Python地理处理如何提升效率?批量处理地理数据实战技巧(附:代码库)
《Python地理处理如何提升效率?批量处理地理数据实战技巧(附:代码库)》这篇文章面向需要反复处理矢量、栅格、表格和坐标转换任务的 GIS 学习者与工程师,重点解决一个实际问题:如何用 Python 地理处理把重复、易出错、耗时的 GIS 操作变成可复用、可检查、可批量运行的工作流。
引言:为什么要用 Python 地理处理做批量任务
很多 GIS 工作并不难,但非常重复。例如批量投影 Shapefile、统一字段名、裁剪多个影像、计算面积、导出 GeoJSON、修复无效几何、批量叠加分析等。如果每个文件都手动在 QGIS 或 ArcGIS Pro 中点一遍,效率低,结果也不容易复现。
Python 地理处理的价值不只是“自动化”,更重要的是把处理逻辑写成脚本,让每一步都有输入、输出、日志和错误提示。这样你可以在 10 个文件上测试,再扩展到 1000 个文件,而不用担心漏选参数或误点工具。
建议把 Python 地理处理理解为“可复现的 GIS 生产线”:输入数据进入脚本,经过检查、转换、分析和导出,最后得到结构一致、质量可控的成果数据。
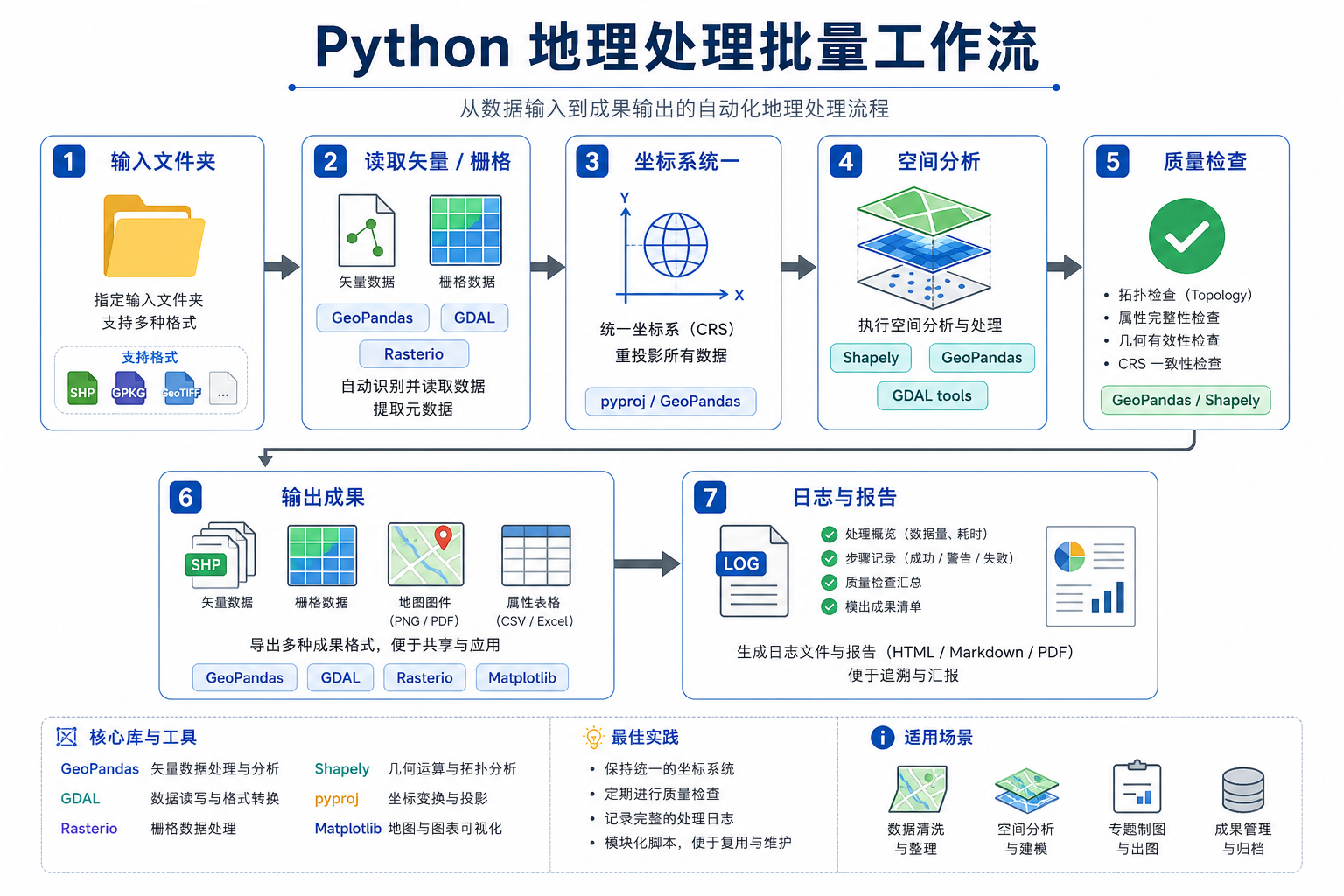
背景:GIS 批量处理地理数据常见低效场景
在实际项目中,Python 地理处理通常用于解决以下几类效率问题。
- 文件数量多:几十到几千个 Shapefile、GeoPackage、GeoTIFF、CSV 坐标表需要统一处理。
- 参数重复:每个数据都要做相同的投影、裁剪、字段计算、格式转换或空间连接。
- 数据来源杂:不同坐标系、不同编码、不同字段名、不同几何类型混在一起。
- 结果需要复查:需要知道哪些文件成功、哪些失败、失败原因是什么。
- 人工操作不可追溯:手动处理后很难确认当时选择了哪些参数。
如果只是偶尔处理一个文件,图形界面工具很方便。但当任务开始变成批量生产,Python 地理处理就更适合,因为脚本可以把流程标准化,并减少人工操作误差。
原理:Python 地理处理提升效率的核心思路
要让 Python 地理处理真正提升效率,不能只写一个“能跑”的脚本,而要按工作流来设计。一个稳定的批量处理脚本通常包括五个部分。
- 输入扫描:自动遍历文件夹,识别需要处理的数据格式。
- 数据检查:检查坐标系、字段、几何类型、空数据和无效几何。
- 统一处理:执行投影转换、裁剪、叠加、统计、格式转换等核心操作。
- 输出管理:按照规则命名成果文件,避免覆盖原始数据。
- 日志记录:记录成功、失败、耗时、错误信息,方便复查。
常用 Python GIS 库可以按任务类型这样理解。
| 任务类型 | 常用库 | 适合场景 |
|---|---|---|
| 矢量数据读写与处理 | GeoPandas、Fiona、Shapely | Shapefile、GeoPackage、GeoJSON 的字段处理、空间连接、缓冲区、叠加分析 |
| 栅格数据处理 | Rasterio、GDAL | GeoTIFF 裁剪、重投影、波段读取、栅格统计、格式转换 |
| 坐标转换 | pyproj、GeoPandas | 坐标系识别、EPSG 转换、投影统一 |
| 批量调度与文件管理 | pathlib、os、glob、logging | 遍历目录、创建输出文件夹、记录日志 |
| 空间数据库处理 | SQLAlchemy、GeoAlchemy2、psycopg | PostGIS 数据导入、查询、空间索引与批量更新 |
步骤:Python 地理处理批量处理地理数据实战
步骤 1:建立推荐项目目录
批量处理地理数据时,先把目录结构整理好。不要直接在原始数据文件夹里输出成果,避免覆盖和混乱。
gis_batch_project/
├── data_raw/ # 原始数据,只读
├── data_work/ # 中间数据
├── data_output/ # 最终成果
├── logs/ # 日志
├── scripts/ # Python 脚本
└── config/ # 参数配置这个目录结构的好处是:原始数据安全,中间过程可清理,最终成果容易交付,日志可以追踪问题。
步骤 2:安装常用 Python GIS 环境
如果你主要使用 GeoPandas、Rasterio、GDAL,推荐使用 conda 环境,能减少底层依赖安装问题。
conda create -n gisbatch python=3.11
conda activate gisbatch
conda install -c conda-forge geopandas rasterio gdal pyproj shapely fiona pandas如果你使用 pip,也可以安装核心库,但在 Windows 环境下 GDAL 相关依赖更容易遇到版本匹配问题。
pip install geopandas rasterio pyproj shapely pandas建议先运行下面的检查代码,确认环境可用。
import geopandas as gpd
import rasterio
import shapely
import pyproj
print("GeoPandas:", gpd.__version__)
print("Rasterio:", rasterio.__version__)
print("Shapely:", shapely.__version__)
print("pyproj:", pyproj.__version__)步骤 3:批量读取矢量数据并统一坐标系
下面的代码示例用于批量读取文件夹中的 Shapefile,把它们统一转换为 EPSG:4490,并输出为 GeoPackage。你可以把目标坐标系改成项目要求的 EPSG 编号。
from pathlib import Path
import geopandas as gpd
import logging
raw_dir = Path("data_raw")
out_dir = Path("data_output")
log_dir = Path("logs")
out_dir.mkdir(exist_ok=True)
log_dir.mkdir(exist_ok=True)
logging.basicConfig(
filename=log_dir / "vector_batch.log",
level=logging.INFO,
format="%(asctime)s - %(levelname)s - %(message)s",
encoding="utf-8"
)
target_crs = "EPSG:4490"
for shp_path in raw_dir.rglob("*.shp"):
try:
logging.info(f"开始处理:{shp_path}")
gdf = gpd.read_file(shp_path)
if gdf.empty:
logging.warning(f"空数据,跳过:{shp_path}")
continue
if gdf.crs is None:
logging.warning(f"缺少坐标系,跳过:{shp_path}")
continue
gdf = gdf.to_crs(target_crs)
out_path = out_dir / f"{shp_path.stem}_epsg4490.gpkg"
gdf.to_file(out_path, layer=shp_path.stem, driver="GPKG")
logging.info(f"处理完成:{out_path}")
except Exception as e:
logging.exception(f"处理失败:{shp_path},原因:{e}")这段 Python 地理处理脚本做了三件关键事情:递归查找 Shapefile、检查空数据和坐标系、将结果写入 GeoPackage。相比手动逐个转换,它更适合批量处理地理数据。
步骤 4:批量修复无效几何
很多空间叠加、裁剪、缓冲区失败,并不是工具坏了,而是数据存在自相交、空几何或破碎面。Shapely 2.x 中可以使用 make_valid 修复常见无效几何。
from pathlib import Path
import geopandas as gpd
from shapely.validation import make_valid
in_dir = Path("data_raw")
out_dir = Path("data_output")
out_dir.mkdir(exist_ok=True)
for file_path in in_dir.rglob("*.shp"):
gdf = gpd.read_file(file_path)
if gdf.empty:
continue
invalid_count = (~gdf.geometry.is_valid).sum()
print(file_path.name, "无效几何数量:", invalid_count)
gdf["geometry"] = gdf.geometry.apply(
lambda geom: make_valid(geom) if geom is not None and not geom.is_valid else geom
)
out_path = out_dir / f"{file_path.stem}_valid.gpkg"
gdf.to_file(out_path, driver="GPKG")修复完成后,不要只看脚本是否报错,还要检查几何类型是否发生变化。例如某些无效面修复后可能变成 MultiPolygon 或 GeometryCollection,这会影响后续叠加分析。
步骤 5:批量计算面积并写入字段
面积计算必须在合适的投影坐标系下进行。如果数据是经纬度坐标系,例如 EPSG:4326 或 EPSG:4490,直接计算面积会得到“度”的平方,不是平方米。
from pathlib import Path
import geopandas as gpd
in_dir = Path("data_raw")
out_dir = Path("data_output")
out_dir.mkdir(exist_ok=True)
area_crs = "EPSG:3857"
for file_path in in_dir.rglob("*.shp"):
gdf = gpd.read_file(file_path)
if gdf.empty or gdf.crs is None:
continue
gdf_area = gdf.to_crs(area_crs)
gdf["area_m2"] = gdf_area.geometry.area
gdf["area_ha"] = gdf["area_m2"] / 10000
out_path = out_dir / f"{file_path.stem}_area.gpkg"
gdf.to_file(out_path, driver="GPKG")这里的 EPSG:3857 只是示例。正式项目中,建议使用适合研究区的投影坐标系,例如国家或地方标准投影、等面积投影,或项目指定坐标系。
步骤 6:批量裁剪栅格数据
影像、DEM、土地覆盖数据经常需要按行政区或研究区边界裁剪。下面示例使用 Rasterio 根据一个矢量边界批量裁剪 GeoTIFF。
from pathlib import Path
import geopandas as gpd
import rasterio
from rasterio.mask import mask
raster_dir = Path("data_raw/rasters")
boundary_path = Path("data_raw/boundary/study_area.shp")
out_dir = Path("data_output/rasters")
out_dir.mkdir(parents=True, exist_ok=True)
boundary = gpd.read_file(boundary_path)
for tif_path in raster_dir.rglob("*.tif"):
with rasterio.open(tif_path) as src:
if boundary.crs != src.crs:
boundary_proj = boundary.to_crs(src.crs)
else:
boundary_proj = boundary
geoms = [geom for geom in boundary_proj.geometry if geom is not None]
out_image, out_transform = mask(src, geoms, crop=True)
out_meta = src.meta.copy()
out_meta.update({
"height": out_image.shape[1],
"width": out_image.shape[2],
"transform": out_transform
})
out_path = out_dir / f"{tif_path.stem}_clip.tif"
with rasterio.open(out_path, "w", **out_meta) as dest:
dest.write(out_image)
print("完成:", out_path)栅格批量处理时,坐标系一致性非常关键。边界矢量和栅格如果坐标系不一致,裁剪结果可能为空、错位或范围异常。
步骤 7:把常用代码整理成可复用代码库
当脚本越来越多时,不建议每次复制粘贴。可以把常用功能封装成一个小型代码库,例如 gis_utils.py。
from pathlib import Path
import geopandas as gpd
def list_files(folder, suffix):
folder = Path(folder)
return list(folder.rglob(f"*{suffix}"))
def read_vector(path):
gdf = gpd.read_file(path)
if gdf.empty:
raise ValueError(f"空数据:{path}")
if gdf.crs is None:
raise ValueError(f"缺少坐标系:{path}")
return gdf
def reproject_vector(input_path, output_path, target_crs):
gdf = read_vector(input_path)
gdf = gdf.to_crs(target_crs)
output_path = Path(output_path)
output_path.parent.mkdir(parents=True, exist_ok=True)
gdf.to_file(output_path, driver="GPKG")
return output_path然后在主脚本中调用。
from pathlib import Path
from gis_utils import list_files, reproject_vector
raw_dir = Path("data_raw")
out_dir = Path("data_output")
for shp in list_files(raw_dir, ".shp"):
out_path = out_dir / f"{shp.stem}_4490.gpkg"
reproject_vector(shp, out_path, "EPSG:4490")
print("完成:", out_path)这就是“附:代码库”的核心思路:不是堆很多零散脚本,而是把高频能力封装成函数,包括文件扫描、坐标检查、投影转换、几何修复、日志记录和输出命名。
常见坑:Python 地理处理效率低或结果错误的原因
1. 只追求运行速度,不检查结果
批量处理地理数据最怕“全部跑完但结果错了”。每次批量运行后,至少抽查以下内容。
- 输出文件数量是否等于预期数量。
- 坐标系是否符合项目要求。
- 空间范围是否正常,没有整体偏移。
- 属性字段是否丢失、乱码或类型变化。
- 几何是否为空或无效。
2. 经纬度坐标系下直接算面积和距离
这是 Python 地理处理里最常见的错误之一。经纬度单位是度,不适合直接计算面积和距离。正确做法是先转换到合适的投影坐标系,再计算面积、长度或缓冲区。
3. Shapefile 字段名被截断
Shapefile 对字段名长度有限制,长字段名可能被截断。批量处理地理数据时,如果你要保存较多字段,建议优先使用 GeoPackage。
4. 忽略编码问题
中文字段或属性值乱码,常见于 Shapefile 编码不一致。可以尝试在读取时指定编码。
gdf = gpd.read_file("data_raw/example.shp", encoding="utf-8")如果 UTF-8 不正确,可以根据数据来源尝试 GBK,但不要在没有检查的情况下盲目转换。
5. 一次性读取超大数据导致内存不足
GeoPandas 适合中小规模矢量数据处理。如果数据量很大,可以考虑使用 PostGIS、DuckDB Spatial、dask-geopandas,或先按空间范围分块处理。
方法比较:Python、QGIS、ArcGIS Pro 如何选择
| 方法 | 优势 | 局限 | 适合场景 |
|---|---|---|---|
| Python 地理处理 | 自动化强、可复现、适合批量处理地理数据 | 需要编程基础,环境配置可能有门槛 | 批量转换、批量分析、定期生产、数据质检 |
| QGIS 图形界面 | 上手快、插件丰富、适合可视化检查 | 大量重复操作效率较低 | 单次处理、参数探索、结果核查 |
| QGIS Processing 脚本 | 能结合图形工具和 Python 自动化 | 依赖 QGIS 环境,迁移到服务器需额外配置 | 已有 QGIS 工作流,需要半自动化 |
| ArcGIS Pro ModelBuilder | 流程可视化,适合 Esri 体系用户 | 跨平台与开源生态灵活性较弱 | 单位内已有 ArcGIS Pro 授权和标准流程 |
| ArcPy | 与 ArcGIS Pro 工具箱深度集成 | 依赖 ArcGIS 授权和指定 Python 环境 | 需要批量调用 ArcGIS Pro 地理处理工具 |
| PostGIS | 适合大数据量、多人协作和空间查询 | 需要数据库维护能力 | 海量矢量数据、WebGIS 后端、空间数据库分析 |
实际工作中并不是非要二选一。更推荐的组合是:用 QGIS 或 ArcGIS Pro 做参数验证和可视化检查,用 Python 地理处理进行批量生产,用 PostGIS 管理大规模空间数据。
检查清单:运行批量脚本前后必须确认
运行前检查
- 是否备份了原始数据。
- 输入文件夹和输出文件夹是否分开。
- 目标坐标系 EPSG 是否正确。
- 字段名、字段类型、编码是否符合要求。
- 样本数据是否已经测试通过。
- 是否设置日志文件。
- 是否避免覆盖已有成果。
运行中检查
- 脚本是否输出当前处理文件名。
- 失败文件是否被记录,而不是让整个任务中断。
- 处理速度是否异常变慢。
- 内存占用是否过高。
运行后检查
- 输出文件数量是否正确。
- 随机抽查地图位置是否正确。
- 统计要素数量、面积、长度是否合理。
- 查看日志中是否有 warning 或 error。
- 用 QGIS 或 ArcGIS Pro 打开成果做可视化检查。
FAQ:Python 地理处理批量任务常见问题
Q1:Python 地理处理一定比 QGIS 手动操作快吗?
不一定。如果只处理一个文件,QGIS 图形界面可能更快。但当任务需要重复执行、处理文件很多、参数必须一致时,Python 地理处理通常更高效,也更容易复现。
Q2:批量处理地理数据时,为什么结果会整体偏移?
最常见原因是坐标系定义错误或投影转换错误。要区分“定义坐标系”和“转换坐标系”:前者只是告诉软件数据原本是什么坐标系,后者才会真正改变坐标值。
Q3:GeoPandas 适合处理多大的数据?
GeoPandas 适合中小规模矢量数据。数据量很大时,可能遇到内存压力。可以考虑分块处理、使用 GeoPackage 代替 Shapefile,或把数据导入 PostGIS 进行空间查询和分析。
Q4:Python 批量处理 Shapefile 时字段乱码怎么办?
先确认原始数据编码,再尝试在 gpd.read_file 中指定 encoding 参数。常见编码包括 UTF-8 和 GBK。建议最终成果尽量使用 GeoPackage,减少 Shapefile 编码和字段限制问题。
Q5:如何判断批量脚本结果是否可靠?
不要只看脚本是否运行完成。应同时检查日志、输出数量、坐标系、空间范围、要素数量、面积统计和随机样本地图显示。可靠的 Python 地理处理流程一定包含结果验证环节。
Q6:ArcPy 和 GeoPandas 应该选哪个?
如果你的单位主要使用 ArcGIS Pro,并且需要调用 Esri 工具箱,ArcPy 更合适。如果你希望使用开源工具链,处理 Shapefile、GeoPackage、GeoJSON、PostGIS 等数据,GeoPandas 更灵活。
结论:把 Python 地理处理做成可复用生产线
Python 地理处理提升效率的关键,不是写一段临时脚本,而是建立一套可复用的批量处理地理数据流程:统一目录、检查输入、封装函数、记录日志、验证结果。
对于 GIS 学生和初级工程师,建议先从三个高频任务练起:批量投影转换、批量字段计算、批量格式转换。熟练后再加入几何修复、空间叠加、栅格裁剪和数据库处理。
只要脚本能做到“可重复运行、可定位错误、可验证结果”,Python 地理处理就不只是提高速度的工具,而会成为你长期可维护的 GIS 工作方法。