空间分析结果总是不准?空间分析与建模精度提升的5大核心技巧(附:GIS数据处理清单)
引言
如果你正在怀疑“空间分析结果总是不准?空间分析与建模精度提升的5大核心技巧(附:GIS数据处理清单)”这个问题,多半不是某一个工具按钮点错了,而是坐标系、数据质量、分析参数、建模假设和结果验证之间有一个环节出了偏差。
在 QGIS、ArcGIS Pro、PostGIS、GeoPandas 或 ArcPy 中做缓冲区、叠加分析、栅格重分类、可达性分析、适宜性评价时,很多结果看起来“能跑出来”,但面积、距离、范围、等级分区或叠加关系却和业务认知不一致。本文从实际 GIS 工作流出发,整理 5 个提升空间分析与建模精度的核心技巧,并附一份可直接复用的 GIS 数据处理清单。
背景:为什么空间分析结果总是不准
空间分析结果不准,常见表现包括:
- 缓冲区半径设为 1000 米,但实际看起来明显偏大或偏小。
- 叠加分析后出现大量碎小面、缝隙、重叠区。
- 面积统计结果和已有台账、规划指标差异很大。
- 栅格适宜性评价结果分区异常,某些区域被错误划为高适宜或低适宜。
- 模型在一个地区效果正常,换到另一个地区就明显失真。
这些问题通常不是单纯的“软件错误”。更常见的原因是:输入数据没有统一坐标参考系,空间分辨率不匹配,字段单位理解错误,拓扑质量差,分析参数没有结合业务场景设置,或者缺少结果验证步骤。
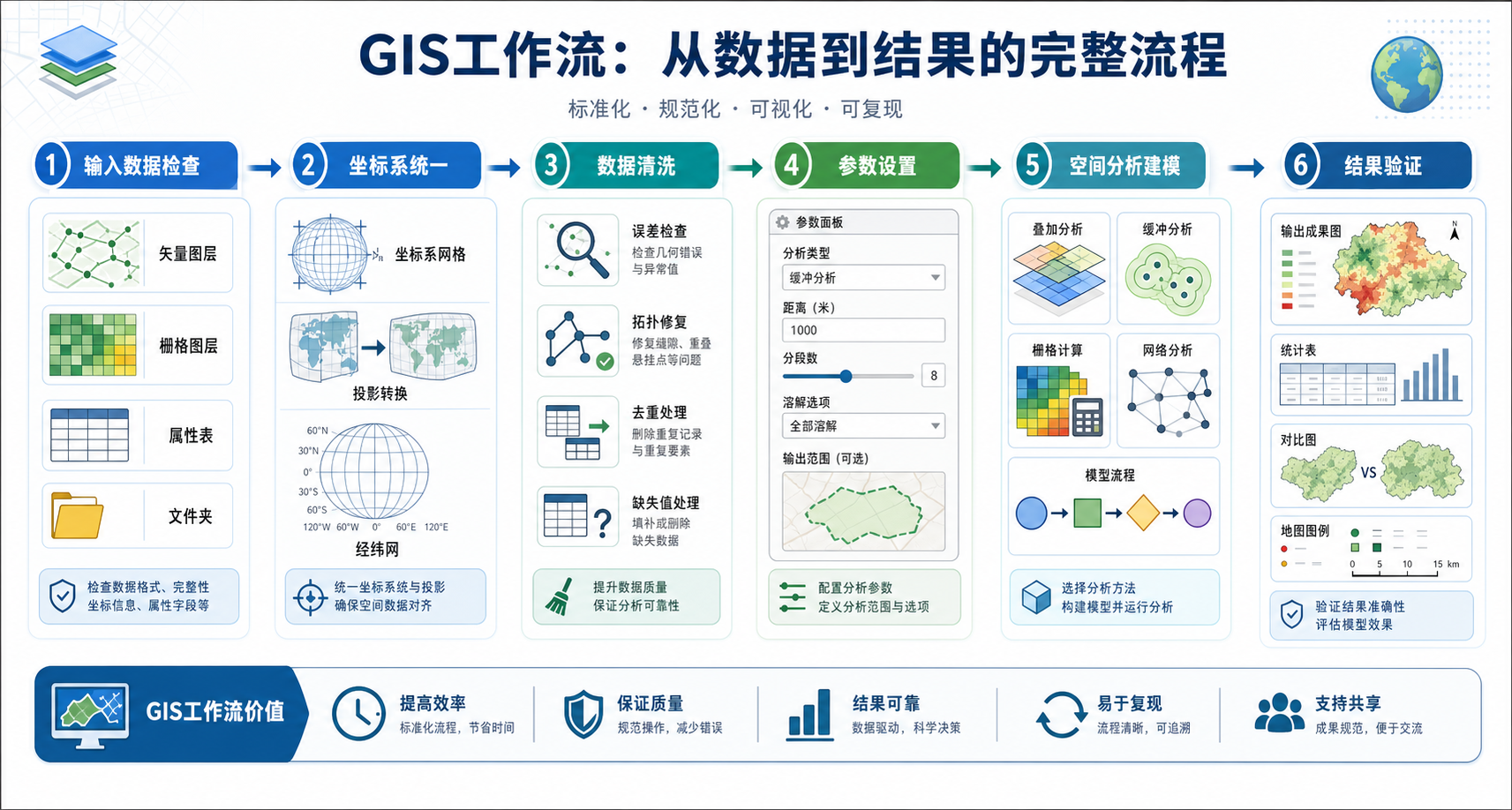
原理:空间分析精度由哪些环节共同决定
空间分析精度不是一个单独参数决定的,而是由数据、坐标、算法、参数和验证共同决定。
第一,数据精度决定上限。如果道路数据本身偏移 20 米,那么后续做 10 米缓冲区分析就很难得到可信结论。矢量数据的位置精度、属性完整性、拓扑关系和采集时间都会影响空间分析结果。
第二,坐标参考系决定距离和面积是否可信。经纬度坐标适合表达全球位置,但直接用经纬度计算面积、距离和缓冲区通常会产生误差。做距离、面积、缓冲区、邻近分析时,应优先使用合适的投影坐标系。
第三,分析参数决定模型表达的是不是你的业务问题。例如缓冲区距离、栅格分辨率、插值方法、权重系数、阈值分级,都会改变最终结果。参数不是越复杂越好,而是要和数据精度、研究尺度、业务规则匹配。
第四,结果验证决定能否发现错误。很多空间分析结果“看起来像地图”,但没有经过抽样核查、统计对比、空间叠加验证,就不能直接用于报告或决策。
步骤:提升空间分析与建模精度的5大核心技巧
技巧一:先统一坐标系,再做面积、距离和缓冲区分析
坐标系问题是空间分析结果不准的高频原因。尤其是把 WGS84 经纬度数据直接拿来做面积统计、缓冲区或距离计算时,结果很容易偏离真实情况。
建议按下面步骤处理:
- 在 QGIS 或 ArcGIS Pro 中检查每个图层的坐标参考系。
- 确认数据是否只是“定义坐标系”,还是已经真正“投影转换”。
- 涉及面积、距离、缓冲区、邻近分析时,将数据转换到适合研究区的投影坐标系。
- 不要只依赖图层“动态投影显示”,分析前应生成统一投影后的新数据。
- 分析完成后,再按制图或交换需求导出为目标坐标系。
在 QGIS 中,可以使用“另存为”或“重新投影图层”工具;在 ArcGIS Pro 中,可以使用 Project 工具。注意 Project 是投影转换,Define Projection 是定义坐标系,二者不能混用。
判断原则:如果图层位置本来是对的,只是软件不知道它是什么坐标系,才使用定义坐标系;如果要从一个坐标系转换到另一个坐标系,应使用投影转换。
技巧二:做空间分析前先清洗拓扑和几何错误
空间分析与建模精度提升,离不开几何质量检查。很多叠加分析、裁剪、相交、融合失败,或者结果出现碎小面,根源是输入数据存在几何错误。
常见几何问题包括:
- 面要素自相交。
- 线要素悬挂、重复、断裂。
- 面与面之间存在缝隙或重叠。
- 几何为空或面积极小。
- 多部件要素不符合后续分析要求。
在 QGIS 中,可以使用“检查有效性”“修复几何图形”“删除重复几何图形”等工具。在 ArcGIS Pro 中,可以使用 Check Geometry、Repair Geometry、Integrate、Eliminate Polygon Part、Multipart To Singlepart 等工具。
如果是 PostGIS 数据库,可以先用以下思路检查:
SELECT id
FROM your_table
WHERE NOT ST_IsValid(geom);修复时可谨慎使用:
UPDATE your_table
SET geom = ST_MakeValid(geom)
WHERE NOT ST_IsValid(geom);需要注意,自动修复几何可能改变要素结构。例如一个自相交面可能被修复成多个面。因此,修复后要检查要素数量、面积总和和空间范围是否出现异常变化。
技巧三:让分析尺度、分辨率和数据精度匹配
很多空间分析结果不准,并不是算法错了,而是分析尺度和数据精度不匹配。例如,用 1:100000 的道路数据分析小区级步行可达性,或者用 1 公里分辨率栅格分析街区级热岛效应,结果很难可靠。
在矢量分析中,要重点关注:
- 数据采集比例尺是否支持当前研究尺度。
- 线、面边界是否经过过度简化。
- 不同来源图层是否存在位置偏移。
- 叠加分析前是否需要设置合理容差。
在栅格建模中,要重点关注:
- 所有栅格是否使用相同像元大小。
- 是否使用相同范围和对齐方式。
- 重采样方法是否合适。
- 分类变量和连续变量是否混用了错误的重采样方式。
一般来说,土地利用、行政区分类、土壤类型等类别栅格,重采样时优先使用最邻近法;高程、温度、降水等连续栅格,可以根据需求使用双线性或三次卷积。方法选错,会直接影响空间建模精度。
技巧四:参数设置要记录来源,不要凭感觉调模型
空间分析建模最容易被忽略的一点,是参数来源。缓冲区距离、权重系数、阈值分级、衰减函数、插值半径等参数,如果只是凭经验随手设置,结果就很难解释。
建议为每个关键参数建立记录表:
| 参数类型 | 常见例子 | 建议记录内容 |
|---|---|---|
| 距离参数 | 500 米服务半径、道路影响范围 | 业务规范、文献依据、现场经验、敏感性测试结果 |
| 权重参数 | 坡度权重、交通可达性权重 | 专家打分方法、层次分析法过程、归一化方式 |
| 阈值参数 | 适宜性等级、风险等级 | 分级标准、统计分位数、政策或行业规范 |
| 栅格参数 | 像元大小、分析范围、重采样方法 | 数据源分辨率、研究尺度、对齐基准图层 |
如果模型结果对某个参数非常敏感,要做敏感性分析。例如将缓冲区距离分别设为 300 米、500 米、800 米,比较输出范围和统计结果是否剧烈变化。这样可以判断结果是否稳定。
技巧五:用抽样核查和交叉验证检查结果是否可信
提升空间分析与建模精度,最后一步一定是验证。没有验证的空间分析结果,只能叫“模型输出”,不能直接叫“可靠结论”。
常用验证方法包括:
- 随机抽样检查:从结果图层中抽取样本点或样本面,逐一核对原始影像、外业点或权威数据。
- 统计对比:将面积、数量、长度等结果与已有台账、年鉴或历史成果对比。
- 空间叠加验证:将分析结果与已知边界、监测点、业务事件点进行叠加检查。
- 分区验证:按行政区、流域、网格或业务片区分别统计,检查是否存在局部异常。
- 交叉验证:在插值、预测、分类模型中,保留一部分样本不参与建模,用来检验模型效果。
验证时不要只看总体精度。总体结果可能看起来合理,但局部区域存在明显错误。对于 GIS 项目,局部错误经常比总体误差更影响实际使用。
常见坑:这些问题会让空间分析结果看起来正常但实际不准
- 只看地图显示,不看数据坐标系。图层在软件中能叠上,不代表分析时坐标系正确。
- 把经纬度单位当成米。经纬度的单位是度,不适合直接做米级距离分析。
- 忽略 NoData 值。栅格分析中 NoData 区域如果处理不当,会影响叠加、统计和分类结果。
- 不同数据时间不一致。用 2024 年道路数据叠加 2018 年土地利用数据,结论可能不具备现实意义。
- 叠加分析后不检查面积守恒。裁剪、相交、融合后,应对比前后面积总和是否异常。
- 过度依赖默认参数。GIS 软件默认值通常只是能运行,不一定适合你的研究场景。
- 忽略边界效应。缓冲区、插值、核密度分析在研究区边界附近常出现偏差。
方法比较:QGIS、ArcGIS Pro、PostGIS 和 Python GIS 怎么选
| 方法 | 适合场景 | 优势 | 注意事项 |
|---|---|---|---|
| QGIS | 日常数据检查、投影转换、叠加分析、制图输出 | 开源、插件丰富、适合教学和快速处理 | 批量流程要注意参数记录和数据版本管理 |
| ArcGIS Pro | 规范化生产、复杂空间分析、企业项目交付 | 工具体系完整,ModelBuilder 和地理处理工具成熟 | 需注意许可、环境设置和工具参数解释 |
| PostGIS | 大规模矢量数据、空间查询、服务端分析 | 适合数据库化管理和可重复分析 | 需要建立空间索引,并检查 SRID 和几何有效性 |
| Python GIS | 批处理、自动化建模、可重复研究 | GeoPandas、Rasterio、GDAL、ArcPy 可组合使用 | 要严格记录环境版本、坐标系和中间数据输出 |
如果只是处理少量数据并检查空间分析结果,QGIS 或 ArcGIS Pro 更直观。如果要处理大量数据、反复执行同一套空间分析流程,建议使用 PostGIS 或 Python GIS 建立可重复流程。
检查清单:GIS数据处理前后必须核对的项目
下面这份清单适合在缓冲区分析、叠加分析、栅格建模、适宜性评价、空间统计之前使用。
数据输入检查
- 数据来源是否可靠,是否有元数据说明。
- 数据时间是否满足当前项目需求。
- 字段含义、单位、编码是否明确。
- 是否存在缺失值、异常值、重复记录。
- 矢量数据是否存在几何错误。
- 栅格数据是否明确 NoData 值。
坐标系检查
- 每个图层是否有正确坐标参考系。
- 是否区分了定义坐标系和投影转换。
- 用于距离和面积计算的数据是否为投影坐标系。
- 不同来源数据是否存在明显空间偏移。
- 分析结果单位是否和业务要求一致。
空间分析参数检查
- 缓冲区距离是否有业务依据。
- 叠加分析是否需要容差控制。
- 栅格像元大小是否与研究尺度匹配。
- 重采样方法是否符合数据类型。
- 权重、阈值、分级标准是否有记录。
结果输出检查
- 输出图层坐标系是否正确。
- 面积、长度、数量统计是否与预期一致。
- 是否存在异常碎面、空几何或重复要素。
- 是否抽样核查了局部区域。
- 是否保存了处理日志、中间数据和参数说明。
FAQ
空间分析结果不准,第一步应该检查什么?
第一步建议检查坐标系和单位。尤其是面积、距离、缓冲区、邻近分析,如果输入数据是经纬度坐标,却直接按米计算,很容易导致空间分析结果不准。
为什么 QGIS 中图层能重合,分析结果却不对?
因为图层显示时可能使用了动态投影。动态投影能让图层在地图窗口看起来重合,但不代表数据已经真正转换到同一投影坐标系。正式分析前,应将图层重新投影并保存为新的数据文件。
空间分析与建模精度提升一定要用高精度数据吗?
不一定。关键是数据精度要和分析目标匹配。做城市地块级分析需要较高精度数据;做全国尺度趋势分析,则不一定需要非常精细的数据。高精度数据也可能带来更高处理成本和更复杂的数据清洗工作。
叠加分析后出现很多碎小面怎么办?
先检查输入数据是否存在边界不一致、拓扑错误或坐标偏移。然后根据业务需求决定是否使用融合、消除碎面、设置容差或边界统一处理。不要直接删除碎小面,除非确认它们是误差而不是合法地物。
栅格建模中像元大小应该怎么选?
像元大小应结合原始数据分辨率、研究尺度和计算成本决定。不要把低分辨率数据强行重采样成很高分辨率,因为这不会增加真实信息量,反而可能让模型结果显得“很精细但不真实”。
如何判断空间模型结果是否可信?
至少要做三类检查:一是统计结果是否合理,二是空间分布是否符合业务认知,三是抽样点或独立数据验证是否支持模型结论。对于重要项目,还应记录参数来源并进行敏感性分析。
结论
空间分析结果不准,通常不是单个工具的问题,而是数据、坐标系、拓扑、参数和验证共同作用的结果。想要提升空间分析与建模精度,建议从 5 个核心环节入手:统一坐标系,清洗几何和拓扑错误,匹配分析尺度和数据精度,记录参数来源,并对结果进行抽样核查和交叉验证。
实际项目中,最可靠的做法不是“跑完工具就交结果”,而是建立一套可复查的 GIS 数据处理清单。每次分析前先检查输入数据,每次输出后再验证结果,这样才能让空间分析成果真正经得起项目汇报、论文复现和业务应用的检验。