Python地理处理效率低?批量裁剪与投影转换实战(含:地理数据处理PDF)
引言
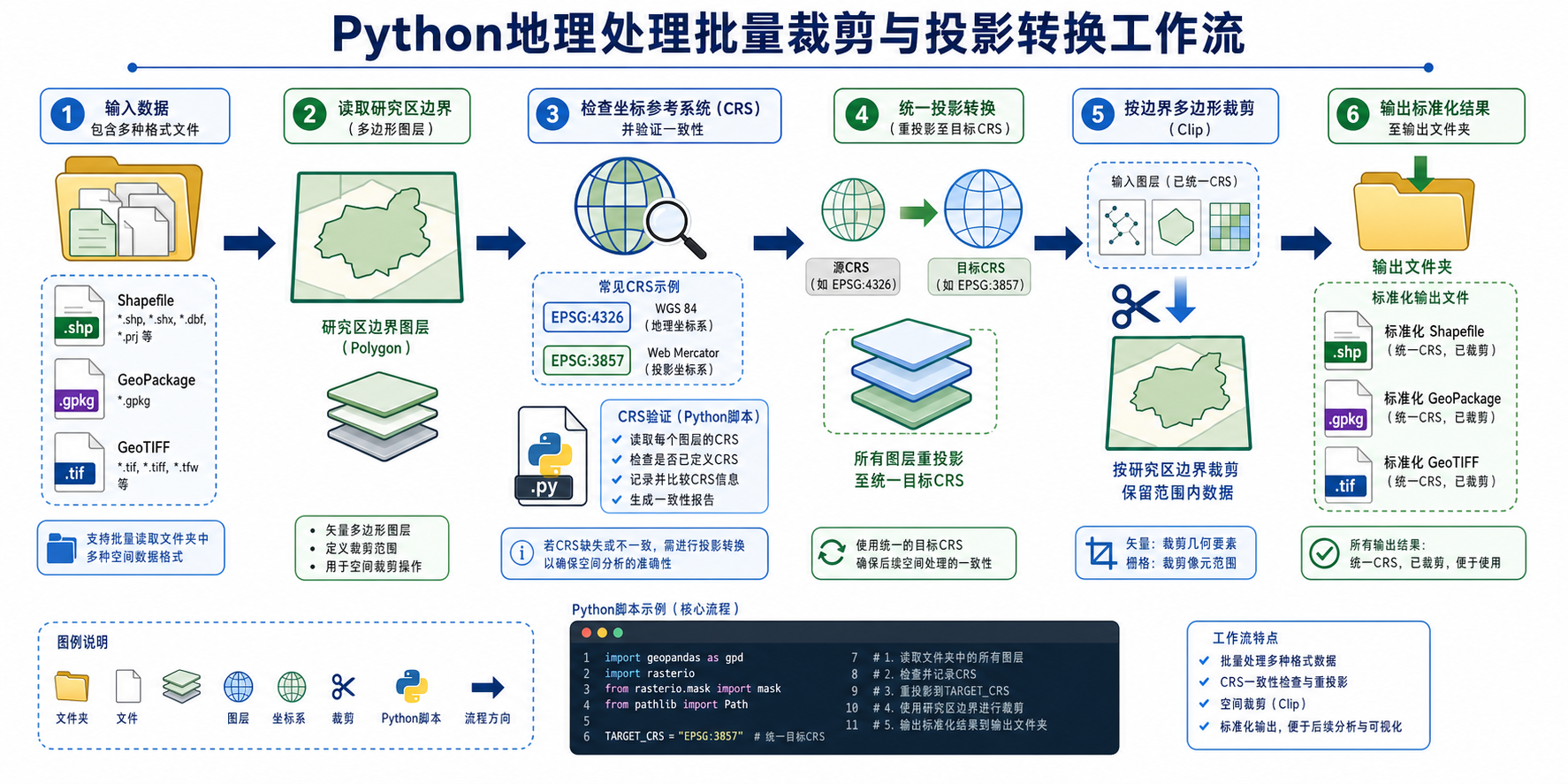
如果你正在搜索“Python地理处理效率低?批量裁剪与投影转换实战(含:地理数据处理PDF)”,大概率遇到的是这样的场景:几十到几百个矢量或栅格文件需要统一裁剪到研究区范围,再转换到同一个坐标系,手工在 QGIS 或 ArcGIS Pro 里逐个处理太慢,而 Python 脚本跑起来又卡、慢、容易报错。
这篇文章以一个常见 GIS 批处理任务为例:使用 Python 对一批地理数据做批量裁剪和投影转换。重点不只是给代码,而是解释为什么 Python 地理处理效率低、哪些步骤最耗时、如何组织数据和脚本,才能让处理过程稳定、可复现、便于交付。
背景
在 GIS 项目中,批量处理通常不是“跑一个工具”这么简单。真实数据往往来自不同单位、不同坐标系、不同格式,甚至同一批数据中还混有无效几何、字段编码异常、空图层和损坏文件。
典型需求包括:
- 把多个行政区、道路、水系、土地利用图层裁剪到项目范围内。
- 将 WGS84、CGCS2000、高斯投影、Web Mercator 等不同坐标系统一到项目坐标系。
- 将 Shapefile 批量转为 GeoPackage,减少字段名截断和编码问题。
- 对栅格影像或 DEM 按研究区范围裁剪,并重投影到指定 EPSG。
- 生成可复查的处理日志,方便写入地理数据处理PDF或项目技术说明。
很多同学觉得 Python 地理处理效率低,常见原因不是 Python 本身慢,而是处理流程设计不合理。例如:每个文件重复读取边界数据、在循环中频繁写磁盘、坐标系不一致还直接裁剪、没有空间索引、一次性把超大数据全部读入内存。
原理
要提高 Python 地理处理效率,需要先理解两个核心操作:投影转换和空间裁剪。
投影转换是把数据从一个坐标参考系统转换到另一个坐标参考系统。坐标参考系统通常用 EPSG 编码表示,例如 EPSG:4326 表示 WGS84 经纬度坐标,EPSG:3857 表示 Web Mercator。对于面积、长度、缓冲区、叠加分析等任务,通常不建议直接使用经纬度坐标做计算。
空间裁剪是用一个边界图层或范围框,保留输入数据中落在边界范围内的部分。矢量裁剪通常涉及几何相交、切割和属性保留;栅格裁剪则涉及像元窗口读取、掩膜和 NoData 设置。
影响效率的关键点主要有四个:
- 坐标系是否一致:裁剪前坐标系不一致,会导致结果为空、偏移或需要隐式转换,增加耗时和风险。
- 数据读取方式:大文件一次性读入内存容易慢,必要时应按文件、按图层、按窗口分批处理。
- 磁盘写入次数:循环中频繁生成临时文件会明显拖慢速度。
- 几何质量:自相交、多部件异常、空几何都会让裁剪失败或变慢。
实战建议:批量裁剪与投影转换的顺序通常是“先检查坐标系和几何质量,再统一投影,最后裁剪”。如果边界很小、输入数据很大,也可以先用边界外包矩形做粗筛,再做精确裁剪。
步骤
步骤一:准备 Python GIS 环境
推荐使用 Conda 创建独立环境,避免 GDAL、Fiona、Rasterio、GeoPandas 之间的底层依赖冲突。
conda create -n pygeo python=3.11 -y
conda activate pygeo
conda install -c conda-forge geopandas rasterio pyogrio shapely fiona pyproj tqdm -y如果你主要处理矢量数据,核心库是 GeoPandas、Shapely、Pyogrio 和 PyProj。如果还要处理 GeoTIFF、DEM、遥感影像,建议同时安装 Rasterio。
步骤二:建立标准目录结构
批量任务最怕文件混乱。建议先整理为以下结构:
project/
input_vector/
roads.shp
rivers.shp
landuse.gpkg
input_raster/
dem_01.tif
dem_02.tif
boundary/
study_area.gpkg
output/
vector_clipped/
raster_clipped/
logs/目录结构清楚之后,后续写入地理数据处理PDF、项目说明或复现脚本都会更容易。
步骤三:读取研究区边界并统一目标坐标系
研究区边界是整个批量裁剪流程的核心。建议使用 GeoPackage 保存边界,减少 Shapefile 字段名、编码和多文件丢失问题。
from pathlib import Path
import geopandas as gpd
project_dir = Path("project")
boundary_path = project_dir / "boundary" / "study_area.gpkg"
target_crs = "EPSG:4547" # 示例:CGCS2000 / 3-degree Gauss-Kruger zone,实际请替换为项目坐标系
boundary = gpd.read_file(boundary_path)
boundary = boundary[~boundary.geometry.is_empty & boundary.geometry.notnull()]
if boundary.crs is None:
raise ValueError("研究区边界缺少坐标系,请先在 QGIS 或 ArcGIS Pro 中正确定义 CRS。")
boundary = boundary.to_crs(target_crs)
boundary_union = boundary.geometry.union_all()这里有两个重要动作:第一,检查边界是否有坐标系;第二,把边界转换到目标坐标系。后面所有输入数据都转换到同一个目标坐标系后再裁剪。
步骤四:批量处理矢量数据:先投影转换,再裁剪
下面的代码会遍历输入目录中的 Shapefile 和 GeoPackage,将每个图层转换到目标坐标系,然后按研究区边界裁剪,输出为 GeoPackage。
from pathlib import Path
import geopandas as gpd
from tqdm import tqdm
input_dir = project_dir / "input_vector"
output_dir = project_dir / "output" / "vector_clipped"
output_dir.mkdir(parents=True, exist_ok=True)
vector_files = list(input_dir.glob("*.shp")) + list(input_dir.glob("*.gpkg"))
for file_path in tqdm(vector_files, desc="处理矢量数据"):
try:
gdf = gpd.read_file(file_path)
if gdf.empty:
print(f"跳过空图层:{file_path.name}")
continue
if gdf.crs is None:
print(f"跳过缺少坐标系的数据:{file_path.name}")
continue
gdf = gdf[~gdf.geometry.is_empty & gdf.geometry.notnull()]
if gdf.empty:
print(f"跳过无有效几何的数据:{file_path.name}")
continue
gdf = gdf.to_crs(target_crs)
# 先用边界外包矩形做快速筛选,减少参与精确裁剪的要素数量
minx, miny, maxx, maxy = boundary.total_bounds
gdf = gdf.cx[minx:maxx, miny:maxy]
if gdf.empty:
print(f"裁剪范围内无要素:{file_path.name}")
continue
clipped = gpd.clip(gdf, boundary)
if clipped.empty:
print(f"精确裁剪后为空:{file_path.name}")
continue
output_path = output_dir / f"{file_path.stem}_clip.gpkg"
clipped.to_file(output_path, driver="GPKG", layer=file_path.stem)
except Exception as e:
print(f"处理失败:{file_path.name},原因:{e}")这段脚本适合大多数中小规模矢量数据处理。它解决了 Python 地理处理效率低的几个常见问题:先做坐标系统一、先用外包矩形粗筛、避免无效几何进入裁剪、失败文件不中断整个批处理。
步骤五:批量处理栅格数据:投影转换与掩膜裁剪
栅格数据的处理方式与矢量不同。对于 GeoTIFF,通常使用 Rasterio 读取影像、根据边界生成掩膜,并写出裁剪结果。若栅格坐标系与目标坐标系不同,建议先重投影,再裁剪。
import rasterio
from rasterio.mask import mask
from rasterio.warp import calculate_default_transform, reproject, Resampling
from shapely.geometry import mapping
import tempfile
raster_input_dir = project_dir / "input_raster"
raster_output_dir = project_dir / "output" / "raster_clipped"
raster_output_dir.mkdir(parents=True, exist_ok=True)
raster_files = list(raster_input_dir.glob("*.tif"))
def reproject_raster(src_path, dst_path, dst_crs):
with rasterio.open(src_path) as src:
transform, width, height = calculate_default_transform(
src.crs, dst_crs, src.width, src.height, *src.bounds
)
kwargs = src.meta.copy()
kwargs.update({
"crs": dst_crs,
"transform": transform,
"width": width,
"height": height
})
with rasterio.open(dst_path, "w", **kwargs) as dst:
for i in range(1, src.count + 1):
reproject(
source=rasterio.band(src, i),
destination=rasterio.band(dst, i),
src_transform=src.transform,
src_crs=src.crs,
dst_transform=transform,
dst_crs=dst_crs,
resampling=Resampling.nearest
)
for raster_path in tqdm(raster_files, desc="处理栅格数据"):
try:
with rasterio.open(raster_path) as src:
if src.crs is None:
print(f"跳过缺少坐标系的栅格:{raster_path.name}")
continue
with tempfile.TemporaryDirectory() as tmpdir:
tmp_reproject = Path(tmpdir) / f"{raster_path.stem}_reproject.tif"
reproject_raster(raster_path, tmp_reproject, target_crs)
with rasterio.open(tmp_reproject) as src:
shapes = [mapping(geom) for geom in boundary.geometry]
out_image, out_transform = mask(src, shapes, crop=True)
out_meta = src.meta.copy()
out_meta.update({
"height": out_image.shape[1],
"width": out_image.shape[2],
"transform": out_transform
})
output_path = raster_output_dir / f"{raster_path.stem}_clip.tif"
with rasterio.open(output_path, "w", **out_meta) as dst:
dst.write(out_image)
except Exception as e:
print(f"栅格处理失败:{raster_path.name},原因:{e}")如果是连续型栅格,例如 DEM、温度、降水,可以将重采样方式改为 bilinear 或 cubic;如果是分类栅格,例如土地利用、土壤类型,通常使用 nearest,避免类别值被插值成不存在的编码。
步骤六:验证输出结果
批量裁剪和投影转换完成后,不要只看脚本是否报错,还要检查结果是否正确。
- 在 QGIS 或 ArcGIS Pro 中叠加研究区边界和输出结果,确认没有明显偏移。
- 检查输出图层 CRS 是否等于目标坐标系。
- 检查裁剪结果是否为空,尤其是原始数据范围与研究区是否真的相交。
- 抽查属性字段是否保留完整,中文字段是否乱码。
- 对栅格检查 NoData、像元大小、波段数量和空间范围。
check_file = output_dir / "roads_clip.gpkg"
result = gpd.read_file(check_file)
print(result.crs)
print(result.total_bounds)
print(result.shape)常见坑
坑一:把“定义投影”和“投影转换”混为一谈
定义投影只是告诉软件“这个数据原本是什么坐标系”,不会改变坐标值。投影转换才会重新计算坐标值。如果原始数据坐标系写错了,直接 to_crs 会得到错误结果。
判断方法很简单:如果图层坐标值是 116、39 这样的经纬度,却被定义成米制投影坐标,说明 CRS 定义有问题;如果坐标值是 500000、4300000 这样的米制坐标,却被定义成 EPSG:4326,也是不对的。
坑二:经纬度坐标下直接做面积、长度和缓冲区
EPSG:4326 的单位是度,不是米。批量裁剪本身可以在经纬度下完成,但如果后续要计算面积、长度或缓冲区,应先投影转换到合适的米制坐标系。
坑三:Shapefile 字段名被截断
Shapefile 字段名长度限制较明显,中文编码也容易出问题。批量输出时建议优先使用 GeoPackage。对于项目归档或地理数据处理PDF说明,也更容易描述为一个文件一个图层或一个 GeoPackage 多图层。
坑四:一次性读取超大数据
GeoPandas 对中小规模矢量数据非常方便,但超大数据一次性读入内存会慢。可以考虑使用 bbox 参数预筛选、Pyogrio 加速读取,或将数据入库到 PostGIS 后使用空间索引处理。
坑五:忽略无效几何
无效几何可能导致 clip、overlay、intersection 报错。对于来源复杂的数据,可以在裁剪前检查并修复。
gdf["is_valid"] = gdf.geometry.is_valid
invalid_count = (~gdf["is_valid"]).sum()
print(f"无效几何数量:{invalid_count}")
gdf["geometry"] = gdf.geometry.make_valid()方法比较
| 方法 | 适合场景 | 优点 | 限制 |
|---|---|---|---|
| QGIS 批处理工具 | 文件数量不多、需要可视化操作 | 上手快,参数直观,便于检查 | 自动化程度有限,大量文件管理较麻烦 |
| ArcGIS Pro ModelBuilder | ArcGIS 工作流、单位已有许可 | 流程图清晰,适合团队共享 | 环境依赖许可,跨平台能力较弱 |
| Python GeoPandas | 中小规模矢量批量裁剪与投影转换 | 代码简洁,适合教学、分析和自动化 | 超大数据可能受内存限制 |
| Rasterio | GeoTIFF、DEM、遥感影像裁剪和重投影 | 栅格处理能力强,适合脚本化 | 需要理解像元、NoData、重采样方式 |
| PostGIS | 大规模矢量数据、多人协作、长期项目 | 空间索引强,适合海量数据查询和裁剪 | 需要数据库部署和 SQL 基础 |
如果只是几十个图层,Python GeoPandas 足够实用。如果数据达到数百万要素、需要频繁查询和多人共享,建议考虑 PostGIS。如果主要处理栅格,Rasterio 比 GeoPandas 更合适。
检查清单
下面这份清单可以直接放进地理数据处理PDF或项目交付说明中,用于复查批量裁剪与投影转换结果。
- 是否确认所有输入数据的坐标系不是空值?
- 是否区分了“定义投影”和“投影转换”?
- 目标坐标系是否与项目要求一致,例如 CGCS2000、高斯投影或地方坐标系?
- 研究区边界是否为有效几何,是否存在空几何或自相交?
- 裁剪前是否统一了输入数据和边界数据的 CRS?
- 是否对大范围数据先做 bbox 粗筛,减少精确裁剪计算量?
- 输出格式是否优先使用 GeoPackage 或 GeoTIFF?
- 栅格重采样方法是否符合数据类型:分类用 nearest,连续值可用 bilinear?
- 是否记录了失败文件名称和失败原因?
- 是否在 QGIS 或 ArcGIS Pro 中抽查了输出结果的空间位置和属性字段?
FAQ
Python地理处理效率低,最先应该优化哪里?
优先检查三点:是否重复读取同一个边界文件、是否在坐标系不一致时直接裁剪、是否把超大数据一次性读入内存。多数批量裁剪效率问题都出在这三个地方。
批量裁剪时应该先裁剪还是先投影转换?
通常建议先投影转换到目标坐标系,再裁剪。这样可以避免坐标系不一致导致的空结果或偏移。如果数据特别大,也可以先用原坐标系下的外包矩形做粗筛,但精确裁剪前仍应统一 CRS。
GeoPandas 适合处理多大的矢量数据?
GeoPandas 适合中小规模矢量数据处理。具体上限取决于内存、几何复杂度和字段数量。如果数据量很大,建议使用 Pyogrio 加速读取,或者迁移到 PostGIS 通过空间索引处理。
投影转换后图层偏移是什么原因?
最常见原因是原始 CRS 定义错误。例如数据实际是 CGCS2000,却被标成 WGS84;或者数据实际是经纬度,却被定义为投影坐标。应先确认原始数据坐标值特征,再决定是定义 CRS 还是执行 to_crs。
地理数据处理PDF应该包含哪些内容?
建议包含数据来源、输入格式、目标坐标系、处理软件与 Python 环境、批量裁剪方法、投影转换参数、输出目录、质量检查结果和异常文件说明。这样后续复核、验收和项目移交都会更清楚。
为什么裁剪结果为空?
常见原因包括:输入数据与研究区没有空间相交、坐标系定义错误、边界图层为空、几何无效、经纬度与米制投影混用。可以先在 QGIS 中叠加查看,再检查 total_bounds 和 CRS。
栅格投影转换应该选择哪种重采样方法?
分类数据如土地利用、行政编码、土壤类型,建议使用 nearest。连续数据如 DEM、温度、降水,可以使用 bilinear 或 cubic。不要对分类栅格使用双线性插值,否则会产生不存在的类别值。
结论
Python地理处理效率低,很多时候不是语言问题,而是流程问题。对于批量裁剪与投影转换,推荐的稳定流程是:整理目录、确认 CRS、修复几何、统一目标坐标系、先粗筛再精确裁剪、输出标准格式、最后抽查结果。
在日常 GIS 项目中,Python 的优势不在于替代所有桌面软件,而在于把重复、可规则化、需要记录的处理步骤脚本化。把本文的代码和检查清单整理进地理数据处理PDF,就可以形成一套可复现、可交付、可审查的批处理工作流。