GeoPandas空间连接报错:sjoin报错和sjoin_nearest用法
GeoPandas空间连接报错:sjoin报错和sjoin_nearest用法
做 Python GIS 数据处理时,GeoPandas空间连接 常被用来把点落到行政区、把道路匹配到街道网格、把设施关联到最近的服务点。问题是,很多脚本一到 sjoin 或 sjoin_nearest 就报错:有的是参数名不兼容,有的是坐标系不一致,有的是最近距离看起来完全不对。
本文从一个真实项目场景出发:我们有一份 POI 点数据、一份区县面数据和一份公交站点数据,需要先判断每个 POI 属于哪个区县,再找出最近公交站。围绕这个任务,系统梳理 GeoPandas空间连接报错 的排查方法、GeoPandas sjoin报错 的常见原因,以及 GeoPandas sjoin_nearest 的正确用法。
问题背景:为什么GeoPandas空间连接报错很常见
GeoPandas 的空间连接看起来像 pandas 的 merge,但它不是按字段相等匹配,而是按几何关系匹配。只要几何列、坐标系、空间谓词、索引列或距离单位有一个环节不对,就可能得到报错、空结果或重复结果。
常见场景包括:
- 点和面数据的 CRS 不一致,脚本仍然直接执行空间连接。
- 复制了旧教程里的
op="intersects",当前环境提示参数错误。 - 用经纬度坐标做最近距离,
distance_col输出的是度,不是米。 - 左表或右表不是
GeoDataFrame,或者没有有效的活动几何列。 - 原始面数据存在无效几何、空几何、重复面或相互重叠面。
- 原表已经有
index_right这类连接过程会使用的列名,导致列冲突。
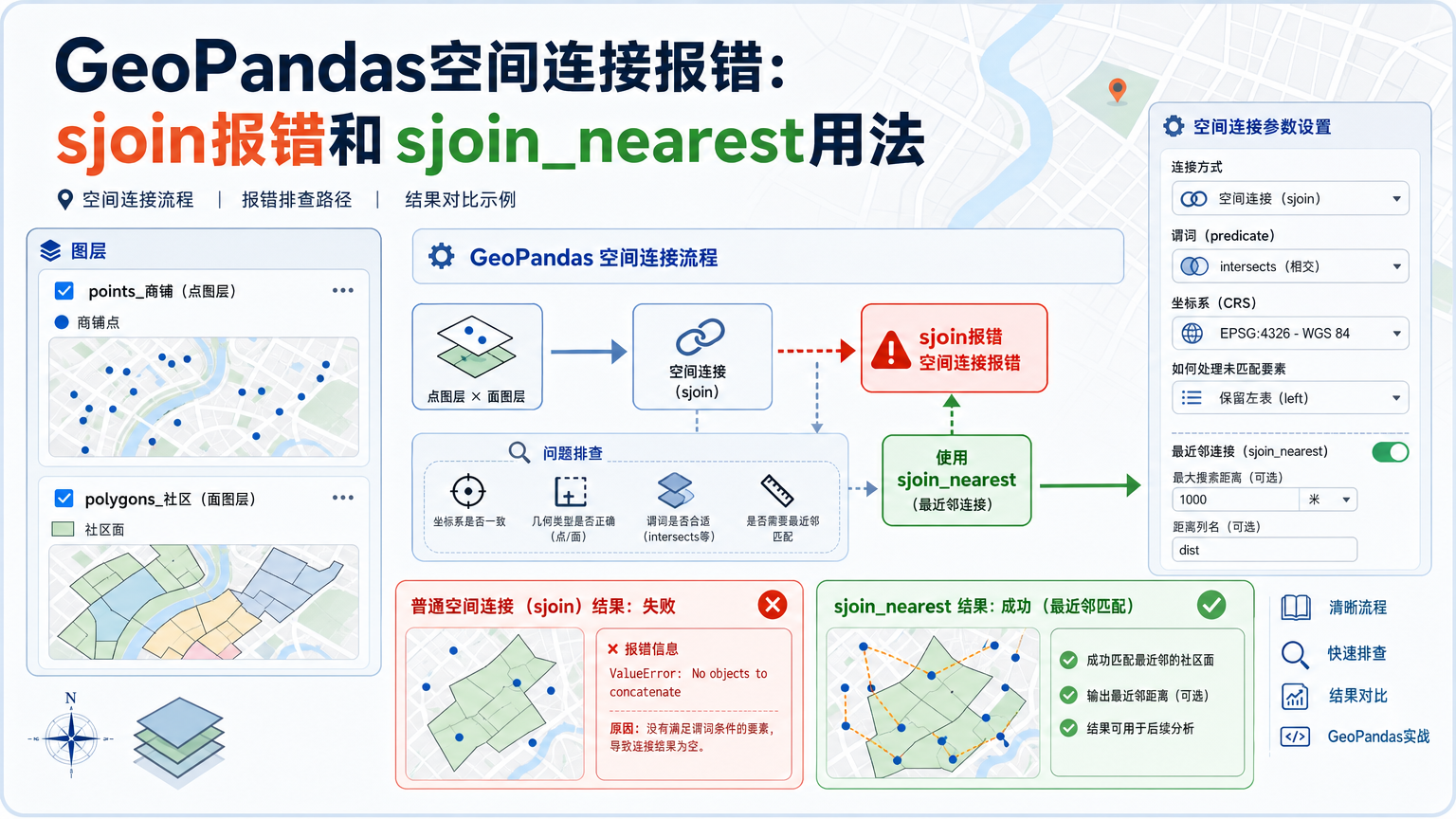
因此,解决 GeoPandas空间连接报错 不能只盯着最后一行错误信息。更稳的方法是先把数据状态检查清楚,再根据空间关系选择合适的连接函数。
核心原理:sjoin和sjoin_nearest不是同一种空间连接
sjoin 适合“满足某种几何关系就连接”的任务。例如点是否在面内、两条线是否相交、一个面是否包含另一个面。它的核心参数是 how 和 predicate。how 控制保留左表、右表还是交集索引,predicate 控制空间关系,例如 intersects、within、contains。
sjoin_nearest 适合“找最近对象”的任务。例如给每个小区找最近地铁站、给每个采样点找最近河流、给每个客户点找最近网点。它不依赖 predicate,而是按几何距离匹配,常用参数是 max_distance 和 distance_col。
简单判断:如果业务规则是“相交、包含、落在内部”,优先用
sjoin;如果业务规则是“最近、距离最短、限定搜索半径”,优先用sjoin_nearest。
还有一个必须记住的原则:GeoPandas 的几何运算是平面运算。做 GeoPandas sjoin_nearest 时,距离按当前 CRS 的单位计算。如果数据还在 EPSG:4326 经纬度坐标系中,距离单位就是度,不能直接当作米使用。
第一步:先检查GeoDataFrame、几何列和CRS
排查 GeoPandas空间连接报错 时,不建议一上来就改参数。先用一个小检查函数确认两份数据是否适合连接。
import geopandas as gpd
poi = gpd.read_file("data/poi.gpkg")
districts = gpd.read_file("data/districts.gpkg")
stations = gpd.read_file("data/bus_stations.gpkg")
def check_gdf(name, gdf):
print(f"--- {name} ---")
print(type(gdf))
print("crs:", gdf.crs)
print("active geometry:", gdf.geometry.name)
print("rows:", len(gdf))
print("empty geometry:", int(gdf.geometry.is_empty.sum()))
print("missing geometry:", int(gdf.geometry.isna().sum()))
print("invalid geometry:", int((~gdf.geometry.is_valid).sum()))
print("valid predicates:", gdf.sindex.valid_query_predicates)
check_gdf("poi", poi)
check_gdf("districts", districts)
check_gdf("stations", stations)这个检查能提前发现几类高频问题:文件读成了普通 DataFrame、CRS 是空值、几何列不是活动几何列、存在空几何或无效几何、当前空间索引不支持你想用的 predicate。
如果数据是 CSV 坐标点,需要先构造成 GeoDataFrame,不要直接拿经纬度字段去 sjoin。
import pandas as pd
df = pd.read_csv("data/poi.csv")
poi = gpd.GeoDataFrame(
df,
geometry=gpd.points_from_xy(df["lon"], df["lat"]),
crs="EPSG:4326"
)如果数据已有几何列但 CRS 为空,只有在你确定原始坐标系时才能使用 set_crs。如果坐标系已经存在但需要变换到另一个坐标系,应该使用 to_crs。
# 只在明确知道原始坐标系时使用
poi = poi.set_crs("EPSG:4326")
# 已有 CRS,需要转换坐标时使用
districts = districts.to_crs(poi.crs)很多 GeoPandas sjoin报错 或空结果,根源就是把 set_crs 当成投影转换。set_crs 只是给数据贴标签,to_crs 才会真正改变坐标值。
GeoPandas sjoin报错:旧参数op要改成predicate
旧教程中经常看到这样的写法:
joined = gpd.sjoin(poi, districts, how="left", op="within")在较新的 GeoPandas 写法中,空间关系参数应使用 predicate。如果你遇到 GeoPandas sjoin报错,错误信息里出现 unexpected keyword argument 'op',通常就是复制了旧参数。
joined = poi.sjoin(
districts[["district_id", "district_name", "geometry"]],
how="left",
predicate="within",
rsuffix="district"
)建议优先使用 GeoDataFrame.sjoin() 方法式写法。它能让左表和右表的关系更清楚:上面这段代码表示“以 POI 为左表,把每个点落入的区县属性连接过来”。
如果不确定当前环境支持哪些 predicate,可以直接查看空间索引。
print(poi.sindex.valid_query_predicates)
print(districts.sindex.valid_query_predicates)常见谓词含义如下:
| predicate | 适合场景 | 容易踩坑的点 |
|---|---|---|
intersects |
只要几何相交就匹配,点在线上、点在面内、边界接触都可能匹配 | 结果可能比预期宽松,边界点也可能被连接 |
within |
点落在面内部,常用于 POI 归属行政区 | 点刚好在边界上时可能不算在面内 |
contains |
面包含点或小面,常用于以面表为左表统计内部对象 | 左右表方向反了会得到空结果 |
touches |
查找边界接触关系,例如相邻地块 | 不适合普通点落区县归属 |
overlaps |
两个同维度几何部分重叠,例如面与面重叠检查 | 点面关系通常不用这个谓词 |
标准写法:用sjoin把POI连接到行政区
假设 POI 和区县面已经有正确 CRS,最稳的点落面流程如下:
poi = gpd.read_file("data/poi.gpkg")
districts = gpd.read_file("data/districts.gpkg")
if poi.crs != districts.crs:
districts = districts.to_crs(poi.crs)
district_cols = ["district_id", "district_name", "geometry"]
poi_with_district = poi.sjoin(
districts[district_cols],
how="left",
predicate="within",
rsuffix="district"
)
poi_with_district = poi_with_district.drop(columns=["index_district"])
poi_with_district.to_file("output/poi_with_district.gpkg", driver="GPKG")这段代码选择 within,是因为业务问题是“点属于哪个面”。如果你把左右表换过来,用区县面作为左表,再写 within,语义就变成“区县面是否在点内”,自然会得到空结果。
如果项目中有部分点刚好落在行政区边界上,within 可能无法匹配。此时要根据业务规则决定是否改用 intersects,或者先对边界附近点做人工核验。不要简单为了“结果不为空”就把所有谓词都改成 intersects。
GeoPandas sjoin报错的常见原因和修复方法
下面这些错误,是写 GeoPandas空间连接 脚本时最常见的。
1. CRS mismatch:坐标系不一致
如果左表是 EPSG:4326,右表是 EPSG:3857,空间连接会出现警告、空结果或明显错误的匹配。修复方法是把两份数据转换到同一个 CRS。
print(poi.crs)
print(districts.crs)
if poi.crs != districts.crs:
districts = districts.to_crs(poi.crs)注意:如果 CRS 是 None,不能盲目 to_crs。先确认原始数据到底是什么坐标系,再用 set_crs 标注。
2. 左右表不是GeoDataFrame
如果数据从 pandas 表、数据库查询或 CSV 读入,可能只是普通表格,没有活动几何列。此时执行 sjoin 会失败。
print(type(poi))
print(poi.geometry.name)
poi = gpd.GeoDataFrame(poi, geometry="geometry", crs="EPSG:4326")如果几何字段是 WKT 字符串,还需要先解析成 Shapely 几何对象。
from shapely import wkt
df["geometry"] = df["wkt"].apply(wkt.loads)
gdf = gpd.GeoDataFrame(df, geometry="geometry", crs="EPSG:4326")3. index_right或字段名冲突
sjoin 会在结果中加入右表索引列。若原始数据中已经存在 index_right、index_left 或重复字段名,就可能触发列冲突。修复方式是提前重命名或删除不需要的列,并使用 lsuffix、rsuffix。
for col in ["index_right", "index_left"]:
if col in poi.columns:
poi = poi.drop(columns=[col])
if col in districts.columns:
districts = districts.drop(columns=[col])
result = poi.sjoin(
districts[["district_id", "name", "geometry"]],
how="left",
predicate="within",
lsuffix="poi",
rsuffix="district"
)4. 无效几何或空几何
面数据来自 CAD、手工编辑或格式转换时,可能存在自相交、空洞异常、空几何等问题。它们会让空间索引或几何关系判断不稳定。
districts = districts[~districts.geometry.isna()]
districts = districts[~districts.geometry.is_empty]
invalid_count = int((~districts.geometry.is_valid).sum())
print("invalid polygons:", invalid_count)
districts["geometry"] = districts.geometry.make_valid()如果你的环境暂时没有 make_valid,可在测试阶段用 buffer(0) 尝试修复简单自相交,但正式流程仍建议回到数据生产环节修面。
5. 空间谓词方向写反
点在面内时,通常写 poi.sjoin(districts, predicate="within")。如果左表是面、右表是点,则应改成 districts.sjoin(poi, predicate="contains")。左右表方向和谓词是一组规则,不能单独看。
# 点作为左表:点 within 面
poi_with_district = poi.sjoin(districts, how="left", predicate="within")
# 面作为左表:面 contains 点
district_with_poi = districts.sjoin(poi, how="left", predicate="contains")这类问题经常表现为没有报错,但结果全是空值,比直接报错更隐蔽。
GeoPandas sjoin_nearest用法:先投影,再找最近
GeoPandas sjoin_nearest 的第一原则是:如果你要解释距离,就先把数据转换到合适的投影坐标系。城市、省域、园区等局部项目,通常可以使用本地 UTM 或项目指定的米制投影。全国或跨大范围数据要更谨慎,不能随便用一个局部投影解释全域距离。
下面示例给每个 POI 找最近公交站,并输出距离列。
poi = gpd.read_file("data/poi.gpkg")
stations = gpd.read_file("data/bus_stations.gpkg")
if poi.crs != stations.crs:
stations = stations.to_crs(poi.crs)
metric_crs = poi.estimate_utm_crs()
poi_m = poi.to_crs(metric_crs)
stations_m = stations.to_crs(metric_crs)
nearest_station = poi_m.sjoin_nearest(
stations_m[["station_id", "station_name", "geometry"]],
how="left",
max_distance=3000,
distance_col="dist_m",
rsuffix="station"
)
nearest_station = nearest_station.to_crs(poi.crs)这里的 max_distance=3000 表示只在 3000 米搜索半径内找最近公交站。设置搜索半径不只是业务规则,也能减少需要评估的候选对象,在数据量较大时有明显意义。
distance_col="dist_m" 会把计算出的距离保存到结果字段。这个字段的单位来自当前 CRS。上面代码已经把数据转换到米制投影,因此 dist_m 才能按米理解。
sjoin_nearest结果重复或距离不对怎么处理
使用 GeoPandas sjoin_nearest 时,最容易遇到两个问题:同一个输入对象返回多条最近结果,以及距离值看起来不对。
重复结果通常不是 bug。如果多个右表几何到左表几何的距离完全相同,GeoPandas 可能返回多条等距最近记录。比如一个 POI 点恰好落在两个重叠服务区内,或者多个站点坐标重复。
nearest_station = poi_m.sjoin_nearest(
stations_m[["station_id", "station_name", "geometry"]],
how="left",
max_distance=3000,
distance_col="dist_m",
rsuffix="station"
)
duplicate_left = nearest_station.index[nearest_station.index.duplicated()]
print("duplicated input rows:", len(duplicate_left))如果业务只允许保留一条,可以先按距离、站点等级、站点名称或其他业务字段排序,再按左表索引去重。
nearest_station = nearest_station.sort_values(
["dist_m", "station_id"]
)
nearest_station = nearest_station[~nearest_station.index.duplicated(keep="first")]距离不对的常见原因是仍在 EPSG:4326 中计算。经纬度的坐标单位是度,不是米。正确做法是:先统一 CRS,再转换到适合区域范围的投影坐标系,最后运行 sjoin_nearest。
sjoin、sjoin_nearest、overlay和clip怎么选
很多 GeoPandas空间连接报错 来自方法选择错误。空间连接只是把属性按空间关系挂接过来,不会像叠置分析那样真正切割几何。如果你的目标是生成新的相交面,应该考虑 overlay;如果只是按边界裁剪要素,应该考虑 clip。
| 方法 | 解决的问题 | 是否生成新几何 | 典型用法 |
|---|---|---|---|
sjoin |
按相交、包含、落入等空间关系连接属性 | 通常保留左表或右表几何,不做几何切割 | POI 归属区县、地块匹配规划分区 |
sjoin_nearest |
按最近距离连接属性 | 保留连接侧几何,不生成最短线 | 小区找最近地铁站、采样点找最近河流 |
overlay |
真正执行几何叠置,生成相交、差集、并集等新几何 | 会生成新几何 | 用地现状与规划分区叠置分析 |
clip |
用边界裁剪空间数据 | 会裁剪几何 | 按研究区边界裁剪道路或土地利用 |
merge |
按普通字段连接表格属性 | 不执行空间关系判断 | 按行政区代码追加统计指标 |
如果只是想知道“这个点属于哪个区县”,用 sjoin;如果想知道“这个地块有多少面积落在某类规划区内”,用 overlay 更合适。
实战排查清单:从报错到正确结果
遇到 GeoPandas sjoin报错 时,可以按下面顺序排查。
- 确认左表和右表都是
GeoDataFrame,并且有活动几何列。 - 确认两份数据的
crs都不是空值。 - 确认两份数据 CRS 一致;不一致时使用
to_crs,不要误用set_crs。 - 检查空几何、缺失几何和无效几何,必要时先过滤或修复。
- 确认没有
index_right、index_left等冲突字段。 - 用
sindex.valid_query_predicates查看当前可用谓词。 - 根据左右表方向选择
within、contains或intersects。 - 如果使用
sjoin_nearest,先转换到米制投影 CRS,再设置max_distance和distance_col。 - 检查结果是否有重复索引;重复可能来自重叠面、边界点或等距最近对象。
- 把少量样本导出到 QGIS 里叠加查看,验证空间关系是否符合业务规则。
一个可靠的调试习惯是先抽取几十条样本跑通,再处理全量数据。空间连接错误往往在样本图上很直观:点是否落到面内、最近对象是否确实最近、坐标是否整体偏移,一眼就能发现。
可复用模板:完整的GeoPandas空间连接脚本
下面是一段更接近项目脚本的模板,包含点落区县和最近站点两步。你可以把字段名替换成自己的数据字段。
import geopandas as gpd
poi = gpd.read_file("data/poi.gpkg")
districts = gpd.read_file("data/districts.gpkg")
stations = gpd.read_file("data/bus_stations.gpkg")
def clean_for_join(gdf):
gdf = gdf.copy()
for col in ["index_left", "index_right"]:
if col in gdf.columns:
gdf = gdf.drop(columns=[col])
gdf = gdf[~gdf.geometry.isna()]
gdf = gdf[~gdf.geometry.is_empty]
if (~gdf.geometry.is_valid).any():
gdf["geometry"] = gdf.geometry.make_valid()
return gdf
poi = clean_for_join(poi)
districts = clean_for_join(districts)
stations = clean_for_join(stations)
if poi.crs is None:
raise ValueError("poi CRS is missing. Set it only after confirming the source CRS.")
if districts.crs is None:
raise ValueError("districts CRS is missing.")
if stations.crs is None:
raise ValueError("stations CRS is missing.")
districts = districts.to_crs(poi.crs)
stations = stations.to_crs(poi.crs)
poi_district = poi.sjoin(
districts[["district_id", "district_name", "geometry"]],
how="left",
predicate="within",
rsuffix="district"
)
metric_crs = poi.estimate_utm_crs()
poi_district_m = poi_district.to_crs(metric_crs)
stations_m = stations.to_crs(metric_crs)
result = poi_district_m.sjoin_nearest(
stations_m[["station_id", "station_name", "geometry"]],
how="left",
max_distance=3000,
distance_col="dist_to_station_m",
rsuffix="station"
)
result = result.sort_values(["dist_to_station_m", "station_id"])
result = result[~result.index.duplicated(keep="first")]
result = result.to_crs(poi.crs)
result.to_file("output/poi_join_result.gpkg", driver="GPKG")这个模板没有假设所有数据都完美,而是把清洗、CRS 检查、普通空间连接、最近距离连接和重复结果处理放在同一个流程里。对批量任务来说,这比临时改一行参数更稳定。
FAQ:GeoPandas空间连接报错常见问题
GeoPandas空间连接报错应该先看什么?
先看三件事:两边是否都是 GeoDataFrame,CRS 是否存在且一致,几何列是否为空或无效。多数 GeoPandas空间连接报错 都能在这三步里定位到原因。确认数据状态后,再检查 predicate、左右表方向和字段名冲突。
GeoPandas sjoin报错 unexpected keyword argument op 怎么办?
这是典型的旧参数问题。把 op="within"、op="intersects" 改成 predicate="within"、predicate="intersects"。同时建议使用 left_gdf.sjoin(right_gdf, how="left", predicate="within") 这种方法式写法,让左右表关系更清楚。
GeoPandas sjoin报错但结果不是空,是不是就正确?
不一定。空间连接可能没有报错,但因为谓词方向写反、CRS 被错误标注、面数据相互重叠,结果仍然不符合业务规则。做完 sjoin 后,应抽样在 QGIS 中叠加查看,并统计未匹配数量和重复匹配数量。
GeoPandas sjoin_nearest为什么距离不是米?
GeoPandas sjoin_nearest 的距离单位来自当前 CRS。如果数据在 EPSG:4326 经纬度坐标系中,距离单位是度。需要先用 to_crs 转换到合适的米制投影坐标系,再使用 distance_col 输出距离字段。
sjoin_nearest一定只返回一条最近记录吗?
不一定。如果多个候选几何与左表几何等距,或者几何本身相交且距离同为 0,sjoin_nearest 可能返回多条结果。若业务只保留一条,需要按距离和业务优先级排序后去重。
点落在两个行政区边界上,用within还是intersects?
如果业务要求严格“点在面内部”,用 within;如果边界点也要匹配,可考虑 intersects,但要接受边界处可能出现多匹配。行政归属类数据最好结合行政代码、人工校核或边界规则处理,不建议只靠一个谓词解决所有边界争议。
结论:把GeoPandas空间连接当作数据质量流程来做
GeoPandas空间连接 不是简单换一个函数名就能稳定运行。sjoin 解决的是空间关系匹配,sjoin_nearest 解决的是最近距离匹配;前者要选对 predicate 和左右表方向,后者要先处理好投影坐标系和距离单位。
遇到 GeoPandas sjoin报错,先检查 GeoDataFrame、CRS、几何有效性和字段冲突,再看参数。使用 GeoPandas sjoin_nearest 时,把数据转换到合适的米制 CRS,并用 max_distance 限定搜索范围。这样写出来的空间连接脚本,才适合在批量 GIS 数据处理中反复运行和交付。
-
QGIS虚拟图层SQL查询:连接表和空间筛选 2026-06-13 01:55:21
-
DEM流向:水文分析和流域划分前处理 2026-06-13 01:50:34
-
无人机正射影像:航测正射和影像正射流程 2026-06-12 22:19:43
-
无人机航测精度:像控点布设和飞行高度计算 2026-06-12 20:49:03
-
OpenLayers点击事件:图层点击事件和坐标拾取 2026-06-12 01:38:49
-
QGIS Processing报错:Processing错误和处理工具箱打不开 2026-06-11 20:55:46
-
Sentinel2云掩膜:大气校正、GEE去云和NDVI检查 2026-06-11 13:42:34
-
ArcGIS Pro字段计算器:数值涵义和顺序编号 2026-06-11 11:39:27
-
ArcPy栅格计算:arcpy.sa和栅格计算器排查 2026-06-11 10:48:22
-
ArcPy字段计算:AddField、字段映射和更新游标 2026-06-11 09:49:34
-
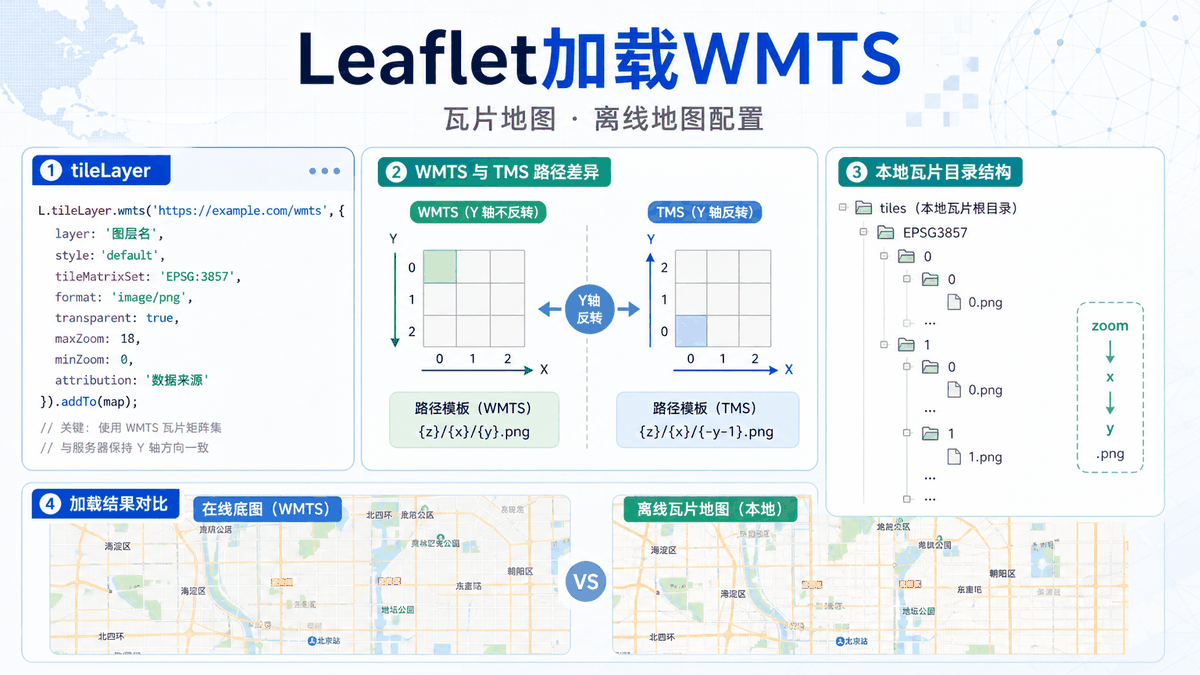
Leaflet加载WMTS:瓦片地图和离线地图配置 2026-06-11 03:40:08
-
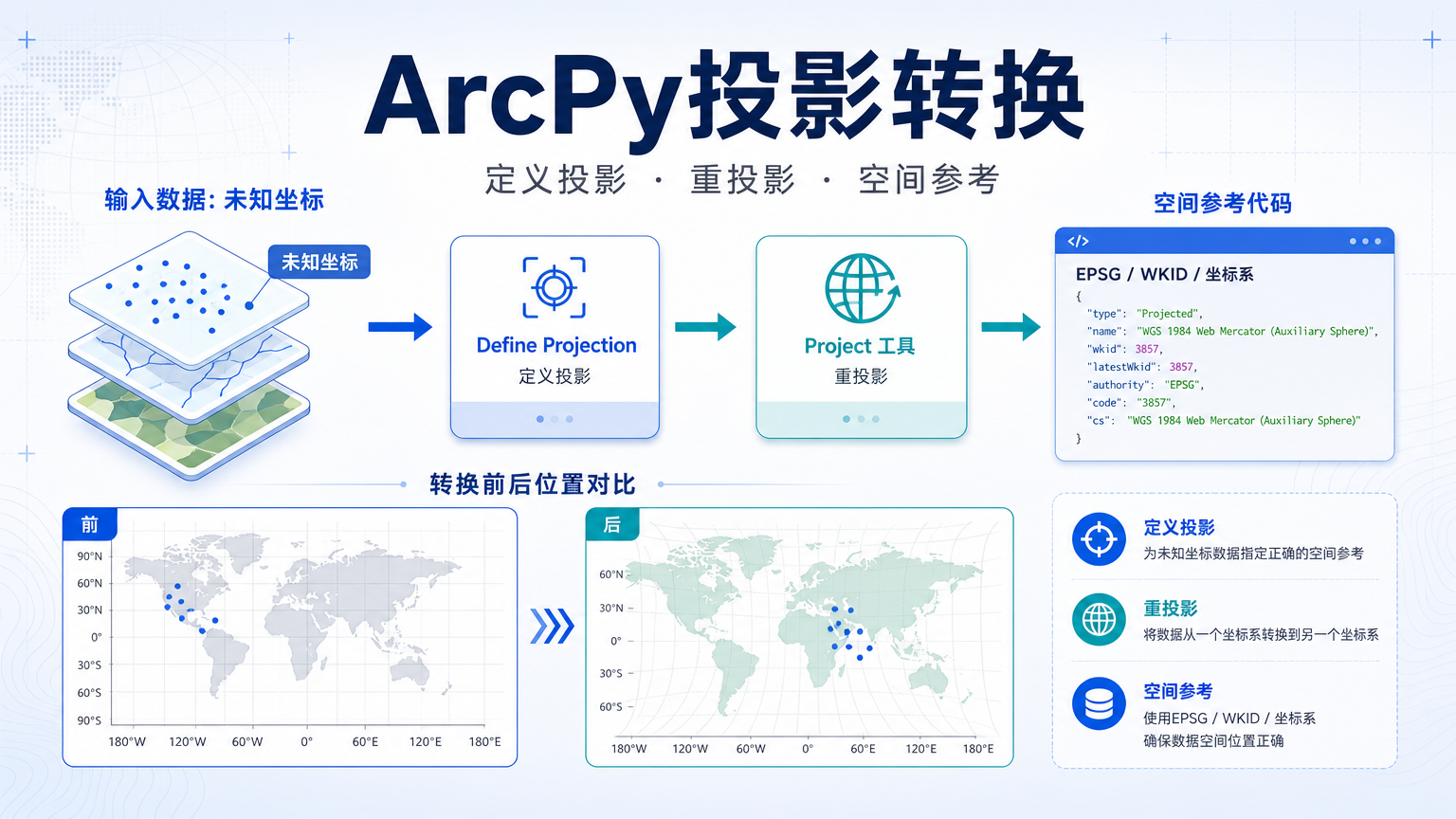
ArcPy投影转换:定义投影、重投影和空间参考 2026-06-10 20:51:20
-
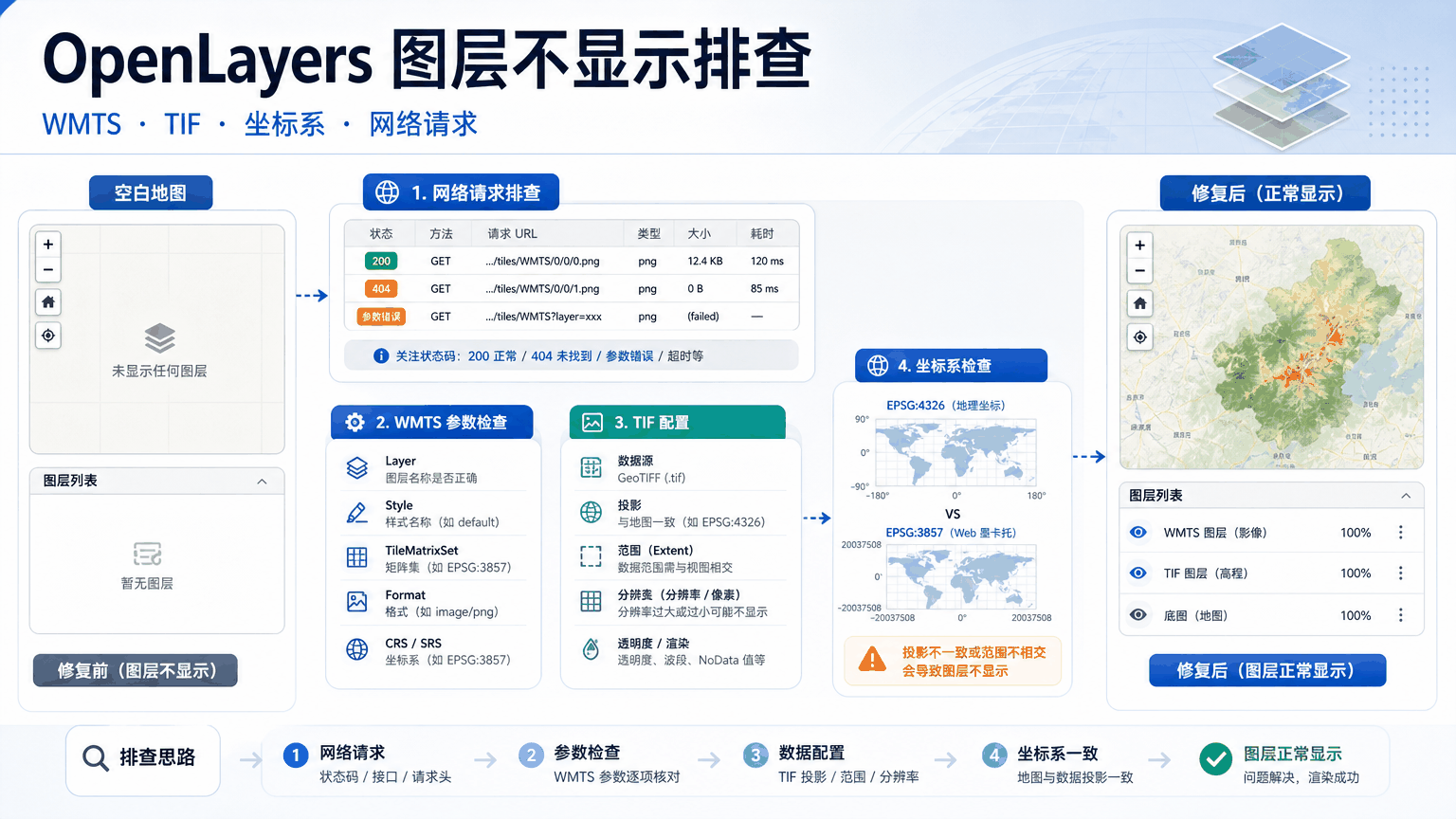
OpenLayers图层不显示:WMTS、TIF加载和原因排查 2026-06-10 19:22:44
-
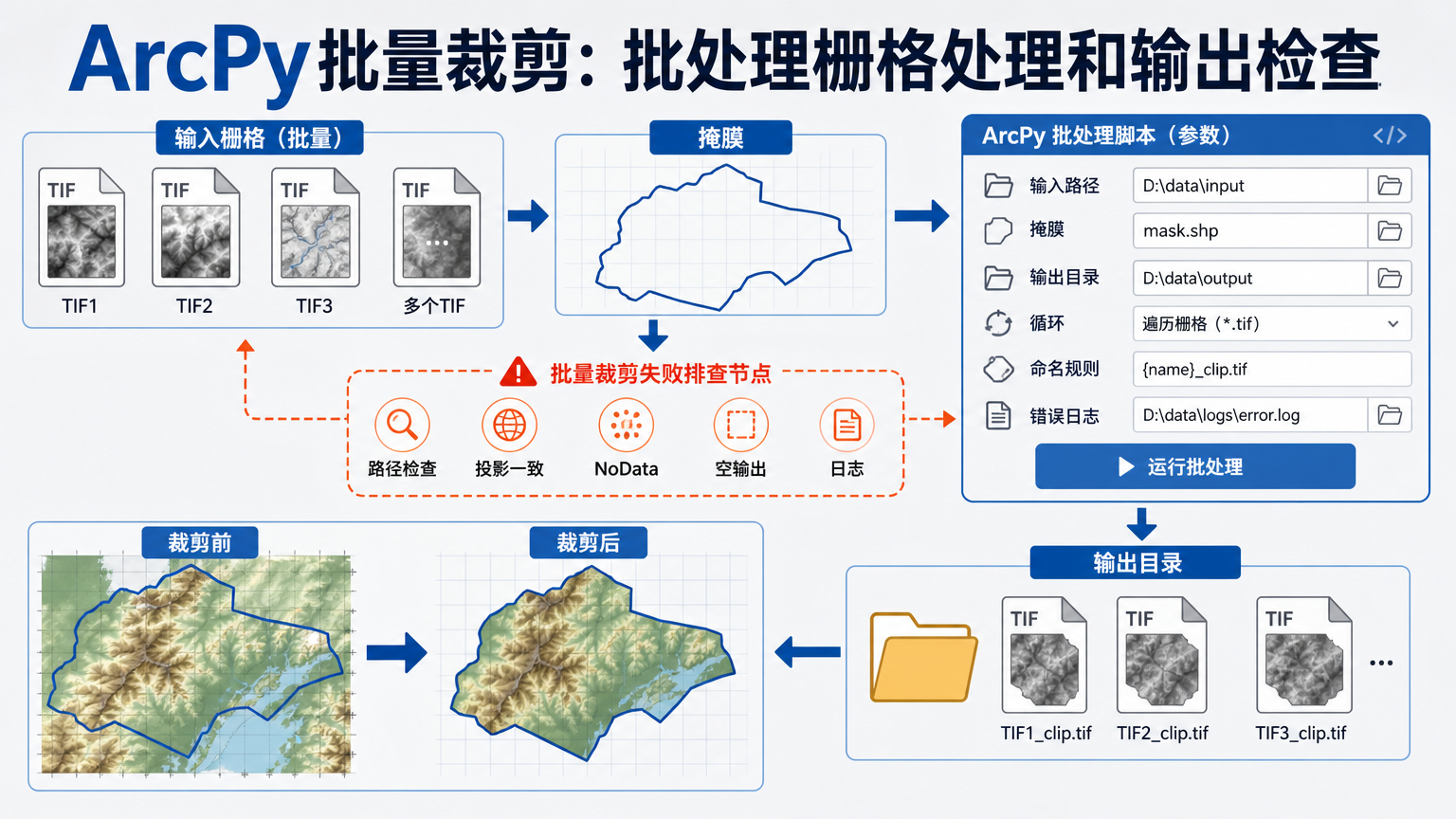
ArcPy批量裁剪:批处理栅格处理和输出检查 2026-06-10 18:47:40
-
GeoPandas裁剪:clip、读取SHP和GeoJSON裁剪流程 2026-06-10 08:45:06
-
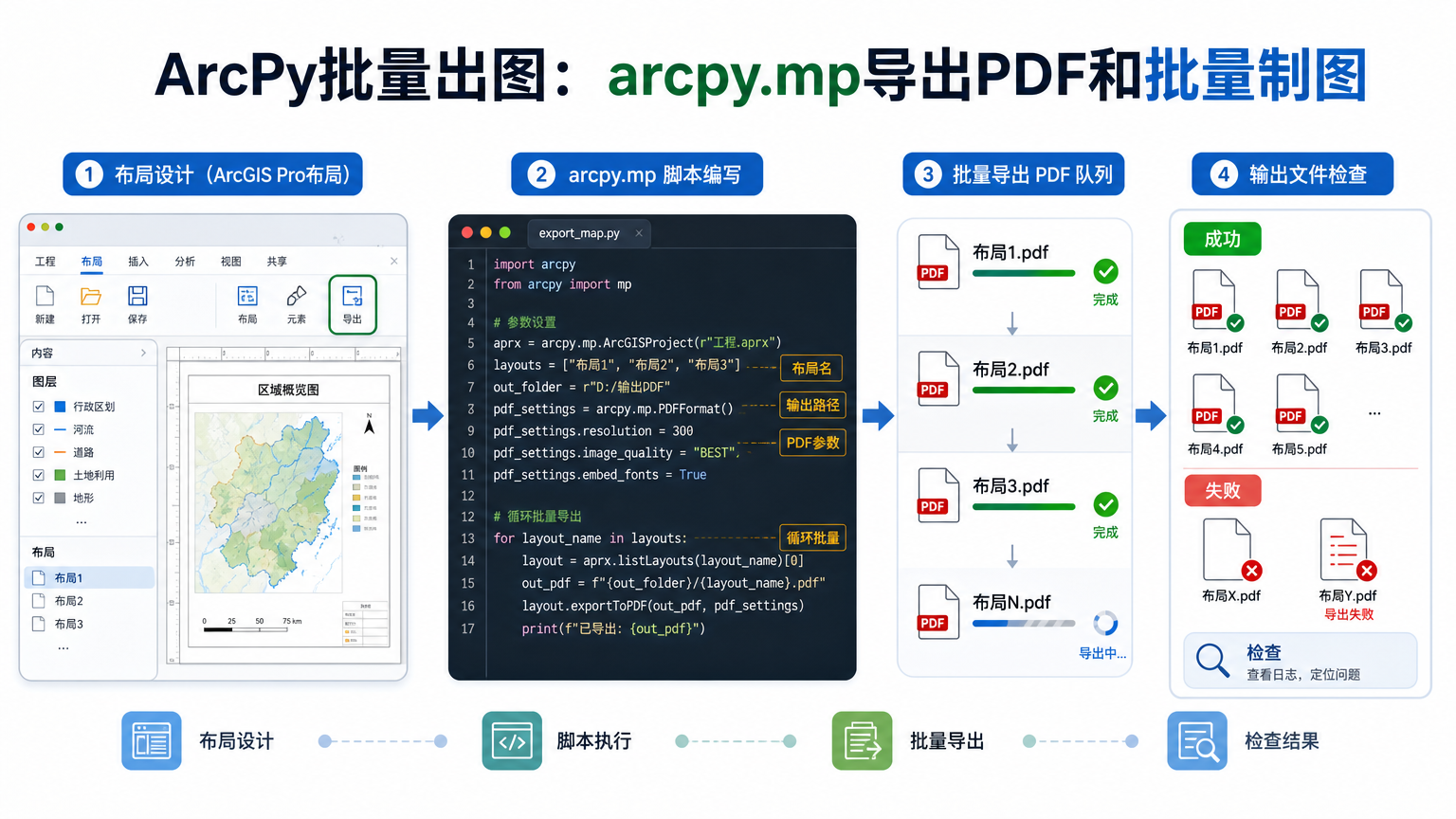
ArcPy批量出图:arcpy.mp导出PDF和批量制图 2026-06-10 08:40:05
-
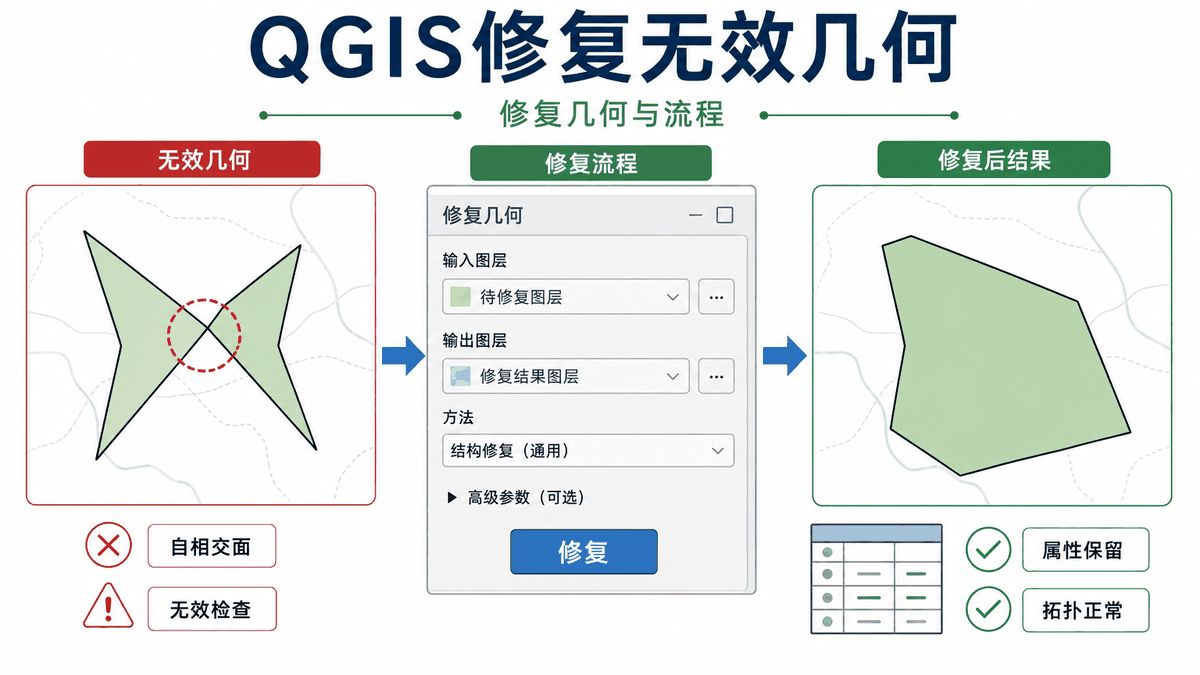
QGIS修复无效几何:修复几何和几何修复流程 2026-06-10 03:48:19
-
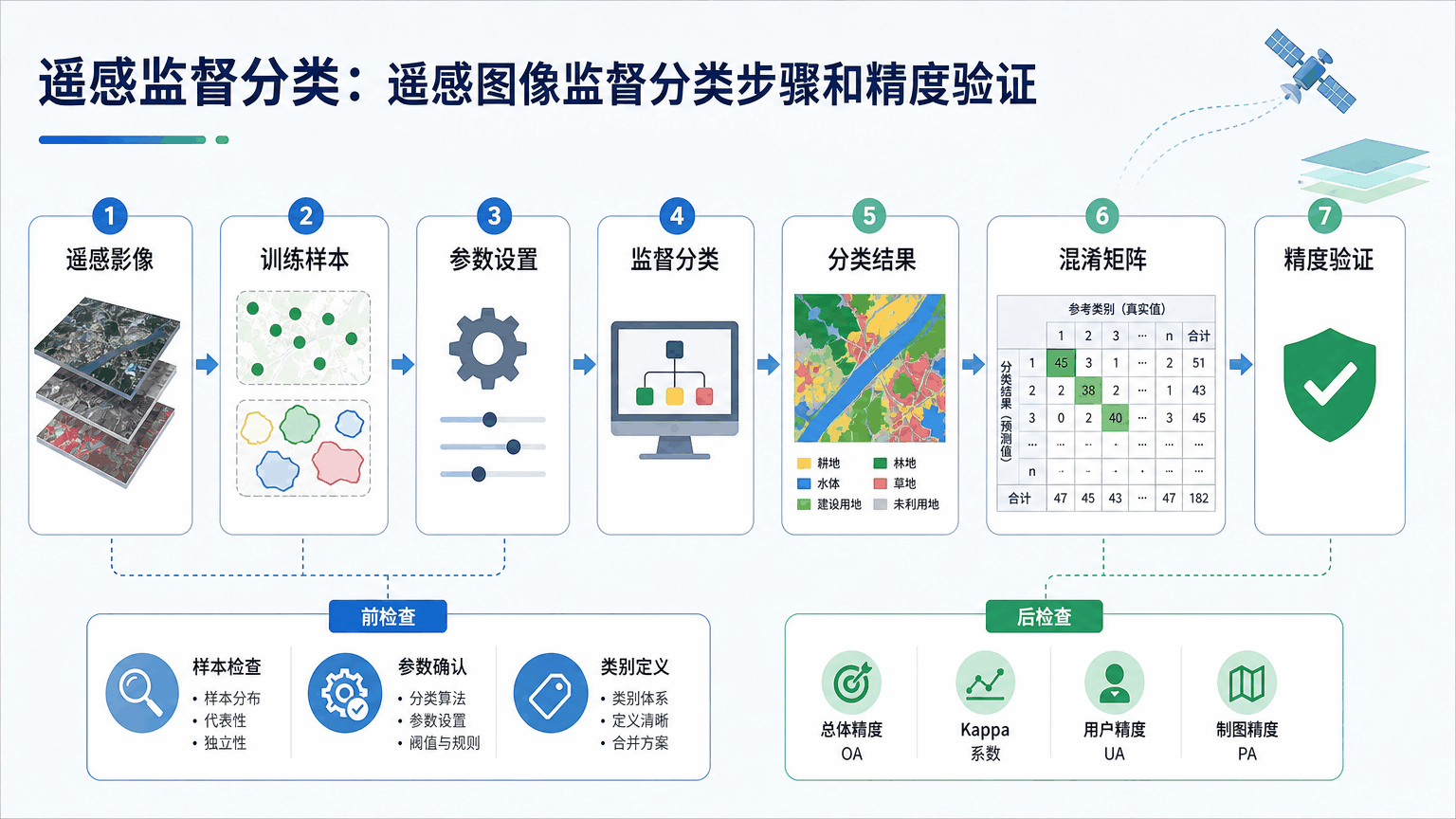
遥感监督分类:遥感图像监督分类步骤和精度验证 2026-06-09 18:16:55
-
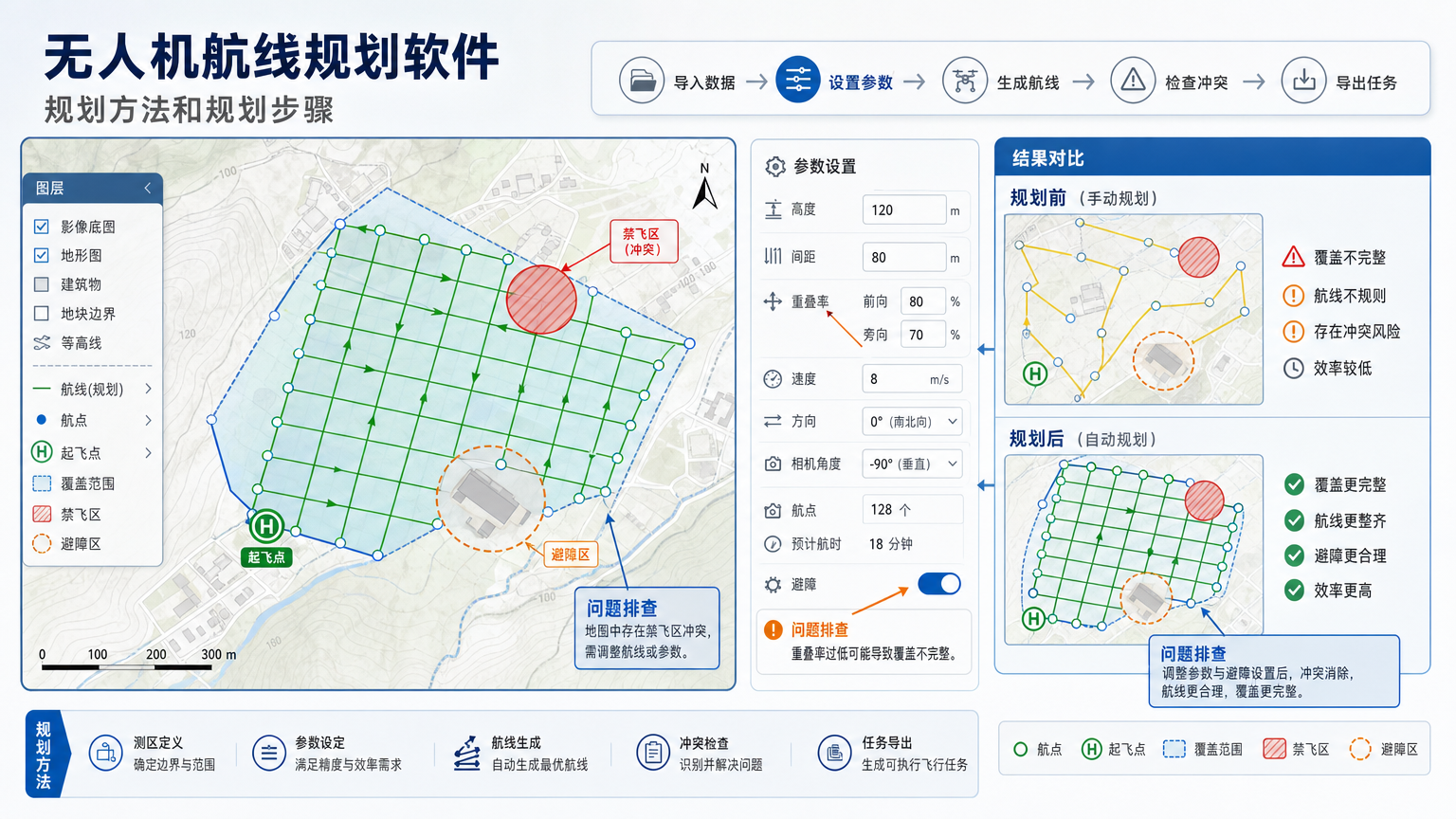
无人机航线规划软件:规划方法和规划步骤 2026-06-09 15:16:34
-
无人机测绘流程:软件有哪些、数据处理和精度 2026-06-09 13:32:14