Python地理处理效率低?批量裁剪与拼接地图实战技巧(附:矢量数据处理脚本)
《Python地理处理效率低?批量裁剪与拼接地图实战技巧(附:矢量数据处理脚本)》这篇文章面向已经会一点 Python GIS、但在批量裁剪、影像拼接和矢量数据处理时经常遇到“跑得慢、结果乱、内存爆”的读者。我们不讲泛泛的性能优化,而是围绕一个常见生产场景:用行政区矢量边界批量裁剪栅格影像,再把裁剪结果按规则拼接或输出给后续制图与分析。
引言:为什么 Python 地理处理效率低经常发生
很多 GIS 初学者第一次用 Python 做地理处理时,会把桌面 GIS 的思路直接搬到脚本里:一层一层读取、一条一条循环、每个文件都完整打开、所有数据一次性放进内存。小数据看不出问题,一旦遇到几十幅影像、几百个行政区、几万条矢量要素,Python 地理处理效率低的问题就会非常明显。
本文重点解决三个实际问题:
- 如何用 Python 批量裁剪栅格影像,避免重复读取和坐标系错误。
- 如何用 Python 拼接地图或影像瓦片,减少无效 IO 和内存占用。
- 如何编写一个可复用的矢量数据处理脚本,用于筛选、投影转换、裁剪和输出。
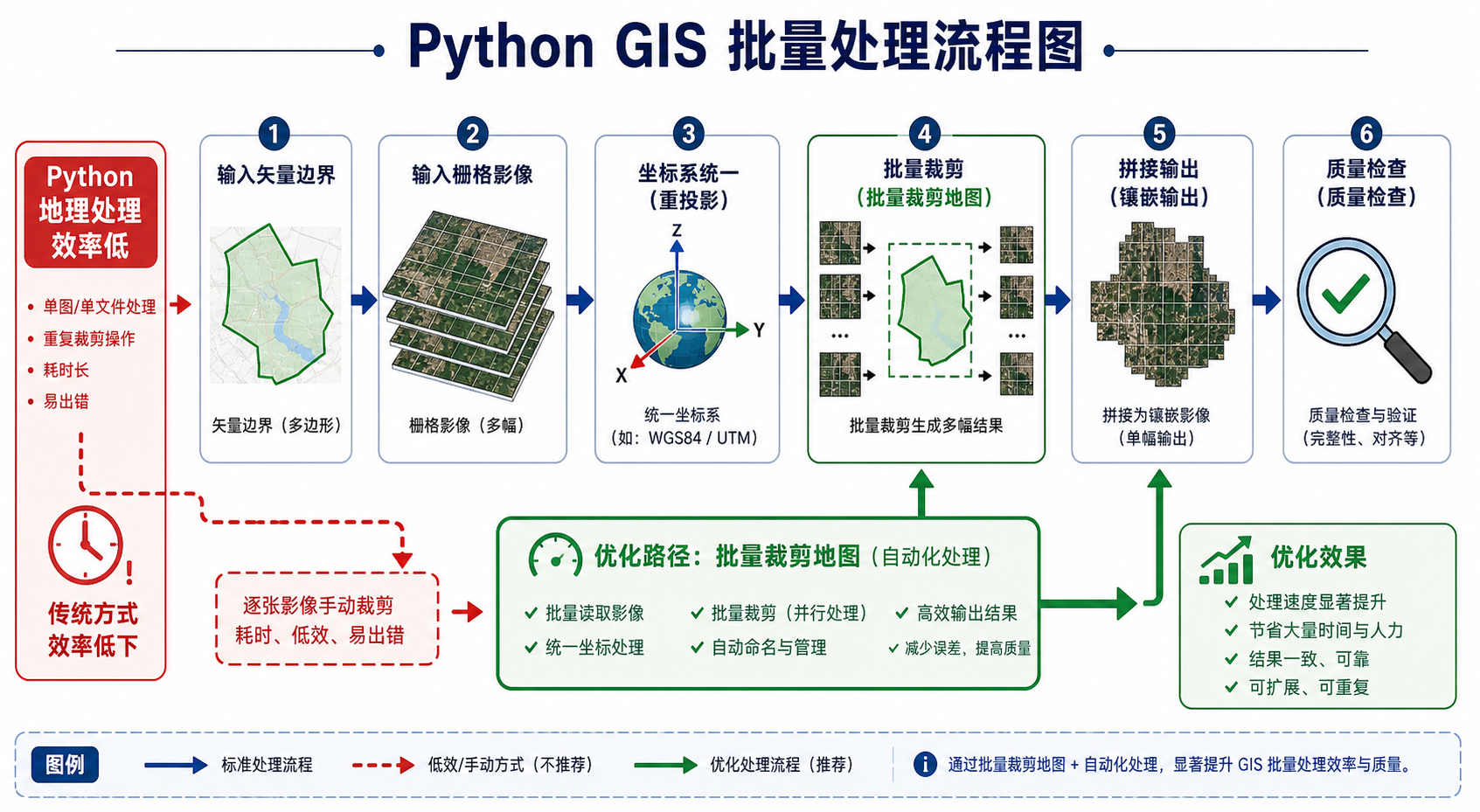
背景:批量裁剪与拼接地图的典型数据场景
一个常见任务是:你有一批遥感影像、DEM、土地利用栅格或专题图,同时有一个行政区划矢量边界,需要按区县批量裁剪栅格,并把部分结果拼接成区域底图。这个任务在 QGIS、ArcGIS Pro 中可以通过工具箱完成,但如果每天都要重复处理、文件数量很多,用 Python 自动化会更合适。
本文示例假设数据结构如下:
project/
data/
raster/
tile_01.tif
tile_02.tif
tile_03.tif
vector/
county_boundary.shp
output/
clipped/
mosaic/
vector_clean/
scripts/
batch_clip_mosaic.py
建议使用的 Python GIS 库包括:
- GeoPandas:读取、筛选、投影转换和输出矢量数据。
- Rasterio:读取、裁剪、写出 GeoTIFF 栅格。
- Shapely:处理矢量几何对象。
- rasterio.merge:拼接多幅栅格影像。
- Fiona / Pyogrio:作为 GeoPandas 的底层矢量读写引擎。
如果你只处理少量数据,QGIS 图形界面更快;如果数据量大、流程固定、需要反复执行,Python 批量裁剪地图和批量拼接影像更适合自动化。
原理:影响 Python 地理处理效率的关键因素
Python 地理处理效率低,通常不是因为 Python 本身“不能做 GIS”,而是因为空间数据处理有几个天然成本:磁盘 IO、坐标转换、几何计算、栅格重采样和大数组内存占用。
1. 坐标系不一致会导致重复计算
矢量边界和栅格影像如果不在同一坐标系下,裁剪前必须进行投影转换。若在循环中对每个文件、每个要素重复转换,效率会明显下降。更好的方式是:先读取一次数据,判断 CRS,也就是坐标参考系统,然后统一转换。
2. 一次性读取整幅影像会浪费内存
很多影像文件很大,但裁剪范围可能只占其中一小部分。如果脚本每次都完整读取整幅影像,再做掩膜裁剪,会产生大量不必要的内存占用。Rasterio 的窗口读取和 mask 裁剪可以减少这类开销。
3. 矢量要素不先筛选会增加无效循环
如果一个省级边界文件中包含上百个区县,而当前影像只覆盖其中几个区县,直接对所有边界循环裁剪会产生很多空结果。应先用边界框相交关系过滤候选要素,再进行精确裁剪。
4. 拼接影像前不检查分辨率和 CRS 会导致结果异常
批量拼接地图不是简单把多个 tif 文件放在一起。输入影像必须重点检查坐标系、像元大小、波段数、NoData 值和数据类型。如果这些参数不一致,拼接结果可能出现偏移、黑边、锯齿或统计值错误。
步骤:Python 批量裁剪地图与拼接影像实战
步骤 1:准备 Python GIS 环境
建议使用 Conda 环境安装 GIS 依赖,避免 GDAL、Fiona、Rasterio 之间的二进制依赖冲突。
conda create -n pygis python=3.11 -y
conda activate pygis
conda install -c conda-forge geopandas rasterio shapely pyogrio tqdm -y
如果你在 Windows 上直接使用 pip 安装失败,优先改用 conda-forge。很多 Python GIS 安装问题并不是代码错误,而是 GDAL 相关依赖没有正确安装。
步骤 2:读取并清理矢量边界
先处理矢量数据,是提高后续批量裁剪效率的关键。下面的脚本会读取行政区边界,修复无效几何,并按字段筛选需要处理的区域。
from pathlib import Path
import geopandas as gpd
base_dir = Path("project")
vector_path = base_dir / "data" / "vector" / "county_boundary.shp"
clean_vector_path = base_dir / "output" / "vector_clean" / "county_boundary_clean.gpkg"
clean_vector_path.parent.mkdir(parents=True, exist_ok=True)
gdf = gpd.read_file(vector_path)
if gdf.crs is None:
raise ValueError("矢量数据缺少 CRS,请先在 QGIS 或 ArcGIS Pro 中定义坐标系。")
gdf = gdf[gdf.geometry.notnull()].copy()
gdf["geometry"] = gdf.geometry.buffer(0)
gdf = gdf[~gdf.geometry.is_empty].copy()
if "NAME" in gdf.columns:
gdf = gdf[gdf["NAME"].notnull()].copy()
gdf.to_file(clean_vector_path, driver="GPKG")
print(f"清理后的矢量已输出:{clean_vector_path}")
print(f"要素数量:{len(gdf)}")
print(f"坐标系:{gdf.crs}")
这里的 buffer(0) 是一种常见的简单几何修复方法,适合处理轻微自相交、多边形环方向异常等问题。但它不是万能的。如果边界严重破碎,仍建议先在 QGIS 的“修复几何图形”或 ArcGIS Pro 的 Repair Geometry 工具中检查。
步骤 3:按矢量边界批量裁剪栅格影像
下面的脚本使用 Rasterio 的 mask 方法按矢量边界裁剪栅格。重点是:每次打开栅格后,先把矢量投影到栅格 CRS,再做空间过滤,避免对完全不相交的边界做无效裁剪。
from pathlib import Path
import geopandas as gpd
import rasterio
from rasterio.mask import mask
from shapely.geometry import box
from tqdm import tqdm
base_dir = Path("project")
raster_dir = base_dir / "data" / "raster"
vector_path = base_dir / "output" / "vector_clean" / "county_boundary_clean.gpkg"
clip_dir = base_dir / "output" / "clipped"
clip_dir.mkdir(parents=True, exist_ok=True)
gdf = gpd.read_file(vector_path)
raster_files = sorted(raster_dir.glob("*.tif"))
for raster_path in tqdm(raster_files, desc="批量裁剪栅格"):
with rasterio.open(raster_path) as src:
if src.crs is None:
print(f"跳过无 CRS 栅格:{raster_path.name}")
continue
gdf_proj = gdf.to_crs(src.crs)
raster_bounds = box(*src.bounds)
candidates = gdf_proj[gdf_proj.intersects(raster_bounds)].copy()
if candidates.empty:
print(f"无相交边界,跳过:{raster_path.name}")
continue
for idx, row in candidates.iterrows():
geom = [row.geometry]
try:
out_image, out_transform = mask(
src,
geom,
crop=True,
nodata=src.nodata
)
except ValueError:
continue
out_meta = src.meta.copy()
out_meta.update({
"driver": "GTiff",
"height": out_image.shape[1],
"width": out_image.shape[2],
"transform": out_transform,
"compress": "lzw"
})
name_value = row["NAME"] if "NAME" in candidates.columns else str(idx)
safe_name = str(name_value).replace("/", "_").replace("", "_")
out_path = clip_dir / f"{raster_path.stem}_{safe_name}.tif"
with rasterio.open(out_path, "w", **out_meta) as dst:
dst.write(out_image)
这个批量裁剪地图脚本适合用于 DEM、土地利用、栅格专题图、单波段或多波段 GeoTIFF。需要注意,如果输入影像非常大,且输出数量很多,磁盘写出速度可能成为瓶颈,此时应优先使用 SSD,并减少重复输出。
步骤 4:批量拼接裁剪后的地图结果
当你需要把多个裁剪结果合并成一张区域图时,可以使用 rasterio.merge.merge。拼接前请确保输入文件属于同一坐标系、同一分辨率和同一波段结构。
from pathlib import Path
import rasterio
from rasterio.merge import merge
base_dir = Path("project")
clip_dir = base_dir / "output" / "clipped"
mosaic_dir = base_dir / "output" / "mosaic"
mosaic_dir.mkdir(parents=True, exist_ok=True)
clip_files = sorted(clip_dir.glob("*.tif"))
src_list = []
for path in clip_files:
src = rasterio.open(path)
src_list.append(src)
if not src_list:
raise ValueError("没有可拼接的裁剪结果。")
mosaic, out_transform = merge(src_list)
out_meta = src_list[0].meta.copy()
out_meta.update({
"driver": "GTiff",
"height": mosaic.shape[1],
"width": mosaic.shape[2],
"transform": out_transform,
"compress": "lzw"
})
out_path = mosaic_dir / "mosaic_result.tif"
with rasterio.open(out_path, "w", **out_meta) as dst:
dst.write(mosaic)
for src in src_list:
src.close()
print(f"拼接完成:{out_path}")
如果拼接结果出现黑边,通常与 NoData 设置有关。可以先检查每个输入 tif 的 src.nodata,必要时统一设置 NoData 值后再拼接。
步骤 5:添加批处理日志,方便定位慢在哪里
很多人感觉 Python 地理处理效率低,但不知道慢在读取、裁剪、投影还是写出。建议给脚本添加简单计时日志。
import time
start = time.perf_counter()
# 在这里执行某个处理步骤
end = time.perf_counter()
print(f"当前步骤耗时:{end - start:.2f} 秒")
如果发现主要耗时在读取和写出,优化方向是减少文件数量、使用更快磁盘、合并中间步骤;如果主要耗时在几何计算,优化方向是先做空间过滤、简化几何或建立空间索引。
常见坑:批量裁剪地图最容易出错的地方
坑 1:矢量和栅格 CRS 看起来一样,实际上不一致
有些数据的坐标系名称相似,但 EPSG 编码、基准面或投影参数不同。不要只看“WGS84”或“CGCS2000”这类名称,脚本中应打印 gdf.crs 和 src.crs 做确认。
坑 2:误把定义坐标系当成投影转换
定义坐标系是告诉软件“这个数据本来是什么坐标系”;投影转换是把坐标值从一个坐标系转换到另一个坐标系。若原始数据坐标系定义错了,后面所有 Python 批量裁剪地图结果都会偏移。
坑 3:循环里反复读取同一个矢量文件
有些脚本会在每个栅格循环中重新 gpd.read_file,这会产生大量无意义 IO。更好的方式是脚本开始时读取一次矢量数据,然后在每个栅格内部按 CRS 转换和空间过滤。
坑 4:矢量几何太复杂导致裁剪很慢
海岸线、河流边界、精细行政边界可能包含大量节点。若只是做中小比例尺出图,可以先对矢量做适度简化。但要注意,简化会改变边界形状,不适合高精度面积统计或权属边界分析。
坑 5:拼接前没有统一 NoData 值
不同来源的栅格可能使用 0、255、-9999 或空值作为 NoData。拼接地图时如果 NoData 不统一,可能出现黑色边框、白色块、透明区域失效等问题。
坑 6:Shapefile 字段名被截断
Shapefile 字段名长度有限,中文字段和长字段名容易出现乱码或截断。建议中间结果优先使用 GeoPackage,也就是 .gpkg,它更适合现代 Python GIS 流程。
方法比较:QGIS、ArcGIS Pro 与 Python 批处理怎么选
| 方法 | 适合场景 | 优点 | 限制 |
|---|---|---|---|
| QGIS 图形界面 | 少量裁剪、临时制图、教学演示 | 上手快,参数可视化,插件丰富 | 大量重复任务容易手工出错 |
| ArcGIS Pro 工具箱 | 企业内部标准流程、地理数据库环境 | 工具成熟,模型构建器方便 | 授权和环境依赖较强 |
| Python GeoPandas | 矢量筛选、投影转换、属性清洗 | 脚本清晰,适合表格化空间数据处理 | 超大矢量数据需要注意内存 |
| Python Rasterio | 栅格裁剪、读取、写出、拼接 | 适合自动化批处理,能精细控制参数 | 需要理解 CRS、transform、NoData 等概念 |
| GDAL 命令行 | 大规模格式转换、重投影、切片 | 性能强,生产环境常用 | 参数较多,初学者理解成本较高 |
如果你的需求是一次性处理几幅图,QGIS 或 ArcGIS Pro 更直接;如果你的需求是每天、每周或每个项目都重复执行同一套批量裁剪与拼接地图流程,Python 脚本更值得投入。
检查清单:运行脚本前后必须确认的事项
处理前检查
- 矢量边界是否有 CRS,是否与真实坐标一致。
- 栅格影像是否有 CRS、NoData、像元大小和正确范围。
- 矢量与栅格是否存在空间相交关系。
- 输出目录是否有写入权限。
- 字段名是否适合作为输出文件名。
- 输入数据是否包含中文路径,若报错可先改为英文路径测试。
处理中检查
- 是否出现大量“无相交边界,跳过”。
- 是否有裁剪结果尺寸异常小或异常大。
- 内存是否持续升高不释放。
- 磁盘空间是否足够保存中间结果。
- 日志中是否有 CRS 缺失、几何无效或写出失败提示。
处理后检查
- 把裁剪结果加载到 QGIS 或 ArcGIS Pro 中,检查是否与边界吻合。
- 抽查几个输出 tif 的范围、像元大小、NoData 和坐标系。
- 检查拼接结果是否有黑边、错位、重叠覆盖异常。
- 对关键区域进行局部放大,确认没有投影偏移。
- 如果用于面积或统计分析,确认使用的是合适的投影坐标系。
FAQ:Python 批量裁剪与拼接地图常见问题
Python 地理处理效率低,第一步应该优化什么?
先不要急着改算法,应该先定位瓶颈。用计时日志分别记录读取、投影转换、空间过滤、裁剪、写出和拼接的耗时。多数批量裁剪地图任务的瓶颈不是单纯计算,而是重复读取文件、无效循环和大量中间结果写出。
批量裁剪地图时,为什么结果是空的?
常见原因有三个:矢量和栅格坐标系不一致、矢量边界与栅格范围确实不相交、或者矢量几何无效。建议先在 QGIS 中把两类数据加载到同一个工程里检查位置,再用脚本打印 src.bounds、gdf.total_bounds 和 CRS。
Python 拼接地图结果出现黑边怎么办?
优先检查 NoData 值。不同影像如果 NoData 设置不同,拼接时可能把背景值当作有效像元。可以在裁剪时明确设置 nodata,并在拼接前统一输入栅格的 NoData、数据类型和波段数。
GeoPandas 处理矢量数据很慢怎么办?
可以从三个方面优化:减少字段,只保留必要属性;先用边界框过滤候选要素;中间格式改用 GeoPackage 或 Parquet。对于特别大的数据,也可以考虑 PostGIS,把空间过滤和索引查询交给数据库完成。
裁剪前是否必须把所有数据转成同一个投影?
不一定必须提前转换所有文件,但裁剪运算时矢量和栅格必须处于同一 CRS。本文脚本采用的方式是:以每个栅格的 CRS 为准,把矢量临时转换过去。这样适合多幅栅格 CRS 相同或少量不同的情况。如果数据源很稳定,也可以提前统一投影,减少循环中的转换成本。
矢量数据处理脚本为什么建议输出 GeoPackage?
GeoPackage 支持较长字段名、中文属性、多图层和更稳定的编码表现,比 Shapefile 更适合作为 Python GIS 的中间数据格式。Shapefile 仍然常见,但在批量自动化流程中更容易遇到字段截断、编码和多文件管理问题。
结论:让 Python 地理处理更快,关键是减少无效工作
Python 地理处理效率低,通常不是因为工具选错了,而是流程设计不合理。批量裁剪与拼接地图时,应把重点放在坐标系统一、空间过滤、减少重复读取、控制中间文件和规范输出参数上。
推荐你在实际项目中采用这样的顺序:先清理矢量边界,再检查 CRS 和范围,然后批量裁剪栅格,最后按需要拼接地图并做结果抽查。只要把这些环节固定成脚本,Python 就不只是“能处理 GIS 数据”,而是可以成为稳定的地理处理自动化工具。