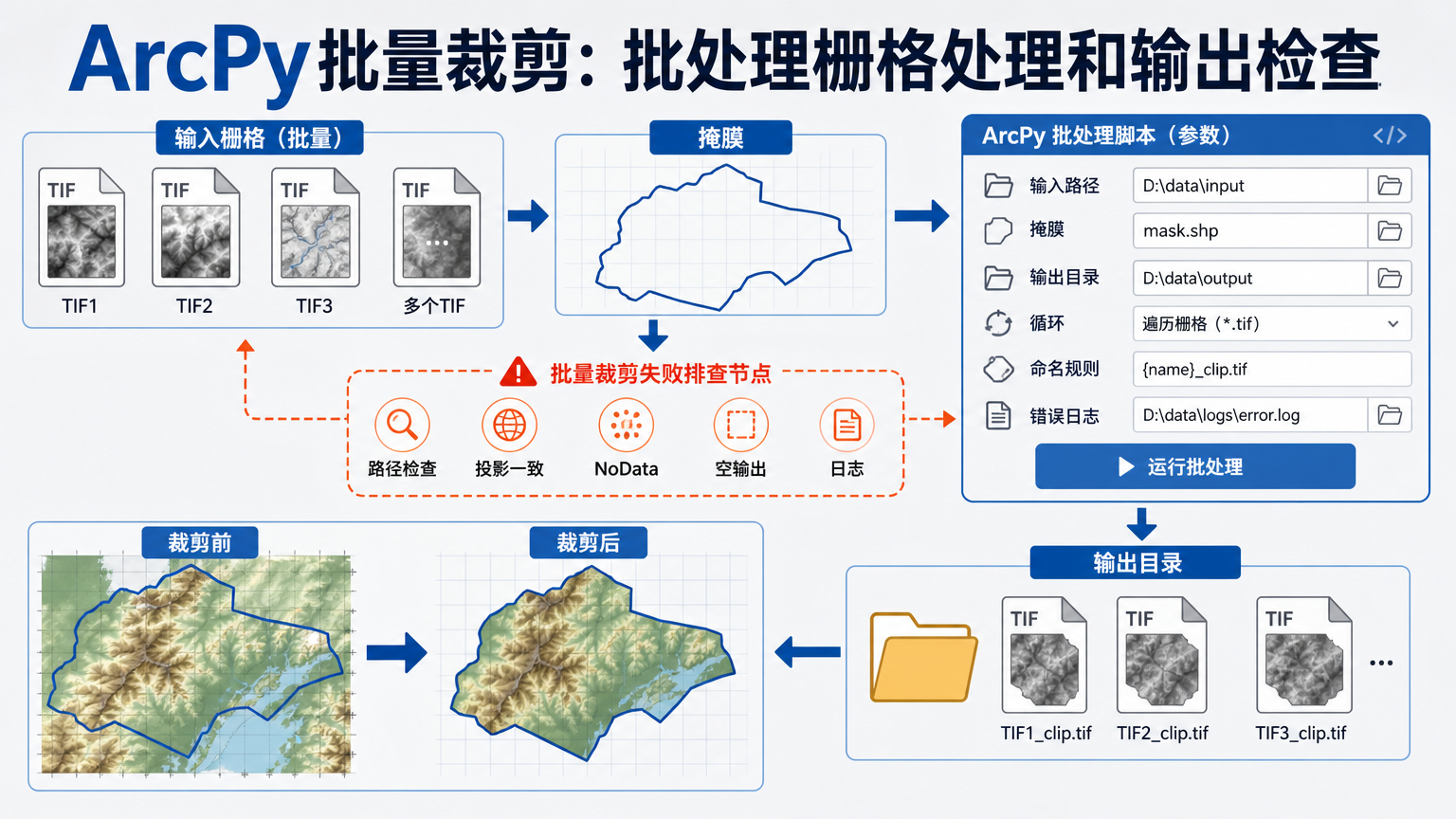
ArcPy批量裁剪:批处理栅格处理和输出检查
在实际项目中,ArcPy批量裁剪常用于把一批遥感影像、DEM、分类栅格或专题栅格按行政区、研究区、样地边界统一裁出。单个文件用 ArcGIS Pro 的 Clip Raster 工具并不难,真正容易出错的是几十个、几百个栅格连续处理时,输出范围、像元对齐、NoData、命名和结果检查没有被标准化。
这篇教程以 Python GIS 自动化工程师的视角,讲清楚如何用 arcpy批量裁剪完成可复用的 arcpy批处理流程,并把 arcpy栅格处理后的输出检查也写进脚本。目标不是只跑通一次,而是让批处理结果可追踪、可复核、可交付。
ArcPy批量裁剪的项目背景:为什么不能只手动点工具
常见场景是:一个文件夹里有逐月 NDVI、土地覆盖、坡度、降雨或夜光栅格,项目只需要某个城市、流域或保护区范围内的数据。如果每个栅格都手动裁剪,短期看似省事,长期会遇到三类问题。
- 参数不一致:某些栅格用矩形范围裁剪,某些栅格用边界面裁剪,输出边缘会不一致。
- 命名不可控:手动输出容易出现重复名、临时名、中文路径混用,后续统计很难追溯。
- 结果没人检查:只要工具没有报错,并不代表裁剪结果有效,空栅格、范围偏移、NoData 异常都可能混进成果。
arcpy批量裁剪的核心原理:范围裁剪、掩膜裁剪和像元对齐
开始写脚本前,需要先区分两个概念:按矩形范围裁剪和按面要素掩膜裁剪。矩形范围只控制输出的外接框,速度通常更快;掩膜裁剪会按照面边界保留内部像元,边界外写成 NoData,更适合行政区、流域、保护地等不规则研究区。
在 arcpy栅格处理里,裁剪结果是否可靠,主要取决于三组参数。
- 输入栅格:坐标系、像元大小、波段数和 NoData 设置要清楚。
- 裁剪边界:边界要素最好是单一面或已融合面,并且与栅格坐标系兼容。
- 环境设置:包括
arcpy.env.workspace、arcpy.env.snapRaster、arcpy.env.cellSize、arcpy.env.extent和arcpy.env.overwriteOutput。
如果多个栅格本来就来自同一套产品,例如同分辨率、同投影、同网格的逐期影像,建议指定一个基准栅格作为 snapRaster。这样每个输出栅格的像元网格更容易保持一致,后续叠加、栅格计算和时间序列统计会少很多麻烦。
批量裁剪前的输入数据准备
正式写脚本前,先把数据组织成稳定的目录结构。下面是一种适合教学和项目交付的组织方式。
project/
input_rasters/
ndvi_202401.tif
ndvi_202402.tif
ndvi_202403.tif
boundary/
study_area.shp
output_clip/
logs/
建议输入栅格统一使用英文文件名、数字和下划线。路径里尽量避免特殊符号。ArcGIS Pro 对中文路径的支持已经比早期稳定很多,但脚本路径越简单,跨电脑复用和排错越省时间。
裁剪边界的检查要点
- 边界图层有正确的投影信息,不是 Unknown Coordinate System。
- 边界面没有明显自相交、空几何或异常碎面。
- 如果需要按一个整体研究区裁剪,先 Dissolve 融合成单个面。
- 边界范围与输入栅格有空间重叠,否则工具可能生成空结果或直接失败。
arcpy批处理脚本:批量裁剪栅格并记录日志
下面的示例使用 arcpy.management.Clip 对文件夹中的 .tif 栅格进行循环裁剪。它适合入门和多数常规项目:输入一批栅格、使用一个面要素作为裁剪边界、输出同名加后缀的结果,并在控制台打印处理状态。
import arcpy
from pathlib import Path
input_dir = Path(r"D:\gis_project\input_rasters")
boundary = r"D:\gis_project\boundary\study_area.shp"
output_dir = Path(r"D:\gis_project\output_clip")
output_dir.mkdir(parents=True, exist_ok=True)
arcpy.env.overwriteOutput = True
arcpy.env.workspace = str(input_dir)
rasters = sorted(input_dir.glob("*.tif"))
if not rasters:
raise FileNotFoundError(f"No tif rasters found in {input_dir}")
# 推荐指定一个基准栅格,让输出像元网格保持一致。
snap_raster = str(rasters[0])
arcpy.env.snapRaster = snap_raster
arcpy.env.cellSize = snap_raster
for raster_path in rasters:
in_raster = str(raster_path)
out_raster = str(output_dir / f"{raster_path.stem}_clip.tif")
print(f"Clipping: {raster_path.name}")
arcpy.management.Clip(
in_raster=in_raster,
rectangle="#",
out_raster=out_raster,
in_template_dataset=boundary,
nodata_value="#",
clipping_geometry="ClippingGeometry",
maintain_clipping_extent="MAINTAIN_EXTENT"
)
print("Batch clip finished.")
这段脚本的关键在于 in_template_dataset 指向研究区边界,并且 clipping_geometry 设置为 ClippingGeometry。这样输出结果会按边界面裁剪,而不是只按边界外接矩形裁剪。
如果你的输入是 GRID、IMG 或地理数据库中的栅格,也可以调整文件筛选方式。核心思路不变:先列出输入数据,再逐个构造输出路径,最后把同一套裁剪参数应用到每个栅格。
arcpy栅格处理后的输出检查:不要只看脚本是否报错
很多输出问题不会在第一时间表现为脚本异常。例如输出文件存在,但范围不对;像元数量明显偏少;整个结果都是 NoData;投影信息缺失;或者某一期数据因为源文件范围不覆盖研究区而得到空结果。因此,批处理脚本最好在裁剪后追加检查步骤。
下面的检查函数会读取输出栅格的行列数、范围、空间参考和 NoData 情况。它不能替代人工抽查地图,但能快速发现大多数明显异常。
import arcpy
from pathlib import Path
def inspect_raster(raster_file):
desc = arcpy.Describe(str(raster_file))
result = arcpy.management.GetRasterProperties(str(raster_file), "ALLNODATA")
all_nodata = result.getOutput(0)
return {
"name": raster_file.name,
"width": desc.width,
"height": desc.height,
"spatial_reference": desc.spatialReference.name,
"extent": f"{desc.extent.XMin}, {desc.extent.YMin}, {desc.extent.XMax}, {desc.extent.YMax}",
"all_nodata": all_nodata
}
output_dir = Path(r"D:\gis_project\output_clip")
for out_file in sorted(output_dir.glob("*_clip.tif")):
info = inspect_raster(out_file)
print(info)
如果 all_nodata 返回结果提示整个栅格都是 NoData,需要优先检查输入栅格与边界是否重叠、裁剪边界坐标系是否正确,以及 NoData 值是否被错误设置。把这些检查加入脚本流程,比处理完几百个文件后再返工更可靠。
把裁剪结果写成 CSV 检查表
项目交付时,建议把每个输出栅格的检查结果保存成 CSV。这样不仅方便自己复核,也方便团队成员或甲方查看处理记录。下面的代码把输出文件名、行列数、坐标系、范围和全 NoData 状态写入检查表。
import csv
import arcpy
from pathlib import Path
output_dir = Path(r"D:\gis_project\output_clip")
report_csv = Path(r"D:\gis_project\logs\clip_check_report.csv")
report_csv.parent.mkdir(parents=True, exist_ok=True)
fields = ["name", "width", "height", "spatial_reference", "xmin", "ymin", "xmax", "ymax", "all_nodata"]
with report_csv.open("w", newline="", encoding="utf-8-sig") as f:
writer = csv.DictWriter(f, fieldnames=fields)
writer.writeheader()
for raster_file in sorted(output_dir.glob("*_clip.tif")):
desc = arcpy.Describe(str(raster_file))
all_nodata = arcpy.management.GetRasterProperties(str(raster_file), "ALLNODATA").getOutput(0)
writer.writerow({
"name": raster_file.name,
"width": desc.width,
"height": desc.height,
"spatial_reference": desc.spatialReference.name,
"xmin": desc.extent.XMin,
"ymin": desc.extent.YMin,
"xmax": desc.extent.XMax,
"ymax": desc.extent.YMax,
"all_nodata": all_nodata
})
print(f"Report saved: {report_csv}")
这个检查表很值得保留。只要出现某个输出文件行列数异常、空间参考为 Unknown、范围明显偏离,检查表通常能比肉眼逐个打开图层更快定位问题。
常见错误和排查方法
输出栅格为空或全是 NoData
这通常不是裁剪工具本身的问题,而是输入栅格、裁剪边界或坐标系之间没有正确重叠。先在 ArcGIS Pro 中同时加载输入栅格和边界,确认它们是否出现在同一空间位置。不要只看图层能否显示,还要检查图层属性里的坐标系。
- 输入栅格和边界没有空间交集。
- 边界图层定义投影错误,把经纬度数据当成投影坐标使用。
- NoData 值设置不当,导致有效像元被当作无效值。
- 裁剪边界存在空几何或异常面。
输出范围看起来比边界大
栅格由规则像元组成,按面裁剪后,输出文件仍然会保留一个矩形外框。边界外的区域通常是 NoData。判断是否裁剪成功,不应只看图层外框,而要查看有效像元是否只保留在边界范围内。
不同输出栅格无法叠加计算
如果输出栅格的像元大小、起算点或行列数不同,后续做 Raster Calculator、分区统计或时间序列分析时可能出现错位。建议在批量裁剪前设置 snapRaster 和 cellSize,并在结果检查表中记录行列数和范围。
ArcPy Clip、Extract by Mask 和手动工具的选择
ArcGIS 里有多种裁剪栅格的方法。选择哪一种,取决于你是做一次性处理,还是需要长期复用的脚本流程。
| 方法 | 适合场景 | 注意点 |
|---|---|---|
| ArcPy Clip | 需要用脚本批量裁剪栅格,并控制输出路径和命名 | 要明确是否使用裁剪几何,以及环境参数是否统一 |
| Extract by Mask | Spatial Analyst 工作流中按掩膜提取栅格 | 需要相应扩展许可,适合和地图代数、重分类等分析串联 |
| ArcGIS Pro 手动 Clip Raster | 少量数据、临时检查、教学演示 | 不适合大量重复任务,参数一致性依赖人工记忆 |
如果只是裁一个 DEM 作为制图底图,手动工具足够。如果要处理长期积累的月度、季度或年度栅格,自动化脚本更合适,因为它能把输入、输出、参数和检查记录固定下来。
ArcPy批量裁剪交付前检查清单
处理完成后,建议按下面的清单做一次快速复核。它能覆盖大多数批量裁剪项目中的交付风险。
- 输入栅格数量与输出栅格数量一致。
- 输出文件名能追溯到原始输入文件名。
- 所有输出栅格都有有效空间参考。
- 输出行列数、范围和像元大小没有异常跳变。
- 检查表中没有全 NoData 结果,或已记录原因。
- 随机打开 3 到 5 个输出栅格,与边界叠加检查裁剪边缘。
- 如果后续要叠加计算,确认所有输出使用同一个 snap raster。
- 把脚本、边界、日志和输出目录一起归档,便于复现。
FAQ:批量裁剪和输出检查常见问题
这种批量裁剪适合处理哪些栅格数据?
它适合处理 DEM、遥感指数、分类栅格、气象栅格、土地覆盖、坡度坡向等数据。前提是这些栅格能被 ArcGIS 正常读取,并且与裁剪边界存在空间重叠。
arcpy批量裁剪和在 ArcGIS Pro 里逐个裁剪有什么区别?
它把输入扫描、参数设置、输出命名和结果检查写进脚本,适合重复任务和项目交付。手动裁剪更适合少量数据或临时验证,但面对大量栅格时,容易出现参数不一致和结果遗漏。
arcpy批处理时一定要设置 snapRaster 吗?
不是所有批处理脚本都必须设置 snapRaster,但如果输出栅格后续要叠加、相减、统计或做时间序列分析,建议设置。它能减少像元网格错位问题,让批量结果更适合继续分析。
arcpy栅格处理输出全是 NoData 怎么办?
先检查输入栅格和边界是否真正重叠,再检查坐标系定义是否正确。然后查看裁剪参数里的 NoData 值、裁剪几何设置和边界几何质量。脚本没有报错并不代表结果有效,所以最好输出 CSV 检查表。
能不能按多个行政区分别输出?
可以。思路是在栅格循环外再增加一个行政区要素循环,按区县名称或编码构造输出文件夹和文件名。但要注意字段值中的空格、斜杠、括号等字符,最好先转成稳定的英文或数字编码,避免输出路径失败。
结语:把批量裁剪做成可复核流程
ArcPy批量裁剪的价值不只是节省点击时间,而是把重复的栅格处理任务变成稳定、可复现、可检查的流程。对真实项目来说,脚本能跑完只是第一步;输出数量、范围、坐标系、NoData 和像元对齐都经过检查,才算完成一次可靠的批处理。
如果你正在做长期遥感监测、流域分析、行政区统计或批量制图,把裁剪和检查写进同一个脚本,会比后期靠人工排错更稳。尤其在栅格处理任务里,规范的输出检查往往能提前发现最昂贵的返工问题。
-
QGIS虚拟图层SQL查询:连接表和空间筛选 2026-06-13 01:55:21
-
DEM流向:水文分析和流域划分前处理 2026-06-13 01:50:34
-
无人机正射影像:航测正射和影像正射流程 2026-06-12 22:19:43
-
无人机航测精度:像控点布设和飞行高度计算 2026-06-12 20:49:03
-
OpenLayers点击事件:图层点击事件和坐标拾取 2026-06-12 01:38:49
-
QGIS Processing报错:Processing错误和处理工具箱打不开 2026-06-11 20:55:46
-
Sentinel2云掩膜:大气校正、GEE去云和NDVI检查 2026-06-11 13:42:34
-
ArcGIS Pro字段计算器:数值涵义和顺序编号 2026-06-11 11:39:27
-
ArcPy栅格计算:arcpy.sa和栅格计算器排查 2026-06-11 10:48:22
-
ArcPy字段计算:AddField、字段映射和更新游标 2026-06-11 09:49:34
-
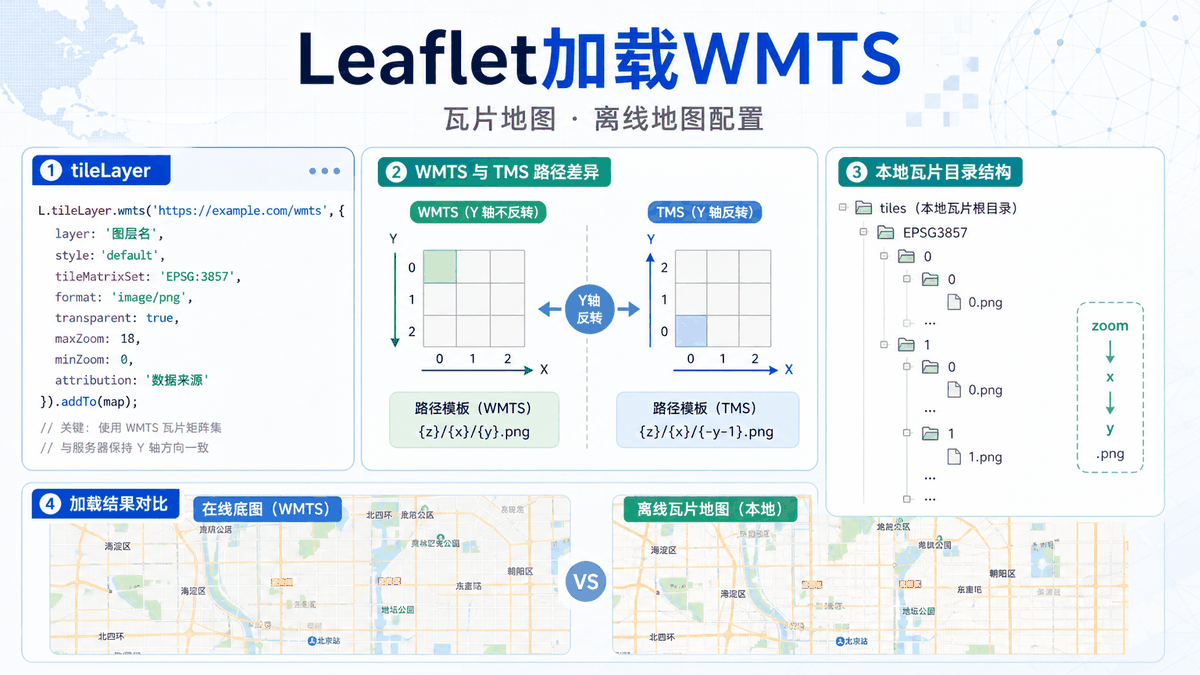
Leaflet加载WMTS:瓦片地图和离线地图配置 2026-06-11 03:40:08
-
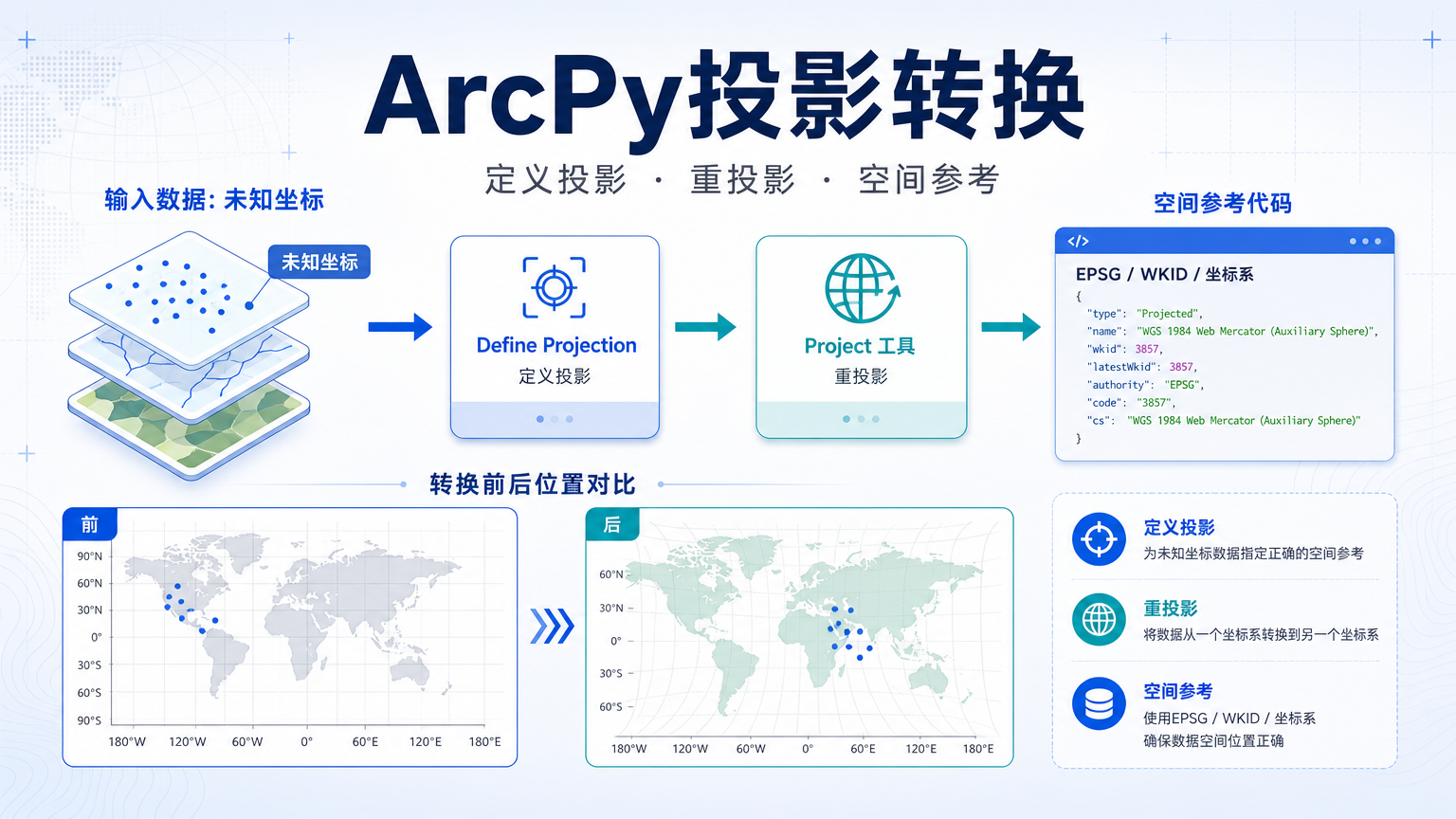
ArcPy投影转换:定义投影、重投影和空间参考 2026-06-10 20:51:20
-
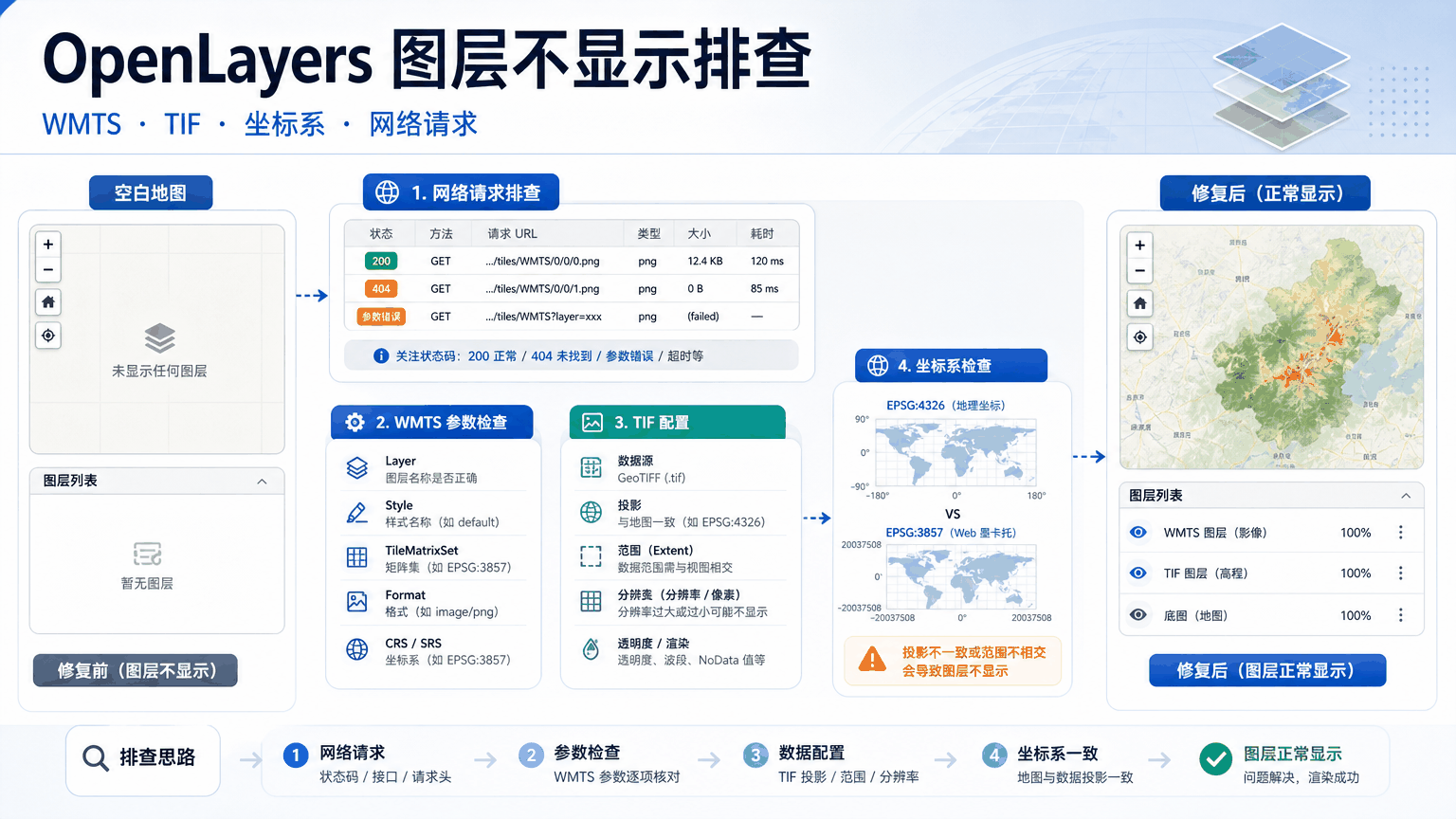
OpenLayers图层不显示:WMTS、TIF加载和原因排查 2026-06-10 19:22:44
-
GeoPandas裁剪:clip、读取SHP和GeoJSON裁剪流程 2026-06-10 08:45:06
-
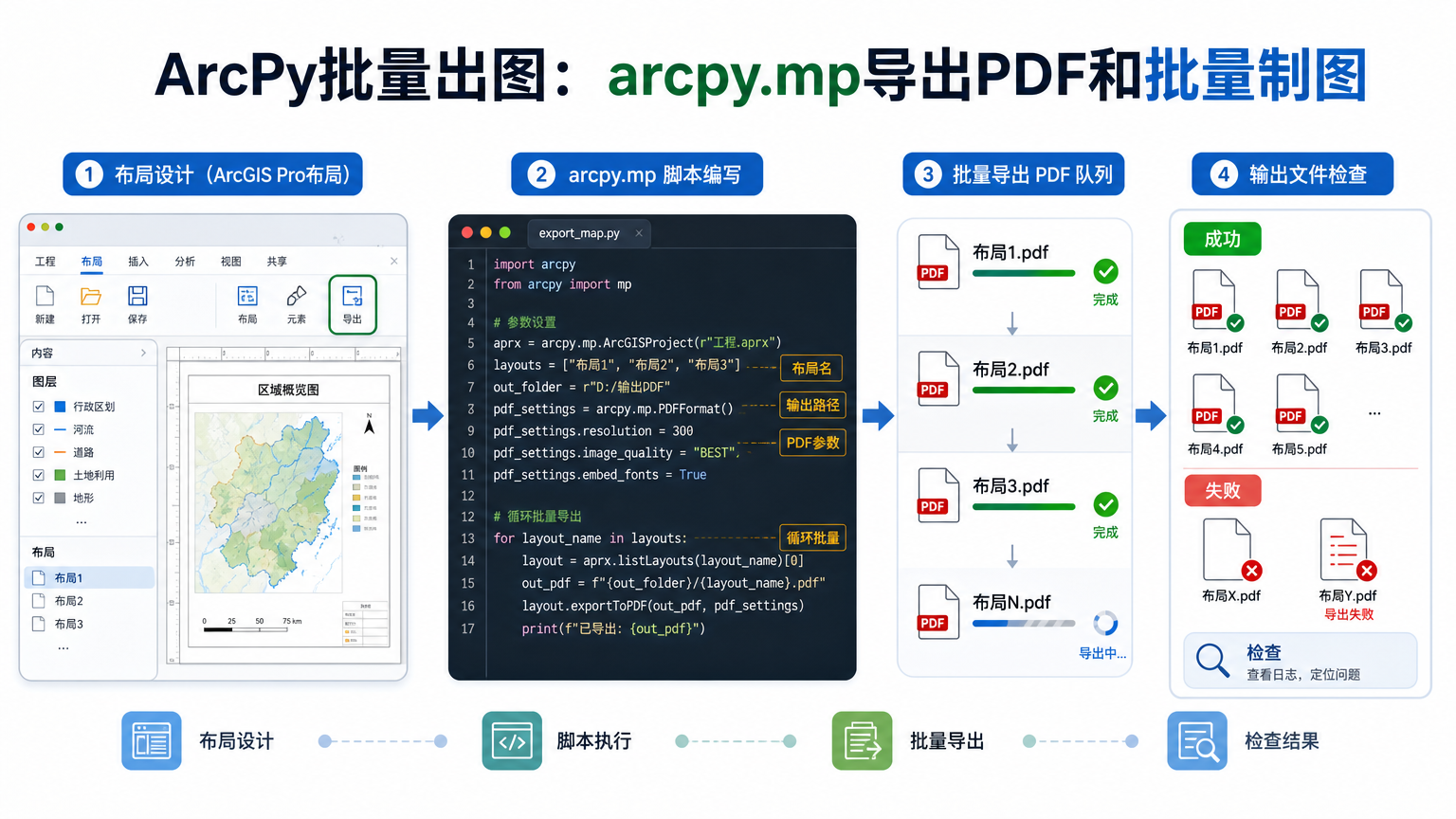
ArcPy批量出图:arcpy.mp导出PDF和批量制图 2026-06-10 08:40:05
-
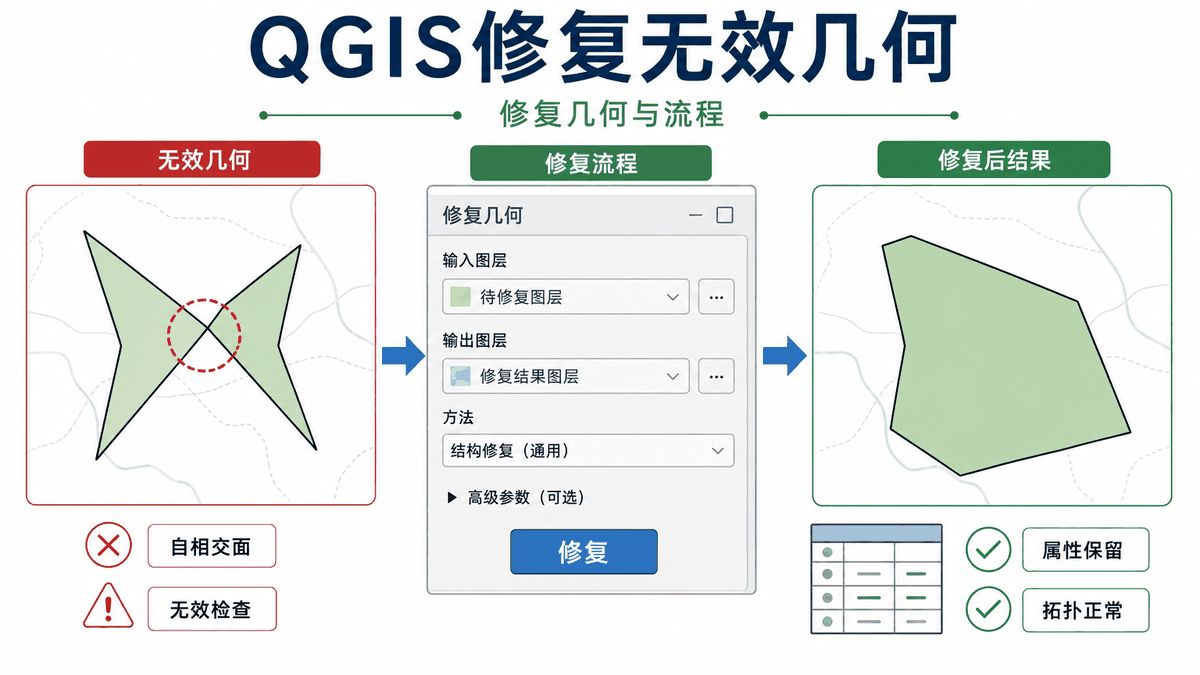
QGIS修复无效几何:修复几何和几何修复流程 2026-06-10 03:48:19
-
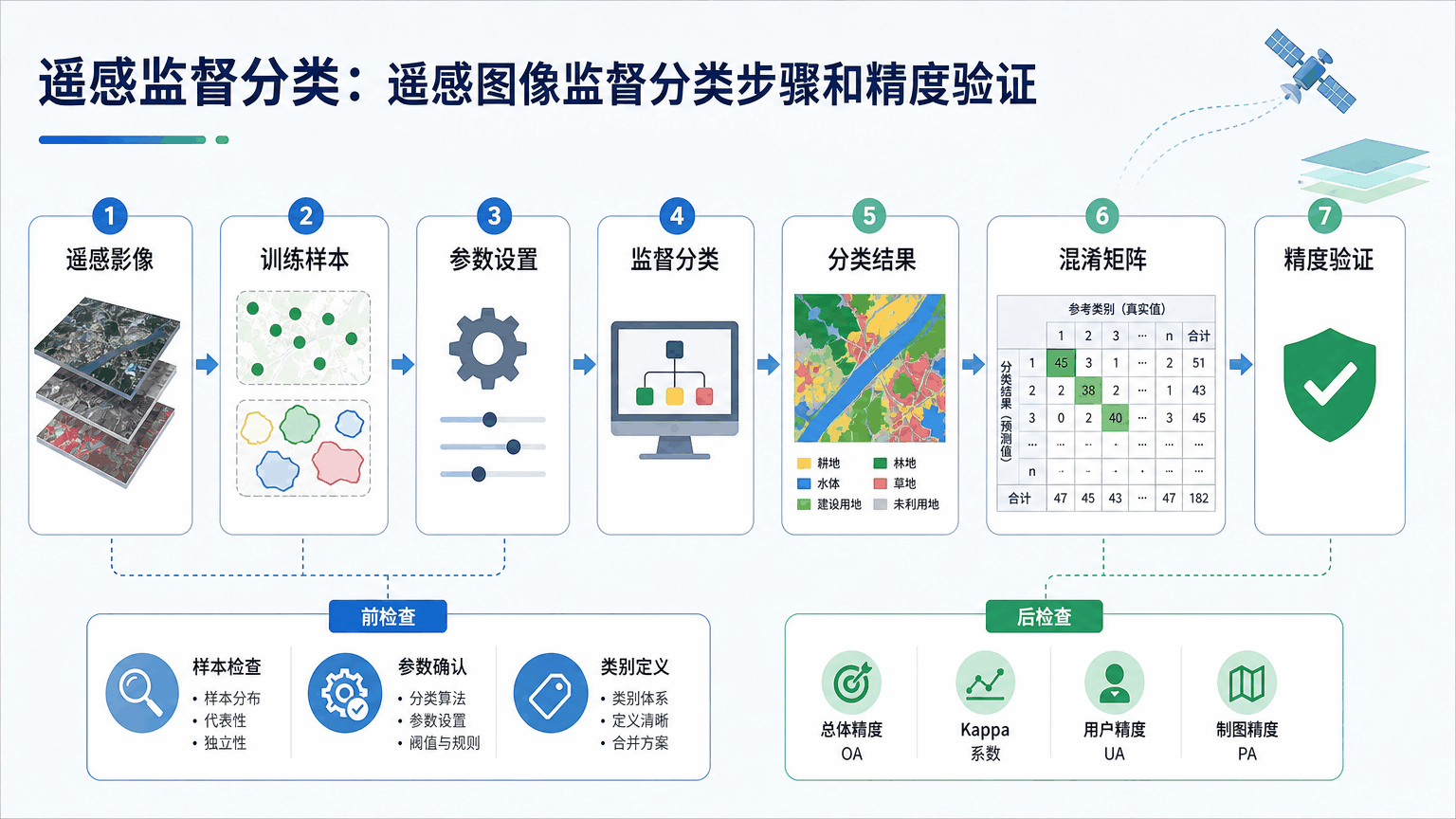
遥感监督分类:遥感图像监督分类步骤和精度验证 2026-06-09 18:16:55
-
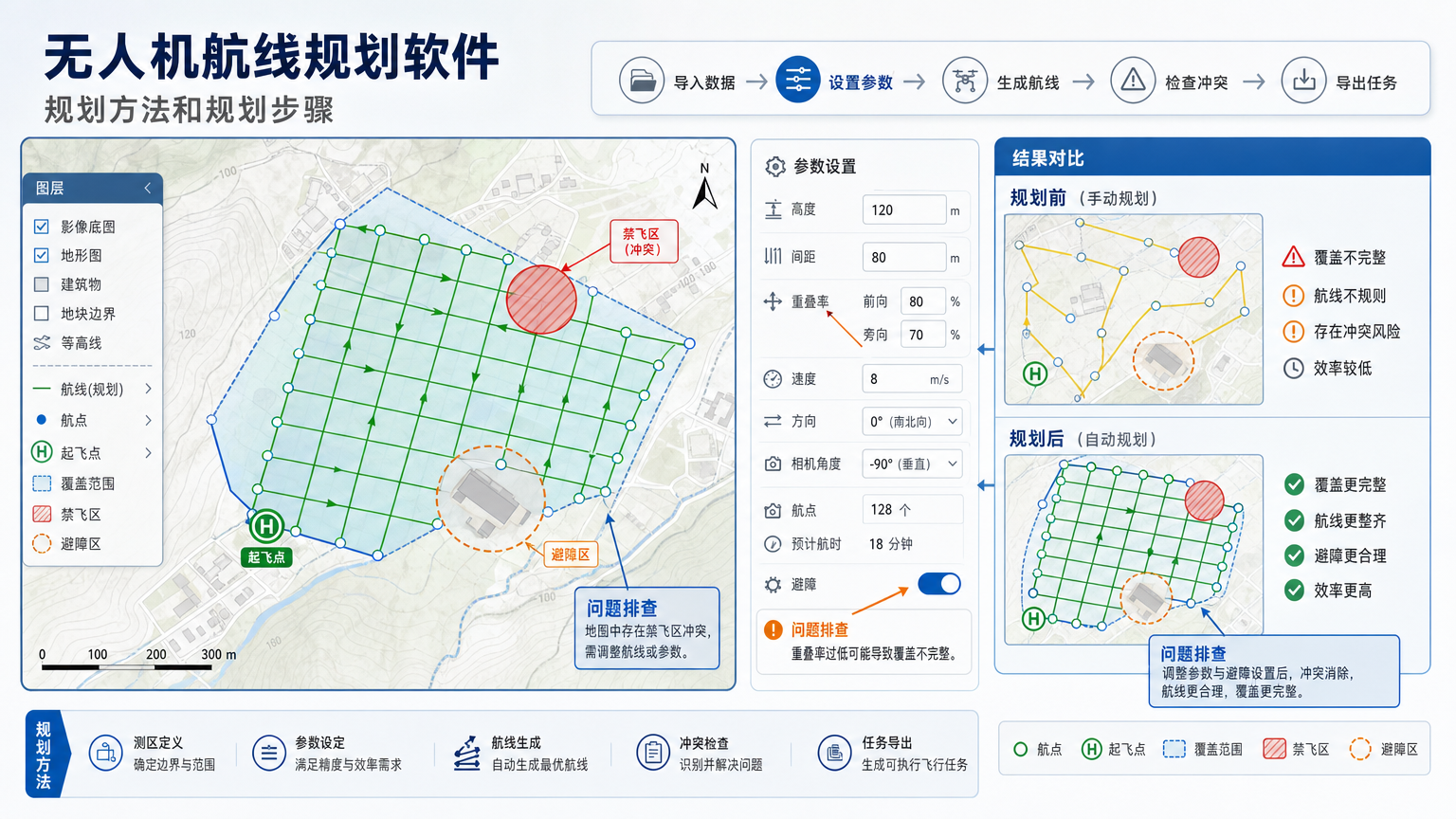
无人机航线规划软件:规划方法和规划步骤 2026-06-09 15:16:34
-
无人机测绘流程:软件有哪些、数据处理和精度 2026-06-09 13:32:14
-
Cesium影像加载失败:本地影像和TIF加载排查 2026-06-09 09:02:22