还在手动拼接地理数据?Python地理处理自动化脚本(附:效率提升5倍源码)
《还在手动拼接地理数据?Python地理处理自动化脚本(附:效率提升5倍源码)》这篇文章解决一个很常见的 GIS 日常问题:多个县区、多个图层、多个 Shapefile 或 GeoPackage 文件需要反复拼接、统一字段、修复几何、输出成果时,手动在 QGIS 或 ArcGIS Pro 里逐个操作既慢又容易出错。
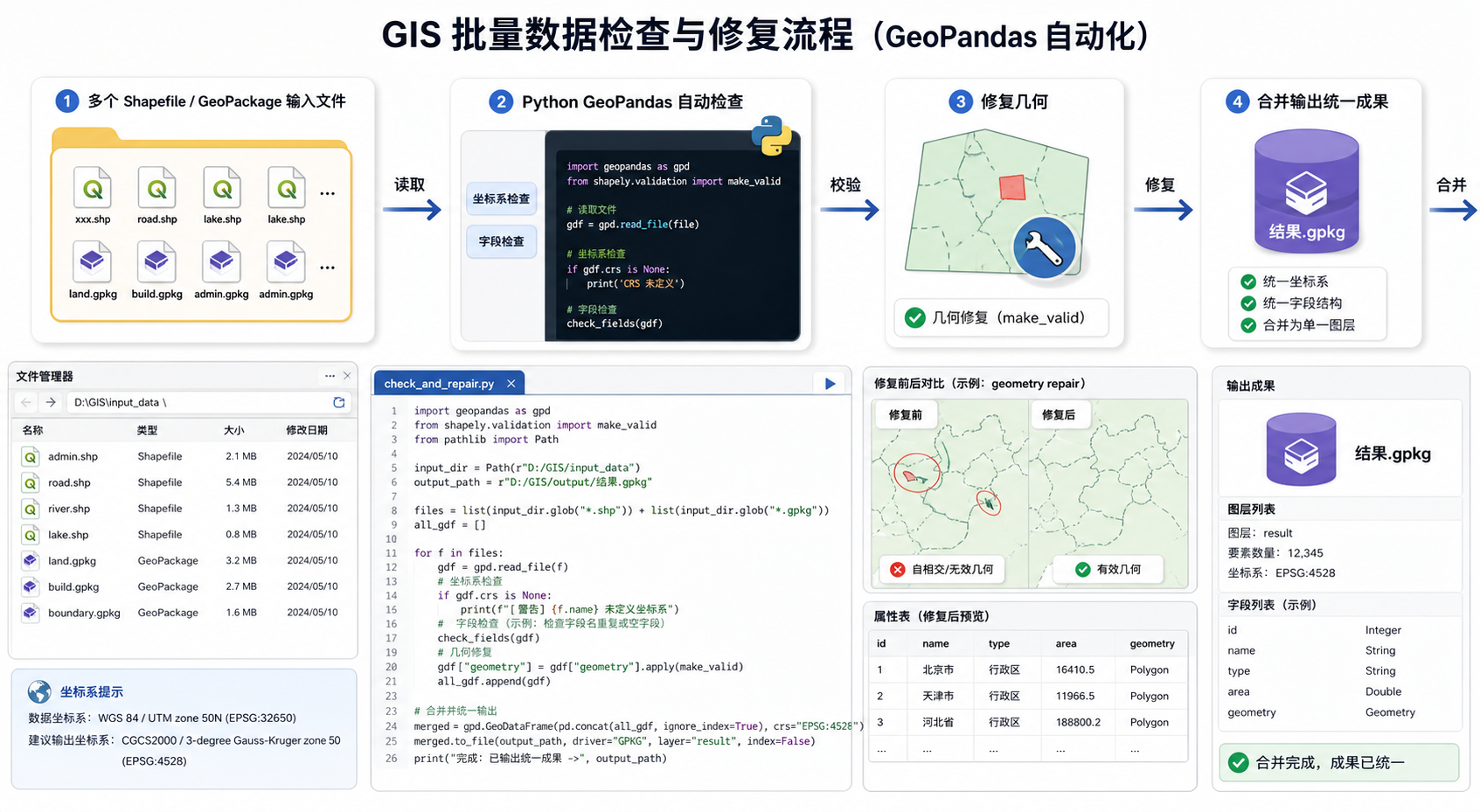
本文以 Python 地理处理自动化脚本为核心,演示如何批量读取矢量数据、检查坐标系、统一字段、合并图层、修复无效几何并输出结果。示例使用 GeoPandas,适合 GIS 学生、初级 GIS 工程师、空间数据分析人员在日常数据整理中复用。
引言:为什么要用 Python 地理处理自动化脚本
如果你经常处理行政区划、调查地块、道路、水系、POI 或项目范围数据,大概率遇到过这些场景:
- 一个市下面有几十个县区 Shapefile,需要拼接成一个完整图层。
- 不同同事导出的字段名不一致,合并后属性表很乱。
- 部分数据坐标系不同,叠加后发生偏移。
- 某些要素几何无效,导致合并、裁剪、相交分析失败。
- 每周都要重复处理同样的数据更新包。
这些任务并不复杂,但非常耗时间。Python 地理处理自动化脚本的价值就在于:把重复、规则明确、容易手误的 GIS 操作写成可复用流程。一次写好脚本,后续只需要替换输入文件夹,就能稳定产出结果。
背景:手动拼接地理数据最容易出错的地方
在桌面 GIS 软件中手动拼接地理数据,常见问题不是“不会操作”,而是“步骤太多,难以保证每次都一致”。尤其是数据量一多,错误往往隐藏在中间环节。
1. 坐标系没有统一
两个图层看起来都是同一个区域,但一个是 CGCS2000 地理坐标系,一个是 Web Mercator 投影坐标系。如果直接合并,可能出现位置偏移、面积计算不准、空间分析结果异常。
2. 字段结构不一致
例如同样表示名称,有的字段叫 name,有的叫 NAME,有的叫 mc。手动合并后,字段会变成多列,后续统计和制图都不方便。
3. 几何无效没有提前处理
自相交面、空几何、重复节点等问题,在地图上不一定明显,但在叠加分析、空间连接、格式转换时经常报错。Python 脚本可以在合并前统一检查并修复。
4. 文件命名和来源难追踪
批量拼接后,很多人会忘记每条记录来自哪个原始文件。建议在自动化脚本中增加一个 source_file 字段,便于后续质量检查和问题回溯。
原理:Python 批量拼接地理数据的核心逻辑
Python 地理处理自动化脚本并不是简单地把文件“堆在一起”。一个可靠的批量拼接流程,至少应包含以下步骤:
- 扫描输入文件夹,找到符合条件的地理数据文件。
- 逐个读取图层,确认几何类型和坐标系。
- 必要时将所有数据重投影到统一坐标系。
- 按预设字段映射规则统一属性字段。
- 检查并修复无效几何。
- 合并所有 GeoDataFrame。
- 输出为 GeoPackage、Shapefile 或 GeoJSON。
- 生成处理日志,记录成功、失败和跳过的文件。
这里推荐优先输出为 GeoPackage。相比 Shapefile,GeoPackage 支持更长字段名、中文路径兼容性更好、单文件管理更方便,也更适合自动化流程。
步骤:Python 地理处理自动化脚本完整实现
步骤 1:准备 Python 环境
建议使用 Conda 创建独立环境,避免 GDAL、Fiona、GeoPandas 版本冲突。
conda create -n gis_auto python=3.11 -y
conda activate gis_auto
conda install -c conda-forge geopandas pyogrio shapely pandas -y如果你使用的是 Windows,并且经常处理中文路径或较大的矢量数据,建议优先使用 Conda Forge 安装 GeoPandas 相关库,稳定性通常比直接 pip 安装更好。
步骤 2:整理输入数据目录
假设你的项目目录如下:
project/
input/
county_a.shp
county_b.shp
county_c.shp
output/
merge_gis_data.py本文脚本默认批量读取 input 文件夹中的 Shapefile,也可以根据需要改成 GeoPackage、GeoJSON 或 FileGDB 图层。
步骤 3:编写批量拼接脚本
下面是一份可直接改造使用的 Python 地理处理自动化脚本。它包含批量读取、坐标系统一、字段标准化、几何修复、来源记录和最终输出。
from pathlib import Path
import geopandas as gpd
import pandas as pd
INPUT_DIR = Path("input")
OUTPUT_DIR = Path("output")
OUTPUT_DIR.mkdir(exist_ok=True)
OUTPUT_FILE = OUTPUT_DIR / "merged_result.gpkg"
OUTPUT_LAYER = "merged_data"
TARGET_CRS = "EPSG:4490"
FIELD_MAP = {
"NAME": "name",
"Name": "name",
"名称": "name",
"MC": "name",
"mc": "name",
"CODE": "code",
"编码": "code",
"XZQDM": "code"
}
KEEP_FIELDS = ["name", "code", "source_file", "geometry"]
def standardize_fields(gdf):
rename_dict = {}
for col in gdf.columns:
if col in FIELD_MAP:
rename_dict[col] = FIELD_MAP[col]
gdf = gdf.rename(columns=rename_dict)
for field in KEEP_FIELDS:
if field != "geometry" and field not in gdf.columns:
gdf[field] = None
return gdf[[field for field in KEEP_FIELDS if field in gdf.columns]]
def fix_geometry(gdf):
gdf = gdf[~gdf.geometry.is_empty]
gdf = gdf[gdf.geometry.notnull()]
invalid_count = (~gdf.is_valid).sum()
if invalid_count > 0:
gdf["geometry"] = gdf.geometry.buffer(0)
gdf = gdf[gdf.geometry.notnull()]
gdf = gdf[~gdf.geometry.is_empty]
return gdf
def read_one_file(file_path):
print(f"读取:{file_path.name}")
gdf = gpd.read_file(file_path)
if gdf.empty:
print(f"跳过空文件:{file_path.name}")
return None
if gdf.crs is None:
raise ValueError(f"{file_path.name} 缺少坐标系定义,请先确认.prj或手动指定CRS")
if gdf.crs.to_string() != TARGET_CRS:
gdf = gdf.to_crs(TARGET_CRS)
gdf["source_file"] = file_path.name
gdf = standardize_fields(gdf)
gdf = fix_geometry(gdf)
return gdf
def main():
files = sorted(INPUT_DIR.glob("*.shp"))
if not files:
raise FileNotFoundError("input 文件夹中没有找到 .shp 文件")
gdf_list = []
failed_files = []
for file_path in files:
try:
gdf = read_one_file(file_path)
if gdf is not None and not gdf.empty:
gdf_list.append(gdf)
except Exception as e:
failed_files.append((file_path.name, str(e)))
print(f"处理失败:{file_path.name},原因:{e}")
if not gdf_list:
raise RuntimeError("没有可合并的数据,请检查输入文件")
merged = gpd.GeoDataFrame(
pd.concat(gdf_list, ignore_index=True),
crs=TARGET_CRS
)
merged.to_file(
OUTPUT_FILE,
layer=OUTPUT_LAYER,
driver="GPKG"
)
print("处理完成")
print(f"输出文件:{OUTPUT_FILE}")
print(f"输出图层:{OUTPUT_LAYER}")
print(f"合并要素数:{len(merged)}")
if failed_files:
print("以下文件处理失败:")
for name, reason in failed_files:
print(f"- {name}: {reason}")
if __name__ == "__main__":
main()步骤 4:运行脚本
在项目目录中打开终端,运行:
python merge_gis_data.py运行成功后,会在 output 文件夹中生成:
output/merged_result.gpkg你可以用 QGIS 或 ArcGIS Pro 打开这个 GeoPackage,检查合并后的要素数量、字段结构、坐标系和空间位置是否正确。
步骤 5:验证结果是否可靠
不要只看脚本有没有报错。GIS 数据处理必须做结果验证,建议至少检查以下内容:
- 合并后的要素数量是否等于各输入文件要素数量之和。
- 输出图层坐标系是否为预期的 EPSG:4490 或你的项目坐标系。
- 字段是否只保留了需要的标准字段。
- 地图位置是否与底图或参考边界吻合。
- source_file 字段是否能正确追踪原始数据来源。
- 是否存在空几何、无效几何或异常碎片要素。
常见坑:Python 拼接地理数据失败的排查重点
1. Shapefile 中文字段或中文路径乱码
Shapefile 对中文编码支持并不稳定,不同软件导出的编码可能不同。如果出现字段乱码或属性乱码,可以尝试将数据先转换为 GeoPackage,再进入自动化流程。
如果必须读取 Shapefile,可尝试指定编码:
gdf = gpd.read_file(file_path, encoding="utf-8")或者:
gdf = gpd.read_file(file_path, encoding="gbk")2. 缺少坐标系定义
如果 Shapefile 缺少 .prj 文件,GeoPandas 会认为该图层没有坐标系。此时不能盲目使用 to_crs,因为重投影需要先知道原始坐标系。
正确做法是先确认原始数据坐标系,再使用:
gdf = gdf.set_crs("EPSG:4490")注意:set_crs 是“声明当前坐标系”,to_crs 是“转换到新坐标系”。两者不能混用。
3. 几何修复后仍然失败
示例脚本使用 buffer(0) 修复常见面几何问题,但它不是万能方法。对于复杂自相交、多部件异常或精度问题严重的数据,可能需要在 QGIS 中使用“修复几何图形”工具,或在 PostGIS 中使用 ST_MakeValid。
4. 字段类型不一致
同一个字段在不同文件中可能有的是整数,有的是文本。合并后 Pandas 会自动推断类型,但输出到某些格式时可能出现类型变化。对于正式生产流程,建议在输出前显式转换字段类型。
merged["code"] = merged["code"].astype("string")
merged["name"] = merged["name"].astype("string")5. 数据量太大导致内存不足
GeoPandas 适合中小规模矢量数据处理。如果一次性拼接数百万要素,可能出现内存压力。此时可以考虑分批处理,或改用 PostGIS、DuckDB Spatial、ogr2ogr 等更适合大数据量的方案。
方法比较:手动拼接、GeoPandas、ArcPy 和 PostGIS 怎么选
| 方法 | 适合场景 | 优点 | 限制 |
|---|---|---|---|
| QGIS 或 ArcGIS Pro 手动合并 | 少量文件、一次性处理 | 直观,适合检查数据 | 重复任务效率低,容易漏步骤 |
| Python GeoPandas 脚本 | 中小规模矢量数据批处理 | 代码清晰,易复用,适合自动化 | 超大数据量时内存压力较大 |
| ArcPy 脚本 | ArcGIS Pro 工作流、企业内部标准流程 | 与 ArcGIS 工具箱兼容好 | 依赖 ArcGIS 授权和环境 |
| PostGIS | 大规模数据、多人协作、数据库管理 | 空间索引强,适合持续更新 | 部署和 SQL 能力要求更高 |
| GDAL ogr2ogr | 格式转换、命令行批处理 | 性能好,格式支持广 | 字段清洗和复杂逻辑不如 Python 直观 |
如果你的任务是“每周把多个县区的同类矢量数据拼接成一个成果图层”,Python GeoPandas 是非常合适的起点。如果数据已经进入数据库,或者要支撑多人协作查询,则建议进一步迁移到 PostGIS 流程。
检查清单:发布成果前必须确认的项目
- 输入文件是否完整,是否存在遗漏县区或遗漏图层。
- 所有输入图层是否属于同一数据类型,例如都是面图层或都是线图层。
- 坐标系是否统一,是否符合项目要求。
- 字段映射规则是否覆盖了所有常见字段名。
- 是否保留了 source_file 字段用于追踪来源。
- 输出格式是否适合后续使用,优先考虑 GeoPackage。
- 合并后要素数量是否符合预期。
- 是否检查过无效几何、空几何和异常位置。
- 脚本是否保存到项目目录,方便下次复用。
- 是否记录了处理日期、数据版本和处理人。
FAQ:Python 地理处理自动化脚本常见问题
Q1:Python 拼接地理数据一定比手动快 5 倍吗?
不一定。效率提升取决于文件数量、字段复杂度、检查步骤和重复频率。对于只合并两三个小文件,手动操作可能更快。但如果是几十个文件、每周重复处理、还要统一字段和坐标系,Python 地理处理自动化脚本通常能显著减少操作时间和人为错误。
Q2:GeoPandas 能直接处理 Shapefile、GeoJSON 和 GeoPackage 吗?
可以。GeoPandas 通过底层 GDAL、Fiona 或 Pyogrio 读取常见 GIS 格式。实际项目中,建议将中间成果和最终成果保存为 GeoPackage,因为它比 Shapefile 更适合保存中文字段、长字段名和多个图层。
Q3:坐标系不一致时,应该用 set_crs 还是 to_crs?
如果数据本身没有坐标系定义,但你确认它实际就是某个坐标系,用 set_crs。如果数据已经有正确坐标系,只是要转换到项目统一坐标系,用 to_crs。这是 Python GIS 自动化里非常重要的区别。
Q4:合并后属性字段变多,应该怎么处理?
字段变多通常是因为输入数据字段名不一致。解决方法是建立字段映射表,把 NAME、名称、mc 等字段统一重命名为 name。本文脚本中的 FIELD_MAP 就是为了解决这个问题。
Q5:面数据修复几何后面积会变化吗?
有可能。几何修复会尝试让无效几何变成合法几何,复杂错误可能导致边界细节变化。因此正式项目中,修复前后建议抽样检查图形,并对关键面积字段重新计算,不要直接沿用旧面积值。
Q6:这个脚本能用于 ArcGIS Pro 项目吗?
可以用于 ArcGIS Pro 项目前的数据整理,输出 GeoPackage 后可直接加载到 ArcGIS Pro。如果你的流程必须使用 File Geodatabase、地理处理工具箱或企业地理数据库,则可以考虑改写为 ArcPy 脚本。
结论:把重复 GIS 操作变成可复用流程
手动拼接地理数据适合临时、小规模任务,但一旦数据来源多、更新频繁、字段不统一,就应该考虑 Python 地理处理自动化脚本。它不仅能提升效率,更重要的是让每次处理过程可复现、可检查、可追踪。
本文给出的 GeoPandas 脚本已经覆盖了批量读取、统一坐标系、字段标准化、几何修复、数据合并和 GeoPackage 输出。你可以先在一个小项目中测试,再根据自己的业务规则扩展字段映射、日志记录、质量检查和批量制图功能。
真正高效的 GIS 工作流,不是记住更多按钮位置,而是把稳定的处理逻辑沉淀成脚本。下次再遇到多个地理数据文件需要拼接时,不妨让 Python 先替你完成第一轮整理。