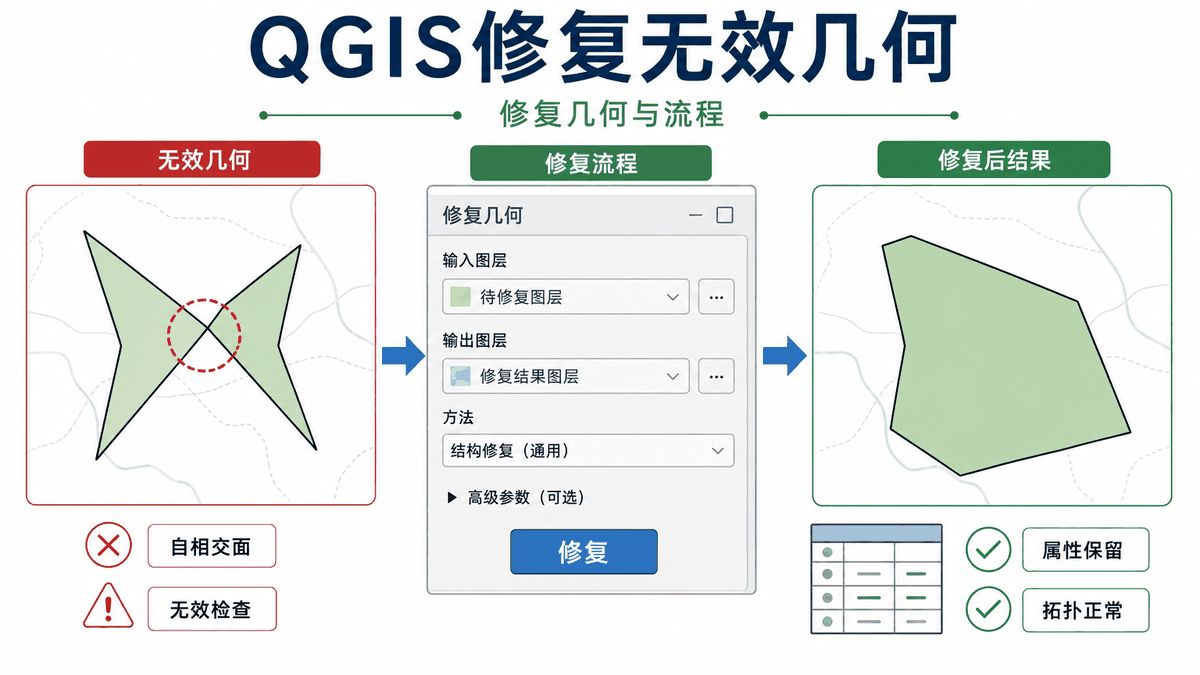
QGIS修复无效几何:修复几何和几何修复流程 2026-06-10 03:48:19
-
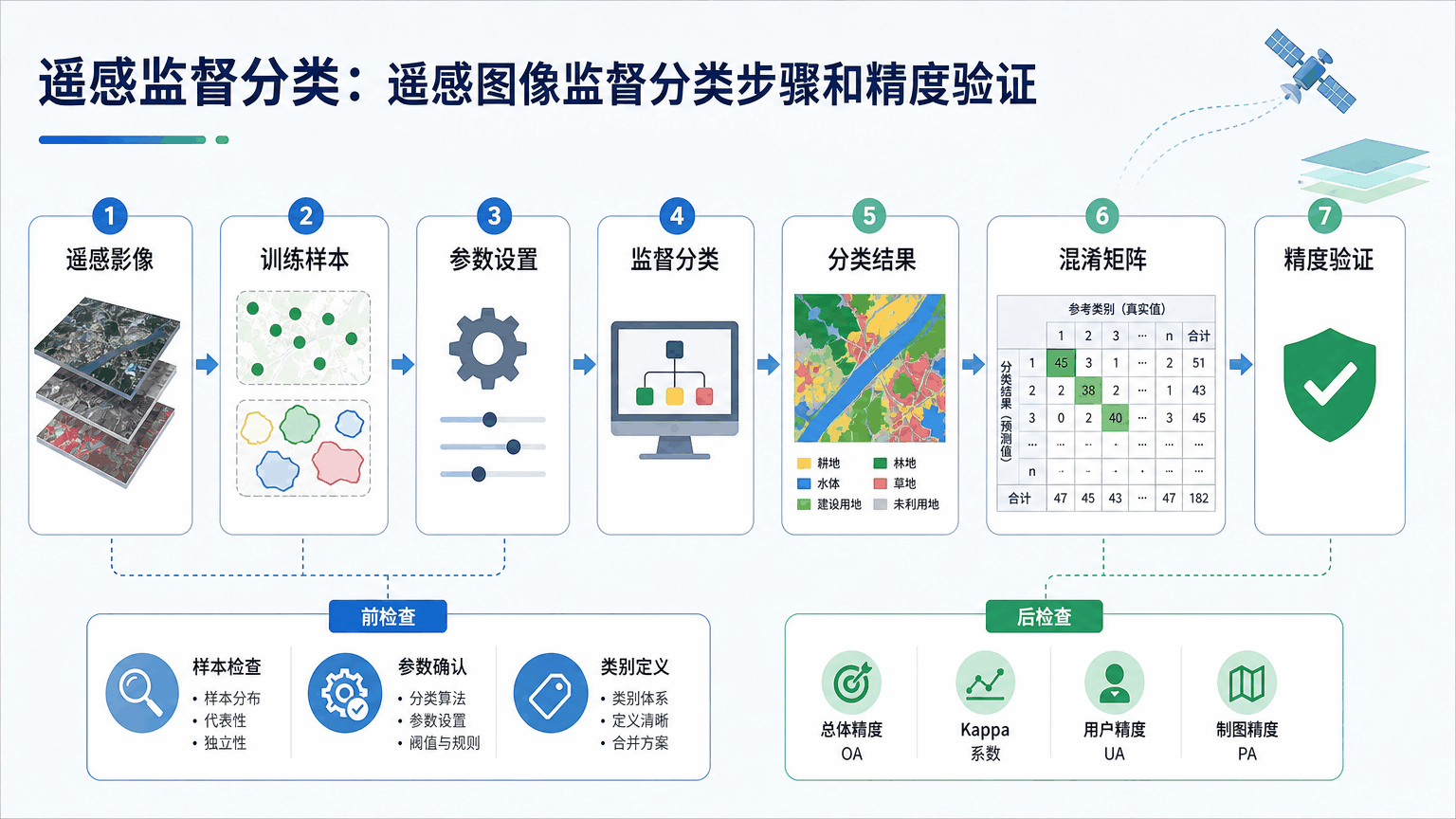
遥感监督分类:遥感图像监督分类步骤和精度验证 2026-06-09 18:16:55
-
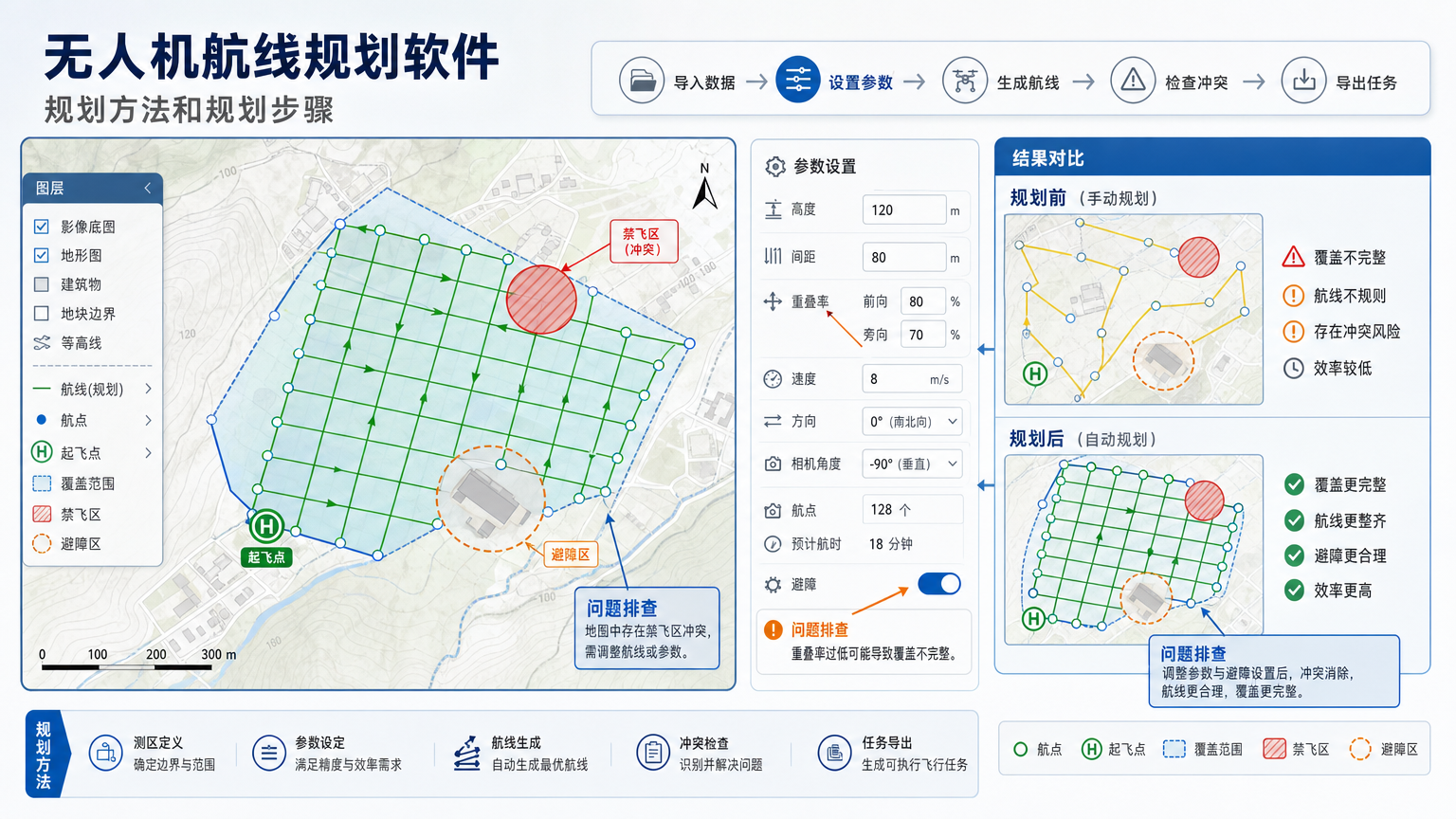
无人机航线规划软件:规划方法和规划步骤 2026-06-09 15:16:34
-
无人机测绘流程:软件有哪些、数据处理和精度 2026-06-09 13:32:14