Python地理处理速度太慢?批量处理城市规划数据的优化技巧(附:代码案例)
引言
如果你正在遇到“Python地理处理速度太慢?批量处理城市规划数据的优化技巧(附:代码案例)”这个问题,通常不是 Python 本身不能做 GIS,而是数据读取、坐标转换、空间叠加、循环写法和文件输出方式没有优化。
城市规划数据常见特点是图层多、字段多、面要素复杂、坐标系不统一,并且经常需要批量处理控规单元、用地地块、道路红线、行政边界、建筑轮廓、人口网格等数据。只要其中一个环节写法不当,几万条要素就可能跑半小时甚至更久。
本文以 GeoPandas、Shapely、Pyogrio、Rtree 或 PyGEOS/Shapely 2 空间索引为核心,讲清楚 Python地理处理速度太慢 的常见原因,并给出一套适合批量处理城市规划数据的优化流程和代码模板。
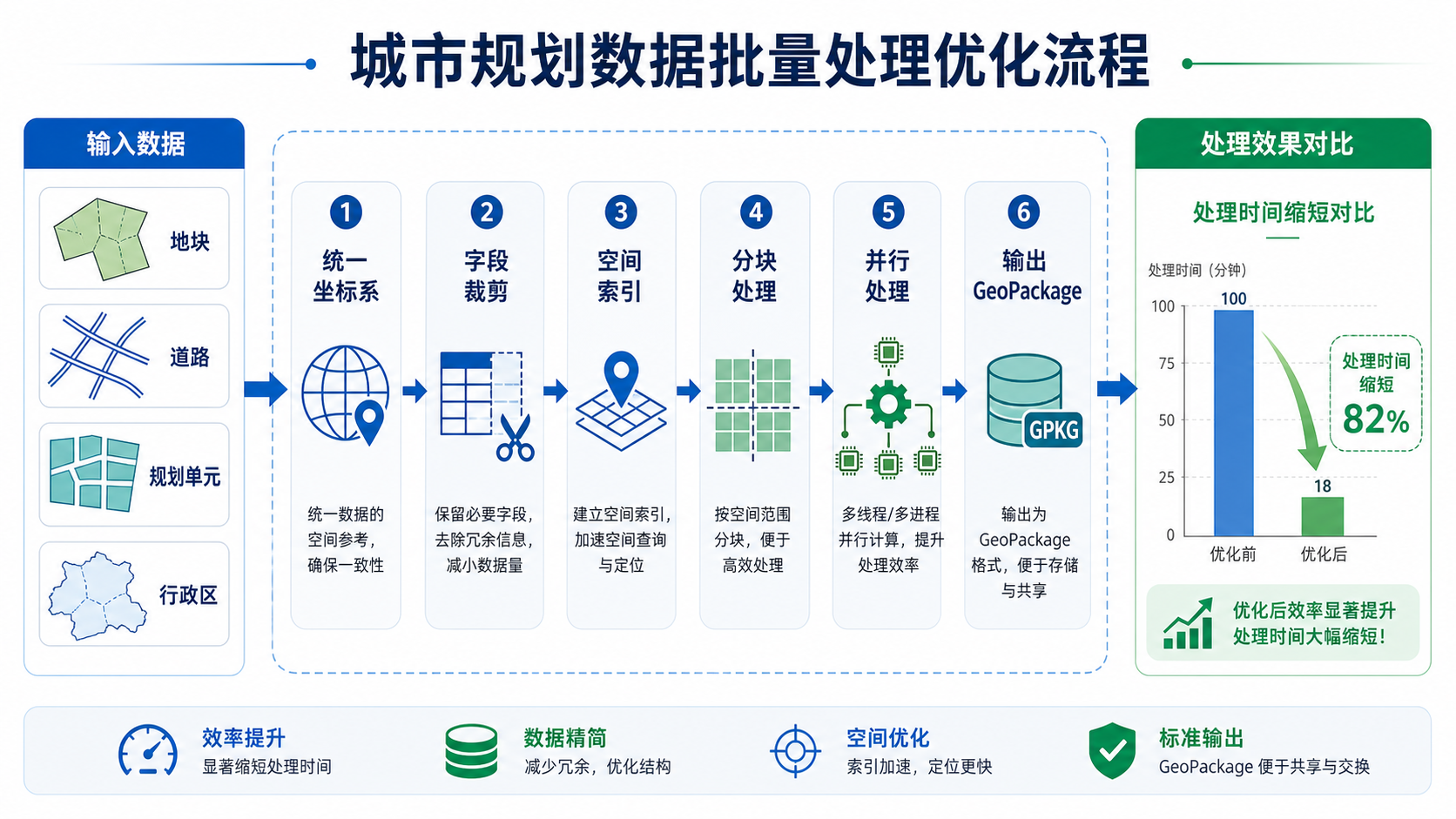
背景:为什么批量处理城市规划数据特别容易慢
城市规划数据和普通点线面数据相比,性能压力更明显。最常见的慢,不是出现在一个单独工具上,而是多个小问题叠加造成的。
- 面要素复杂:控规地块、行政区、生态红线等面数据节点多,空间叠加和相交计算开销大。
- 图层数量多:一个项目可能同时处理几十个 Shapefile、GeoJSON 或 GeoPackage 图层。
- 字段冗余:规划成果表字段很多,但实际分析只需要少数字段,读取无关字段会拖慢速度。
- 坐标系混乱:不同来源数据可能是 CGCS2000、高斯投影、WGS84 或地方坐标系,频繁重投影会明显变慢。
- 空间叠加频繁:例如地块落在哪个街道、道路缓冲区影响哪些用地、规划单元内统计用地面积,都涉及空间连接或叠加。
- 文件格式不合适:大量小 Shapefile 反复读写,比使用 GeoPackage、FlatGeobuf 或 Parquet 更慢。
所以,解决 Python地理处理速度太慢 的关键,不是只把代码改成并行,而是先把数据流程改对。
原理:Python GIS 性能瓶颈通常在哪里
在 GeoPandas 工作流中,常见耗时点可以分成五类。
1. I/O 读写瓶颈
I/O 指数据从磁盘读取到内存、再从内存写回磁盘的过程。Shapefile 由多个文件组成,字段名还有长度限制,批量读写时通常不如 GeoPackage、FlatGeobuf 或 GeoParquet 稳定高效。
2. 坐标系转换瓶颈
坐标转换会对每个几何对象的坐标点进行计算。如果面要素节点非常多,重复执行 to_crs() 会非常慢。正确做法是:统一坐标系只做一次,并把结果缓存成中间文件。
3. Python 循环瓶颈
很多初学者会逐行遍历 GeoDataFrame,例如用 iterrows() 判断每个地块和每个街道是否相交。这种写法在数据量稍大时会非常慢。应优先使用 sjoin()、overlay()、clip() 等向量化函数。
4. 空间索引瓶颈
空间索引是 GIS 中用于快速筛选候选几何对象的数据结构。没有空间索引时,地块和行政区相交判断可能变成“每个地块都和每个行政区比较”。有空间索引时,会先用外接矩形快速筛选候选对象,再做精确几何判断。
5. 几何复杂度瓶颈
城市边界、河道蓝线、生态保护线等数据可能包含大量细碎节点。若分析目标只是统计分区面积或做范围筛选,可以先进行几何修复、简化或裁剪,减少后续计算量。
步骤:批量处理城市规划数据的优化流程
步骤一:先检查数据量、坐标系和字段
不要一上来就写复杂分析。先用脚本批量检查图层大小、要素数量、坐标系和字段,找出最可能拖慢处理的图层。
from pathlib import Path
import geopandas as gpd
data_dir = Path(r"D:/planning_project/raw")
files = list(data_dir.glob("*.shp"))
for fp in files:
gdf = gpd.read_file(fp, rows=5)
print("文件:", fp.name)
print("坐标系:", gdf.crs)
print("字段数:", len(gdf.columns))
print("示例字段:", list(gdf.columns[:8]))
print("-" * 40)这里使用 rows=5 只读取前 5 行,用于快速查看结构。正式处理前,建议确认以下内容:
- 所有参与面积计算的数据是否为投影坐标系,而不是经纬度坐标系。
- 是否存在字段数量特别多但实际不用的图层。
- 是否有明显异常的大文件,例如单个图层几百 MB 以上。
- 是否存在无效几何,例如自相交、多部件异常、空几何。
步骤二:优先使用更快的读取引擎和合适格式
如果环境支持,建议使用 pyogrio 作为 GeoPandas 的读取引擎。对于批量城市规划数据,建议把原始 Shapefile 统一转换为 GeoPackage 或 GeoParquet,减少后续反复读取成本。
import geopandas as gpd
from pathlib import Path
src = Path(r"D:/planning_project/raw/landuse.shp")
out = Path(r"D:/planning_project/work/landuse.gpkg")
gdf = gpd.read_file(src, engine="pyogrio")
gdf.to_file(out, layer="landuse", driver="GPKG")如果后续主要在 Python 中分析,GeoParquet 也很适合做中间数据:
gdf.to_parquet(r"D:/planning_project/work/landuse.parquet")一般建议:
- 成果交换给规划、测绘或自然资源部门时,优先 GeoPackage 或 Shapefile。
- Python 中间计算时,优先 GeoParquet 或 Feather。
- WebGIS 前端展示时,再按需要转为 GeoJSON、MVT 或切片服务。
步骤三:只读取需要的字段和范围
Python地理处理速度太慢 的一个常见原因,是每次都把所有字段、所有范围读入内存。对于城市规划分析,经常只需要地块编号、用地性质、面积、几何字段。
import geopandas as gpd
columns = ["DKBH", "YDXZ", "geometry"]
landuse = gpd.read_file(
r"D:/planning_project/raw/landuse.shp",
columns=columns,
engine="pyogrio"
)如果只处理某个行政区或规划片区,可以先用边界范围过滤:
boundary = gpd.read_file(r"D:/planning_project/raw/study_area.shp", engine="pyogrio")
bbox = tuple(boundary.total_bounds)
landuse = gpd.read_file(
r"D:/planning_project/raw/landuse.shp",
bbox=bbox,
columns=["DKBH", "YDXZ", "geometry"],
engine="pyogrio"
)注意:bbox 是按外接矩形筛选,不等于精确裁剪。后续如果需要严格位于研究区内,还要再做 clip() 或空间相交判断。
步骤四:统一坐标系,并缓存中间结果
城市规划数据涉及面积、长度、缓冲区时,必须使用合适的投影坐标系。不要在循环里反复执行 to_crs(),而应在流程开头统一转换一次。
target_crs = "EPSG:4547" # 示例:CGCS2000 / 3-degree Gauss-Kruger zone 39,请按项目所在地修改
landuse = landuse.to_crs(target_crs)
boundary = boundary.to_crs(target_crs)
landuse.to_parquet(r"D:/planning_project/work/landuse_4547.parquet")
boundary.to_parquet(r"D:/planning_project/work/boundary_4547.parquet")这里的 EPSG 只是示例。实际项目中应根据城市所在经度、甲方数据说明、自然资源部门标准或已有成果坐标系确定。坐标系选错会导致面积、长度、缓冲区结果不可信。
步骤五:修复无效几何,减少叠加失败
空间叠加慢,有时不是因为数据太大,而是因为无效几何导致计算反复报错或结果异常。可以在关键分析前检查并修复几何。
invalid_count = (~landuse.is_valid).sum()
print("无效几何数量:", invalid_count)
landuse["geometry"] = landuse.geometry.make_valid()
landuse = landuse[~landuse.geometry.is_empty & landuse.geometry.notna()]如果你的 Shapely 版本不支持 make_valid(),可以考虑升级 Shapely,或临时使用 buffer(0) 方式修复。但 buffer(0) 不是万能方案,可能改变复杂面形态,正式成果前需要抽样检查。
步骤六:用空间连接替代双重循环
例如要判断每个用地地块属于哪个规划管理单元,不建议写两层循环逐个判断。应使用 gpd.sjoin()。
import geopandas as gpd
landuse = gpd.read_parquet(r"D:/planning_project/work/landuse_4547.parquet")
units = gpd.read_file(r"D:/planning_project/raw/planning_units.shp", engine="pyogrio").to_crs(landuse.crs)
units = units[["UNIT_ID", "UNIT_NAME", "geometry"]]
result = gpd.sjoin(
landuse,
units,
how="left",
predicate="intersects"
)
result.to_parquet(r"D:/planning_project/work/landuse_with_unit.parquet")sjoin() 会利用空间索引筛选候选对象,通常比手写循环快得多。对于地块归属类任务,如果需要按地块中心点归属单元,可以先生成代表点再连接:
landuse_point = landuse.copy()
landuse_point["geometry"] = landuse_point.geometry.representative_point()
result = gpd.sjoin(
landuse_point,
units,
how="left",
predicate="within"
)representative_point() 比 centroid 更适合不规则面,因为它保证点位于面内部。对于规划地块归属判断,这一点很重要。
步骤七:面积统计尽量使用 dissolve 和 groupby
例如统计每个规划单元内不同用地性质的面积,推荐流程是:裁剪或叠加、计算面积、分组汇总。
landuse = gpd.read_parquet(r"D:/planning_project/work/landuse_4547.parquet")
units = gpd.read_file(r"D:/planning_project/raw/planning_units.shp", engine="pyogrio").to_crs(landuse.crs)
units = units[["UNIT_ID", "geometry"]]
landuse = landuse[["YDXZ", "geometry"]]
inter = gpd.overlay(landuse, units, how="intersection")
inter["area_m2"] = inter.geometry.area
summary = (
inter
.groupby(["UNIT_ID", "YDXZ"], as_index=False)["area_m2"]
.sum()
)
summary["area_ha"] = summary["area_m2"] / 10000
summary.to_csv(r"D:/planning_project/output/unit_landuse_area.csv", index=False, encoding="utf-8-sig")这个流程适合做控规单元用地统计、街道用地统计、生态控制区内建设用地统计等任务。若 overlay() 仍然很慢,可以先按研究区裁剪、简化边界、或按行政区分块处理。
步骤八:大数据量时按空间网格或行政区分块处理
当一个城市的建筑轮廓、道路面、地籍地块数量很大时,一次性 overlay() 可能占用大量内存。可以按行政区、街道、规划片区或规则网格分块处理。
from pathlib import Path
import geopandas as gpd
import pandas as pd
landuse = gpd.read_parquet(r"D:/planning_project/work/landuse_4547.parquet")
districts = gpd.read_file(r"D:/planning_project/raw/districts.shp", engine="pyogrio").to_crs(landuse.crs)
out_dir = Path(r"D:/planning_project/output/chunks")
out_dir.mkdir(parents=True, exist_ok=True)
all_tables = []
for idx, row in districts.iterrows():
district_id = row["DIST_ID"]
geom = row.geometry
one_boundary = gpd.GeoDataFrame(
[{"DIST_ID": district_id, "geometry": geom}],
crs=districts.crs
)
subset = landuse[landuse.intersects(geom)]
if subset.empty:
continue
clipped = gpd.overlay(subset, one_boundary, how="intersection")
clipped["area_m2"] = clipped.geometry.area
table = clipped.groupby(["DIST_ID", "YDXZ"], as_index=False)["area_m2"].sum()
all_tables.append(table)
clipped.to_file(out_dir / f"landuse_{district_id}.gpkg", layer="landuse", driver="GPKG")
summary = pd.concat(all_tables, ignore_index=True)
summary.to_csv(r"D:/planning_project/output/district_landuse_summary.csv", index=False, encoding="utf-8-sig")分块处理的好处是单次内存压力小,也便于失败后从某个区块继续运行。缺点是边界附近可能出现重复或缝隙问题,所以分块逻辑必须清楚:是按行政区裁剪,还是按网格临时分块再合并。
步骤九:必要时使用并行处理,但不要盲目并行
并行处理适合“每个区县、每个图层、每个文件可以独立处理”的任务。对于共享同一个大 GeoDataFrame 的复杂空间叠加,并行不一定稳定,反而可能因为内存复制导致更慢。
from concurrent.futures import ProcessPoolExecutor
from pathlib import Path
import geopandas as gpd
def process_one_file(fp):
gdf = gpd.read_file(fp, engine="pyogrio")
gdf = gdf.to_crs("EPSG:4547")
gdf["area_m2"] = gdf.geometry.area
out = Path(r"D:/planning_project/output") / (fp.stem + "_area.gpkg")
gdf.to_file(out, layer="result", driver="GPKG")
return fp.name
if __name__ == "__main__":
files = list(Path(r"D:/planning_project/raw").glob("*.shp"))
with ProcessPoolExecutor(max_workers=4) as executor:
for name in executor.map(process_one_file, files):
print("完成:", name)建议从 max_workers=2 或 4 开始测试。城市规划数据通常几何对象较大,并行数过高会造成内存爆掉、磁盘读写拥堵或输出文件锁冲突。
常见坑:Python地理处理速度太慢时优先排查这些问题
坑一:在经纬度坐标系下直接算面积
如果数据是 EPSG:4326,geometry.area 得到的是“度的平方”,不是平方米。正确做法是先转换到合适的投影坐标系,再计算面积。
坑二:把所有字段都读进来
规划数据经常有大量审批字段、备注字段、历史字段。分析只需要少数字段时,应使用 columns 参数读取必要字段。
坑三:用 iterrows 做空间判断
iterrows() 适合少量记录的简单逻辑,不适合大批量空间相交、包含、邻近判断。空间关系判断应优先使用 sjoin()、overlay() 和空间索引。
坑四:每一步都输出 Shapefile
Shapefile 兼容性好,但作为 Python 中间格式并不理想。字段名截断、编码问题、多个文件读写开销,都会影响批处理稳定性。中间成果建议使用 GeoParquet 或 GeoPackage。
坑五:没有检查无效几何
无效几何可能导致 overlay 失败、面积统计异常、空间连接结果缺失。批量处理城市规划数据前,至少应检查 is_valid、空几何和坐标系。
坑六:盲目简化几何
几何简化可以提速,但会改变边界形态。对于法定规划成果、红线、地籍边界,不应随意简化。可视化展示可以简化,法定统计和面积核算要谨慎。
方法比较:不同优化手段适合什么场景
| 优化方法 | 适合场景 | 优点 | 注意事项 |
|---|---|---|---|
| 只读取必要字段 | 字段很多的用地、地块、审批数据 | 减少内存占用,提升读取速度 | 不要漏掉后续统计字段 |
| 使用 GeoPackage | 多图层成果管理、部门交换 | 单文件管理,兼容性较好 | 超大中间计算不一定最快 |
| 使用 GeoParquet | Python 中间数据、批量分析 | 读取快,字段类型保存较好 | 部分桌面 GIS 软件支持程度不同 |
| 空间索引和 sjoin | 点面归属、地块落区、设施服务范围判断 | 比双重循环快很多 | 要确认 predicate 使用正确 |
| overlay 叠加 | 面积分摊、用地统计、边界裁剪 | 结果严谨,适合统计分析 | 复杂面数据会比较耗时 |
| 分块处理 | 全市级地块、建筑、道路大数据 | 降低单次内存压力,便于断点重跑 | 边界重复和合并逻辑要设计好 |
| 并行处理 | 多个独立文件或独立行政区任务 | 可利用多核 CPU | 并行数过高会导致内存和磁盘压力 |
检查清单:优化前后都要确认
在你判断 Python地理处理速度太慢 之前,建议先按下面清单逐项排查。
- 是否已经确认所有输入数据的坐标系?
- 面积和长度计算是否使用投影坐标系?
- 是否只读取了必要字段?
- 是否避免了
iterrows()双重循环做空间判断? - 是否使用
sjoin()或overlay()替代手写相交判断? - 是否检查并修复无效几何?
- 是否把中间结果缓存为 GeoParquet 或 GeoPackage?
- 是否对超大图层进行分块处理?
- 是否记录了每个步骤耗时,找出真正瓶颈?
- 并行处理前,是否测试过单进程版本的正确性?
一个简单的耗时记录模板
优化性能时,不要凭感觉判断。可以用 time 模块记录每一步耗时。
import time
import geopandas as gpd
t0 = time.time()
landuse = gpd.read_file(r"D:/planning_project/raw/landuse.shp", engine="pyogrio")
print("读取耗时:", round(time.time() - t0, 2), "秒")
t1 = time.time()
landuse = landuse.to_crs("EPSG:4547")
print("投影转换耗时:", round(time.time() - t1, 2), "秒")
t2 = time.time()
landuse["area_m2"] = landuse.geometry.area
print("面积计算耗时:", round(time.time() - t2, 2), "秒")只有知道到底是读取慢、投影慢、叠加慢还是输出慢,优化才有方向。
FAQ
Q1:Python地理处理速度太慢,是不是应该直接换 ArcGIS Pro 或 QGIS?
不一定。ArcGIS Pro 和 QGIS 的图形界面工具适合交互式处理,Python 更适合批量、重复、自动化任务。如果你的代码存在双重循环、重复投影、反复读写 Shapefile 等问题,换软件也未必解决根因。建议先优化数据流程和代码结构。
Q2:批量处理城市规划数据时,GeoPandas 和 ArcPy 哪个更快?
要看任务类型。ArcPy 与 ArcGIS Pro 工具链集成好,适合 Esri 地理数据库、企业流程和制图成果。GeoPandas 更适合开放格式、自动化脚本和数据科学分析。对于简单字段处理、空间连接、批量统计,GeoPandas 优化后通常足够实用;对于复杂地理数据库规则和 ArcGIS 专有工具,ArcPy 更合适。
Q3:为什么用了空间索引还是慢?
空间索引只能减少候选几何对象数量,不能消除精确几何计算成本。如果面非常复杂、overlay 需要切割大量边界,仍然会慢。此时应考虑先裁剪研究区、减少字段、修复几何、分块处理,或评估是否可以用点代表面、外接矩形预筛选等近似策略。
Q4:城市规划用地面积统计可以先简化边界吗?
如果是法定成果、规划指标核算、地块面积统计,不建议随意简化边界。简化会改变几何形状,可能影响面积和边界关系。如果只是 WebGIS 展示或快速预览,可以在副本上简化,并保留原始数据用于正式统计。
Q5:Python 批量处理时内存不够怎么办?
优先考虑四件事:只读必要字段、按范围读取、分块处理、使用中间文件缓存。不要把所有图层一次性读入内存。对于全市建筑轮廓、道路网、地块面等大数据,按区县、街道或网格分块通常更稳。
Q6:输出 GeoJSON 很慢怎么办?
GeoJSON 是文本格式,文件大时读写和浏览器加载都会慢。若是中间计算,不建议使用 GeoJSON;若是 WebGIS 发布,应考虑矢量切片、服务接口、FlatGeobuf 或按范围分页加载。GeoJSON 更适合小范围、少量要素的数据交换。
结论
Python地理处理速度太慢,并不意味着 Python 不适合 GIS。对于批量处理城市规划数据,真正有效的优化顺序通常是:先检查坐标系和几何质量,再减少读取字段和范围,然后使用空间索引、向量化函数、合适的中间格式,最后再考虑分块和并行。
如果你的任务是控规单元用地统计、地块归属判断、道路影响范围分析、规划成果批量质检,可以优先套用本文的流程:统一坐标系、缓存中间结果、用 sjoin 替代循环、用 overlay 做严谨叠加、按行政区分块处理大数据。
性能优化的核心不是写更复杂的代码,而是让每一步只处理必要的数据,并用正确的 GIS 方法完成正确的空间计算。