ArcPy字段计算:AddField、字段映射和更新游标
在地块入库、道路合并、POI清洗这类日常GIS项目里,ArcPy字段计算经常不是单独点一次“字段计算器”那么简单。更常见的情况是:先新增字段,再把不同来源的字段统一到一个输出字段,最后按业务规则逐行更新属性。
这篇文章用一个可复用的脚本思路,把 AddField、字段映射和更新游标串起来。读完后,你应该能判断什么时候用普通字段表达式,什么时候配置字段映射,什么时候必须改用更新游标。

ArcPy字段计算的典型问题背景
假设你有两个县区的道路数据,一个字段叫 ROAD_NAME,另一个字段叫 NAME;合并后还要新增一个 check_level 字段,用来标记主干路、支路和待核查道路。如果只依赖界面里的字段计算器,少量数据可以处理,但批量处理多个地理数据库时很难保持一致。
ArcPy字段计算要解决的核心问题有三个:字段是否存在,字段来源是否一致,字段值是否需要复杂判断。AddField 负责补齐字段结构,字段映射负责控制合并或转换时的字段去向,更新游标负责按行读取和写入更复杂的结果。
字段计算的核心原则:先处理字段结构,再处理字段值
很多字段计算失败,并不是表达式写错,而是字段结构没有准备好。例如目标字段不存在、字段类型是 TEXT 但你写入了数字、字段长度太短导致文本被截断,或者 shapefile 字段名超过了10个字符。
建议把脚本拆成三层:
- 字段结构层:检查字段是否存在,不存在就新增字段,并明确字段类型、长度和别名。
- 字段来源层:合并、追加、导出时,用字段映射把不同字段名统一到一个输出字段。
- 字段值层:简单表达式用 CalculateField,复杂条件、跨字段判断和逐行修正用更新游标。
用 arcpy.addfield_management 思路先补齐字段结构
搜索资料时经常会看到 arcpy.addfield_management 这个写法。需要注意的是,Python 对大小写敏感,传统脚本里更常见的是 arcpy.AddField_management,在 ArcGIS Pro 脚本中也可以使用 arcpy.management.AddField。实际项目里建议使用后者,代码更清晰。
下面示例给地块要素类新增一个亩数面积字段,然后用 CalculateField 完成一次基础的 arcpy字段计算。
import arcpy
fc = r"D:\gis\project\data.gdb\parcels"
field_name = "area_mu"
existing_fields = [field.name.lower() for field in arcpy.ListFields(fc)]
if field_name.lower() not in existing_fields:
arcpy.management.AddField(fc, field_name, "DOUBLE")
arcpy.management.CalculateField(
fc,
field_name,
"!shape.area@SQUAREMETERS! / 666.6667",
"PYTHON3"
)这个例子适合投影坐标系下的面要素。如果数据仍是经纬度坐标系,SHAPE面积的单位不是平方米,计算结果就会失真。正确做法是先投影到合适的平面坐标系,再计算面积。
从 arcpy字段计算 到 CalculateField:适合固定表达式
CalculateField 适合“一条规则应用到所有记录”的场景,例如统一写入数据来源、拼接行政区划代码、根据一个数值字段生成比例值。它的优点是脚本短、执行逻辑明确,缺点是不适合写太多分支条件。
fc = r"D:\gis\project\data.gdb\roads"
if "source_tag" not in [field.name.lower() for field in arcpy.ListFields(fc)]:
arcpy.management.AddField(fc, "source_tag", "TEXT", field_length=30)
arcpy.management.CalculateField(
fc,
"source_tag",
"'survey_2026'",
"PYTHON3"
)如果字段表达式开始出现多层 if、多个字段互相判断、空值分支和异常值处理,就不要继续把逻辑塞进 CalculateField。此时可读性和调试成本都会变差,应改用更新游标。
用 arcpy字段映射 解决合并数据时的字段不一致
arcpy字段映射 常用于 Merge、Append、FeatureClassToFeatureClass 等数据整合流程。它解决的不是“字段值怎么算”,而是“输入字段应该进入哪个输出字段”。这一步做好了,后续计算才不会因为字段名混乱而反复写兼容逻辑。
下面示例把两个道路图层的道路名称字段统一输出为 road_name。
import arcpy
road_a = r"D:\gis\project\data.gdb\road_a"
road_b = r"D:\gis\project\data.gdb\road_b"
out_fc = r"D:\gis\project\result.gdb\road_merge"
field_mappings = arcpy.FieldMappings()
field_mappings.addTable(road_a)
field_mappings.addTable(road_b)
for old_name in ["ROAD_NAME", "NAME"]:
index = field_mappings.findFieldMapIndex(old_name)
if index != -1:
field_mappings.removeFieldMap(index)
name_map = arcpy.FieldMap()
name_map.addInputField(road_a, "ROAD_NAME")
name_map.addInputField(road_b, "NAME")
output_field = name_map.outputField
output_field.name = "road_name"
output_field.aliasName = "道路名称"
name_map.outputField = output_field
field_mappings.addFieldMap(name_map)
arcpy.management.Merge([road_a, road_b], out_fc, field_mappings)字段映射的关键是先想清楚输出表结构。不要等合并完成后再批量改字段名,因为那会让脚本依赖临时字段,后续维护成本更高。
用 arcpy更新游标 处理复杂条件赋值
当字段值依赖多列、几何面积、文本关键字或业务阈值时,arcpy更新游标 是更稳的选择。它逐行读取字段值,按 Python 逻辑判断后再写回记录,适合做质量检查、分类赋值和异常标记。
import arcpy
fc = r"D:\gis\project\result.gdb\road_merge"
if "check_level" not in [field.name.lower() for field in arcpy.ListFields(fc)]:
arcpy.management.AddField(fc, "check_level", "TEXT", field_length=20)
fields = ["road_name", "ROAD_TYPE", "SHAPE@LENGTH", "check_level"]
with arcpy.da.UpdateCursor(fc, fields) as cursor:
for road_name, road_type, length_m, check_level in cursor:
if road_name in (None, ""):
new_level = "名称缺失"
elif road_type == "主干路" and length_m > 3000:
new_level = "重点核查"
elif road_type in ("支路", "乡道"):
new_level = "常规检查"
else:
new_level = "待复核"
cursor.updateRow((road_name, road_type, length_m, new_level))这个写法比长表达式更容易调试。你可以在循环里临时打印 road_name、road_type 和 length_m,定位哪一类记录导致结果异常。
常见坑:字段类型、锁定和空值
- 字段名限制:文件地理数据库支持较长字段名,shapefile 字段名通常会被限制得更短,脚本迁移时要特别检查。
- 大小写问题:arcpy.addfield_management 是常见搜索写法,但脚本执行时要确认实际函数名,避免因为大小写导致 AttributeError。
- 字段类型错误:DOUBLE 字段不要写入中文分类文本,TEXT 字段也不要直接承接需要数值比较的结果。
- 图层锁定:ArcGIS Pro 中打开属性表、编辑会话或其他脚本占用数据时,AddField 和更新游标可能失败。
- 空值处理:CalculateField 和 UpdateCursor 都要考虑 None,尤其是道路名称、用途类型、面积长度这类基础字段。
- 几何单位:SHAPE@AREA 和 SHAPE@LENGTH 的单位取决于数据坐标系,不能默认就是平方米或米。
AddField、字段映射和更新游标怎么选
| 方法 | 解决的问题 | 适合场景 | 不适合场景 |
|---|---|---|---|
| arcpy.management.AddField 或 arcpy.AddField_management | 新增字段结构 | 批量补齐结果字段、检查字段是否存在 | 不能直接解决复杂赋值逻辑 |
| CalculateField | 固定表达式计算字段值 | 统一来源标记、简单数值换算、字符串拼接 | 多条件、多字段、多异常分支 |
| FieldMappings | 控制输入字段进入哪个输出字段 | 合并、追加、导出前统一字段结构 | 不负责逐行判断字段值 |
| UpdateCursor | 按行读取、判断和写回字段值 | 质量检查、分类赋值、复杂业务规则 | 只是简单常量赋值时会显得偏重 |
字段计算项目检查清单
- 先备份原始要素类,不要直接在唯一数据源上试脚本。
- 用 arcpy.ListFields 检查字段是否存在,避免重复 AddField。
- 确定字段类型、长度、别名和是否允许空值。
- 合并不同来源数据前,先设计输出字段表,再写字段映射。
- 面积、长度参与计算前,确认数据坐标系和单位。
- 先用少量样本运行字段计算脚本,再扩展到完整数据。
- UpdateCursor 写入前先打印几行结果,确认逻辑分支没有反。
- 脚本结束后随机抽查属性表,特别检查空值、极大值和字段被截断的记录。
FAQ:ArcPy字段计算常见问题
arcpy字段计算 和 ArcPy字段计算 有区别吗?
没有本质区别,前者更像搜索时的输入习惯,后者更符合 ArcPy 这个库名的大小写。实际写脚本时,函数名和字段名是否区分大小写,要以 Python 和数据源规则为准。
为什么 arcpy.addfield_management 新增字段后字段计算仍然失败?
常见原因是函数名大小写写错、字段已经存在但类型不对、数据被 ArcGIS Pro 锁定,或者刚新增的是 TEXT 字段却写入了数值表达式。建议先用 ListFields 打印字段名和字段类型,再运行字段计算。
arcpy字段映射 能不能替代 CalculateField?
不能完全替代。arcpy字段映射 主要控制字段结构和来源,例如把 ROAD_NAME 和 NAME 合并到 road_name;CalculateField 或更新游标才负责给字段写入新的计算值。
什么时候必须用 arcpy更新游标?
当规则依赖多个字段、需要处理 None、要根据面积长度分类,或需要把异常记录标记出来时,arcpy更新游标 更合适。它的脚本略长,但可读性和可调试性通常比复杂字段表达式更好。
ArcPy字段计算结果为空,应该先查哪里?
先查输入字段是否真的有值,再查表达式里的字段名是否拼错,然后确认字段类型是否能接收结果。如果涉及几何面积或长度,还要检查坐标系单位是否符合预期。
结论
稳定的 ArcPy字段计算 工作流,不是把所有逻辑都塞进一个表达式,而是先用 AddField 管好字段结构,再用字段映射统一输入来源,最后根据复杂程度选择 CalculateField 或更新游标。对于批量GIS数据处理,这种分层写法更容易复用,也更容易排查错误。
-
QGIS虚拟图层SQL查询:连接表和空间筛选 2026-06-13 01:55:21
-
DEM流向:水文分析和流域划分前处理 2026-06-13 01:50:34
-
无人机正射影像:航测正射和影像正射流程 2026-06-12 22:19:43
-
无人机航测精度:像控点布设和飞行高度计算 2026-06-12 20:49:03
-
OpenLayers点击事件:图层点击事件和坐标拾取 2026-06-12 01:38:49
-
QGIS Processing报错:Processing错误和处理工具箱打不开 2026-06-11 20:55:46
-
Sentinel2云掩膜:大气校正、GEE去云和NDVI检查 2026-06-11 13:42:34
-
ArcGIS Pro字段计算器:数值涵义和顺序编号 2026-06-11 11:39:27
-
ArcPy栅格计算:arcpy.sa和栅格计算器排查 2026-06-11 10:48:22
-
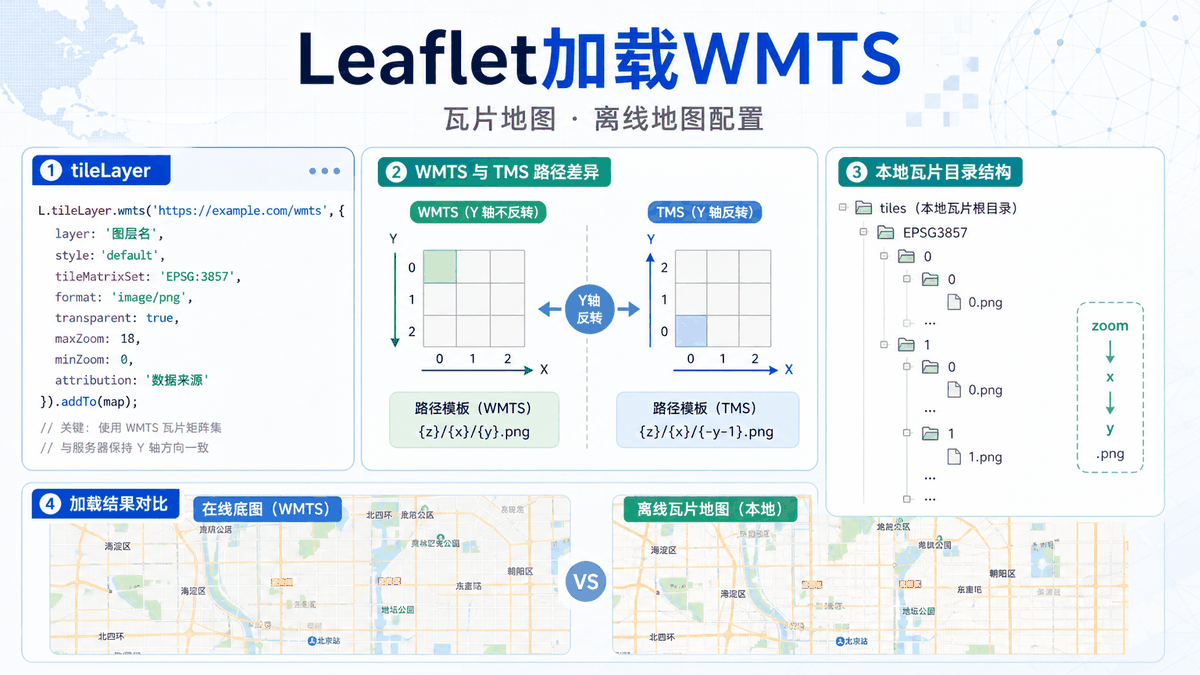
Leaflet加载WMTS:瓦片地图和离线地图配置 2026-06-11 03:40:08
-
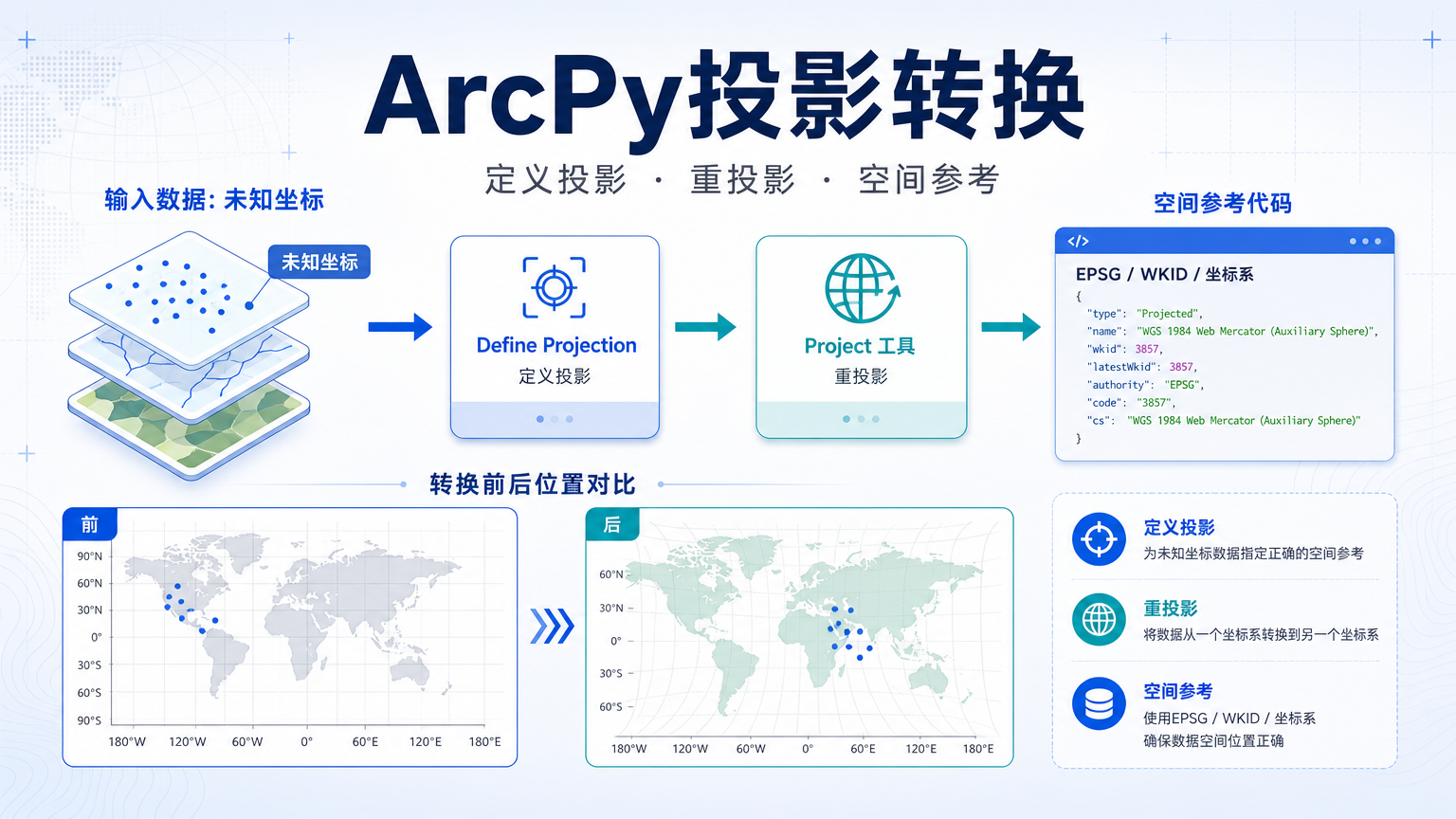
ArcPy投影转换:定义投影、重投影和空间参考 2026-06-10 20:51:20
-
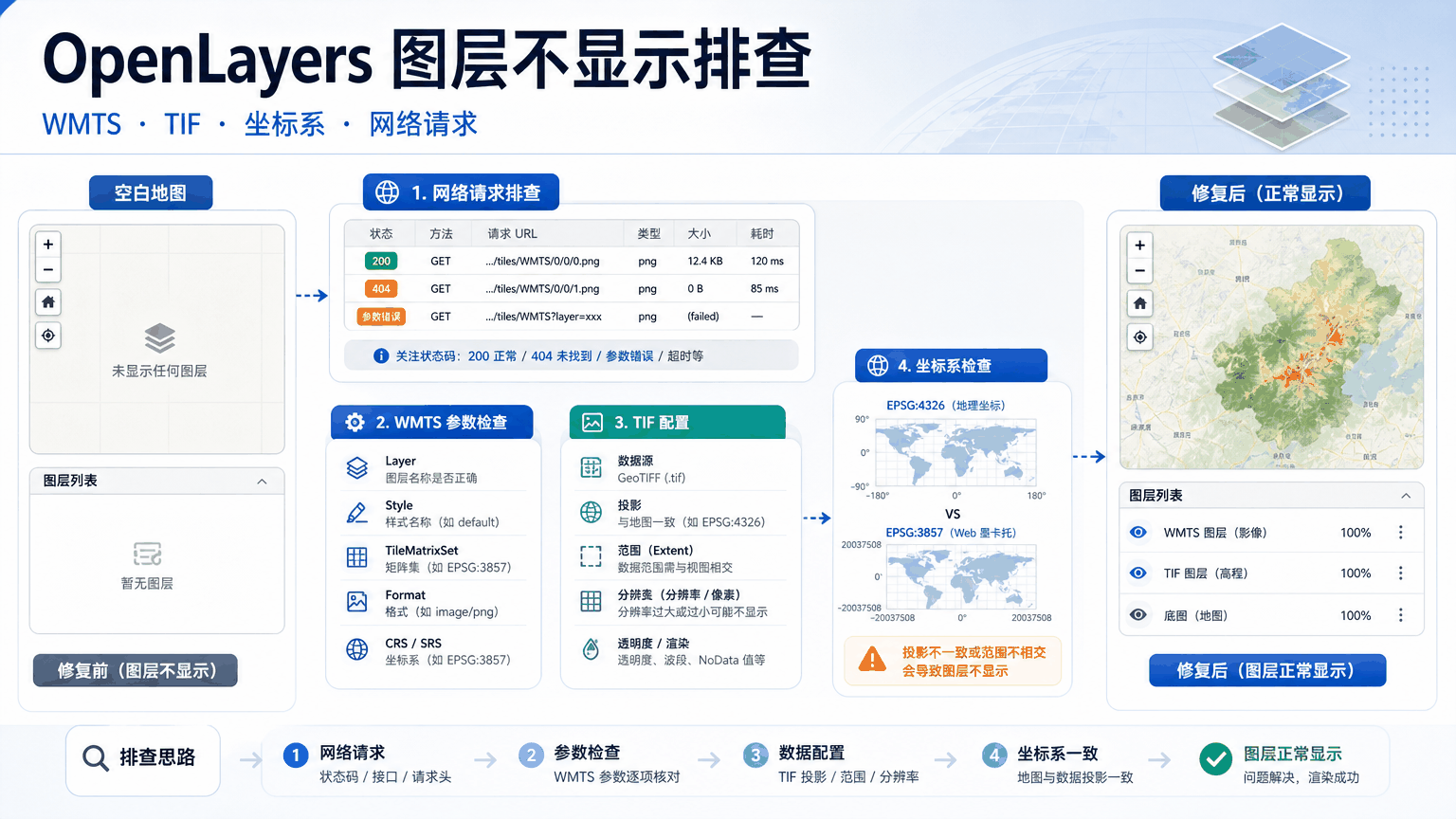
OpenLayers图层不显示:WMTS、TIF加载和原因排查 2026-06-10 19:22:44
-
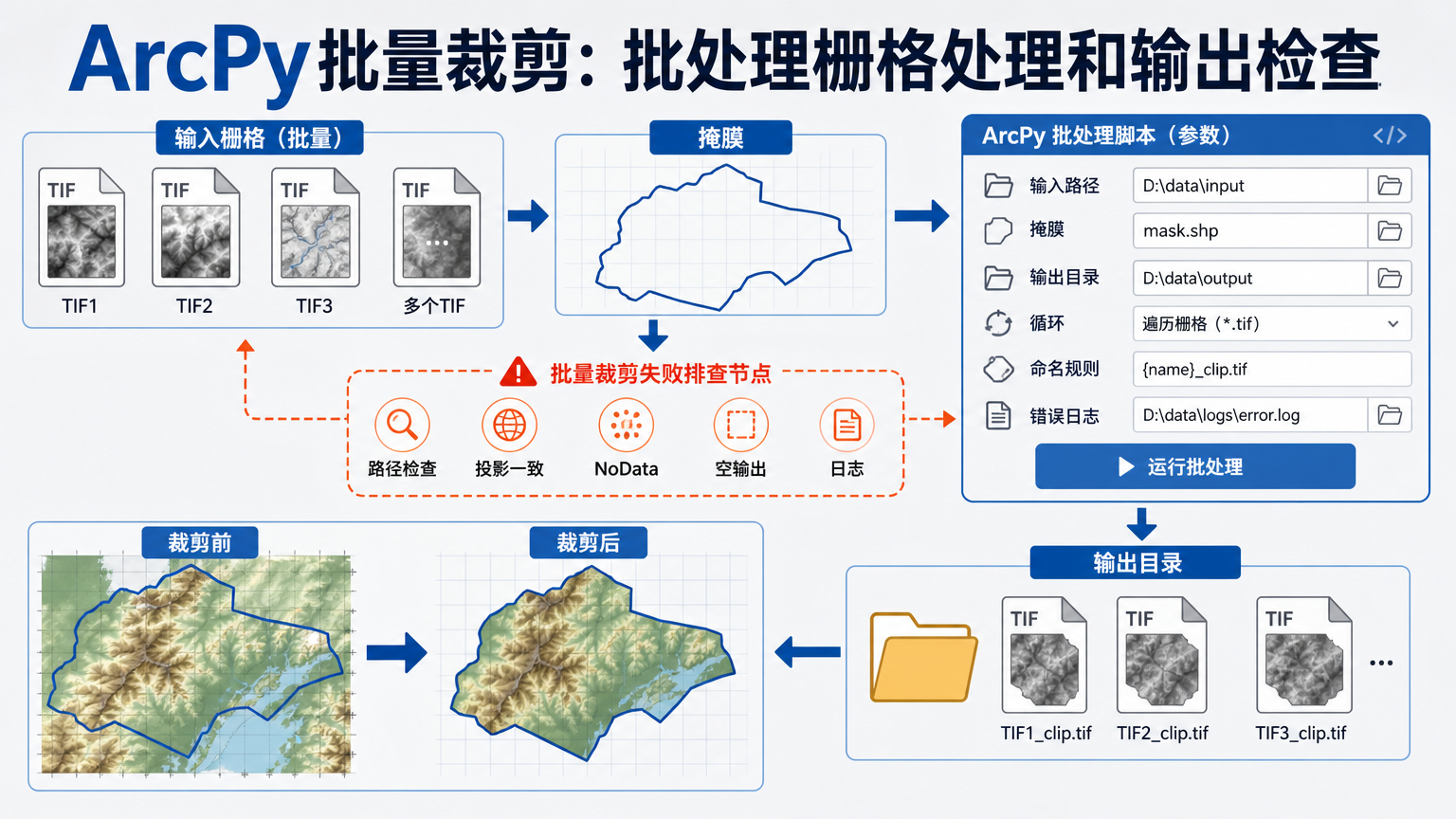
ArcPy批量裁剪:批处理栅格处理和输出检查 2026-06-10 18:47:40
-
GeoPandas裁剪:clip、读取SHP和GeoJSON裁剪流程 2026-06-10 08:45:06
-
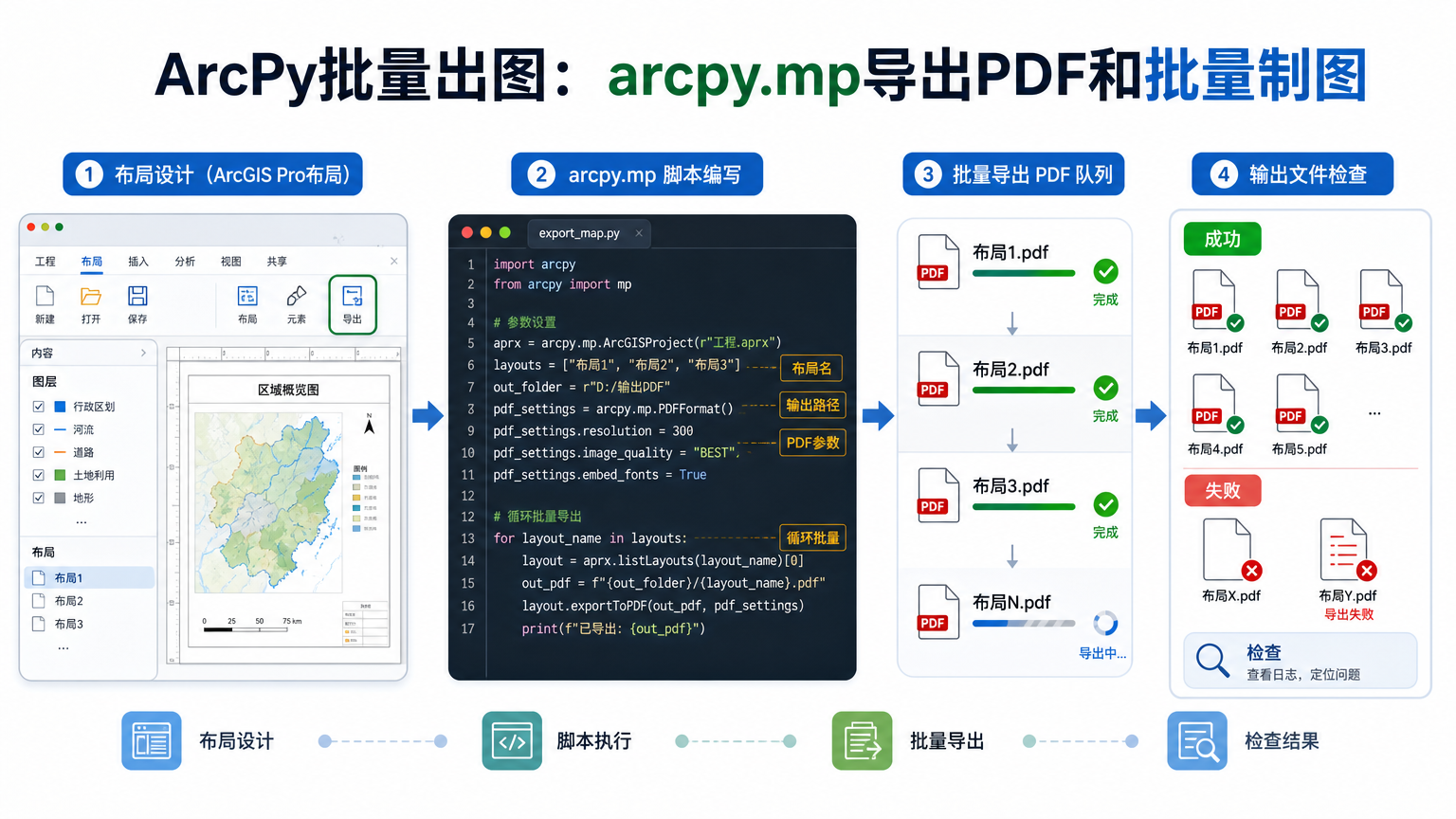
ArcPy批量出图:arcpy.mp导出PDF和批量制图 2026-06-10 08:40:05
-
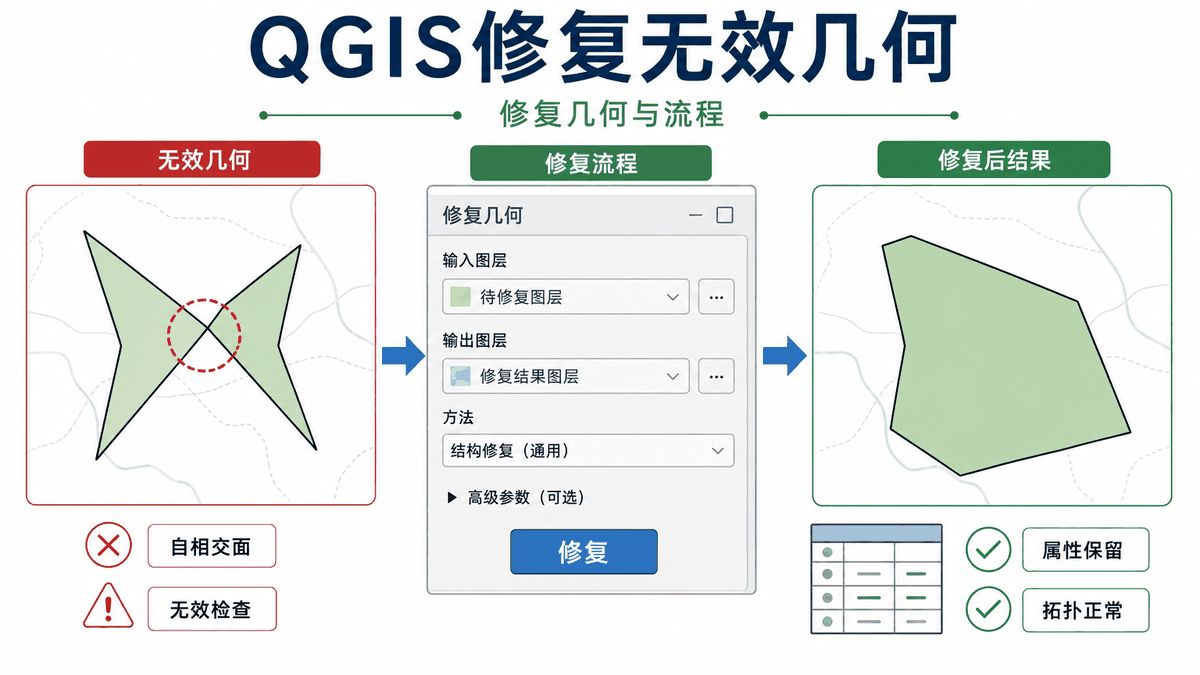
QGIS修复无效几何:修复几何和几何修复流程 2026-06-10 03:48:19
-
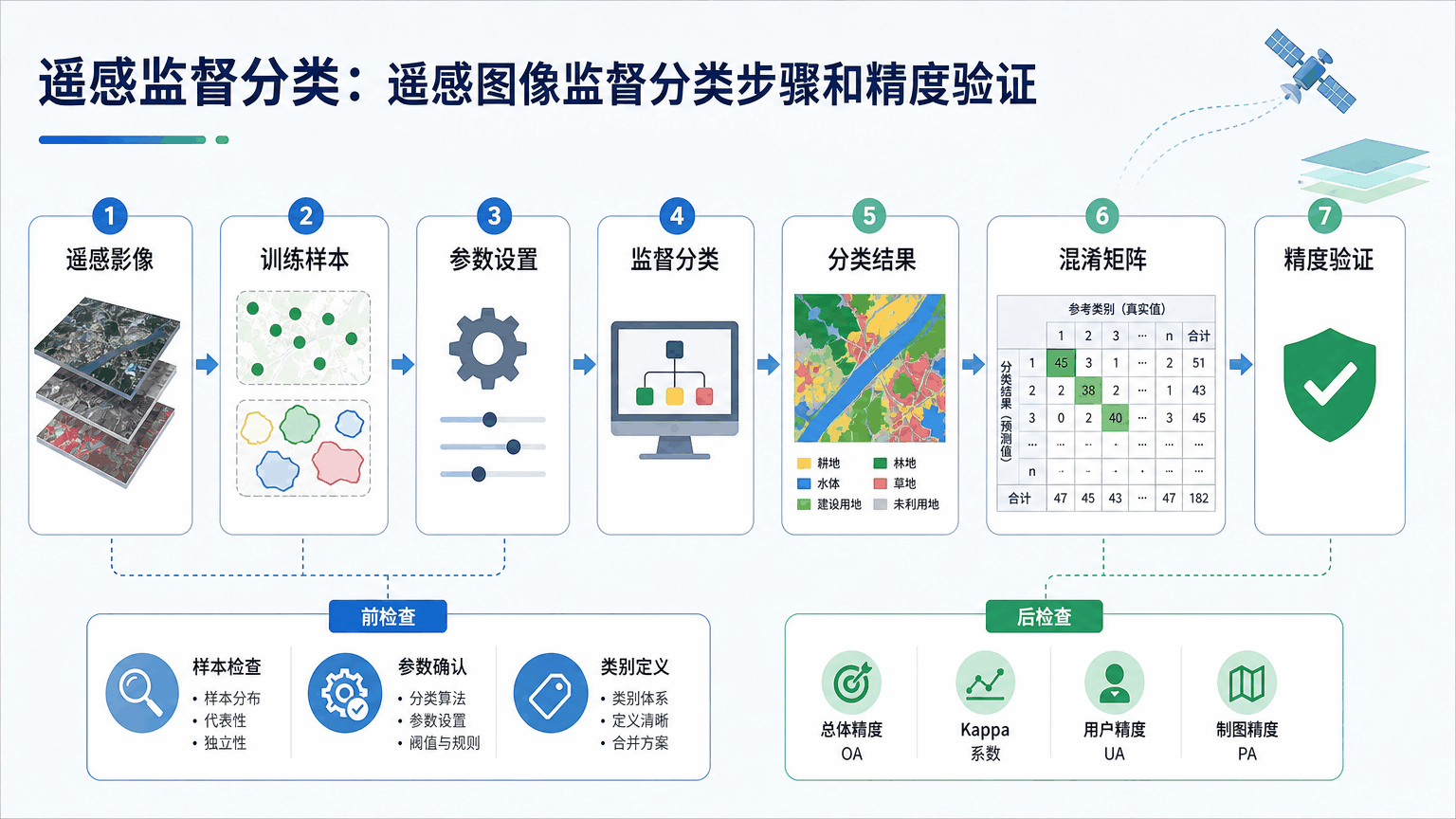
遥感监督分类:遥感图像监督分类步骤和精度验证 2026-06-09 18:16:55
-
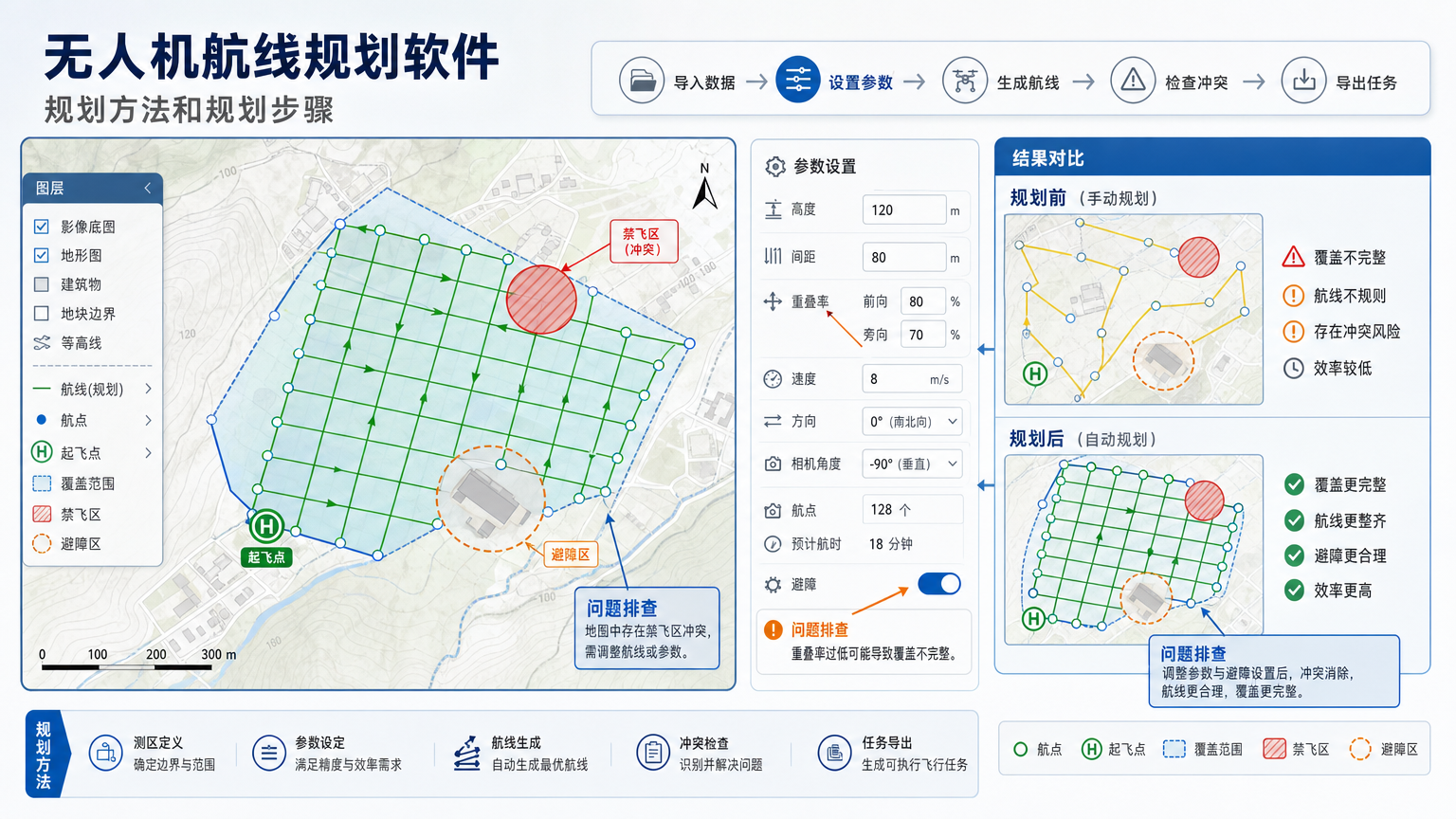
无人机航线规划软件:规划方法和规划步骤 2026-06-09 15:16:34
-
无人机测绘流程:软件有哪些、数据处理和精度 2026-06-09 13:32:14
-
Cesium影像加载失败:本地影像和TIF加载排查 2026-06-09 09:02:22