Python地理处理如何提速?批量处理矢量数据实战技巧(附:GDAL脚本库)
《Python地理处理如何提速?批量处理矢量数据实战技巧(附:GDAL脚本库)》这篇文章面向经常处理 Shapefile、GeoPackage、GeoJSON、FileGDB 等矢量数据的 GIS 同学,重点解决一个具体问题:同样是批量裁剪、重投影、字段清理和格式转换,为什么 Python 地理处理有时很慢,以及怎样用 GDAL/OGR、GeoPandas 和合理的批处理策略把流程做稳、做快。
引言:Python地理处理慢,通常不是 Python 本身的问题
很多人第一次写 Python 地理处理脚本时,会把慢归因于“Python 性能差”。但在矢量数据批量处理中,真正拖慢速度的往往是下面几类问题:
- 逐要素循环读取和写入,每处理一个要素就触发一次磁盘 I/O。
- 输入数据没有空间索引,空间筛选和叠加分析全表扫描。
- 坐标系不统一,每一步都在隐式重投影。
- Shapefile 字段限制、编码问题、碎片文件过多,导致写出速度慢且容易报错。
- 用 GeoPandas 承担了本该交给 GDAL/OGR 流式处理的任务。
- 批处理没有跳过已完成结果,失败后只能从头重跑。
所以,Python地理处理提速的核心不是盲目上多进程,而是先把数据读写、空间索引、坐标系统一、工具选择和任务拆分做好。
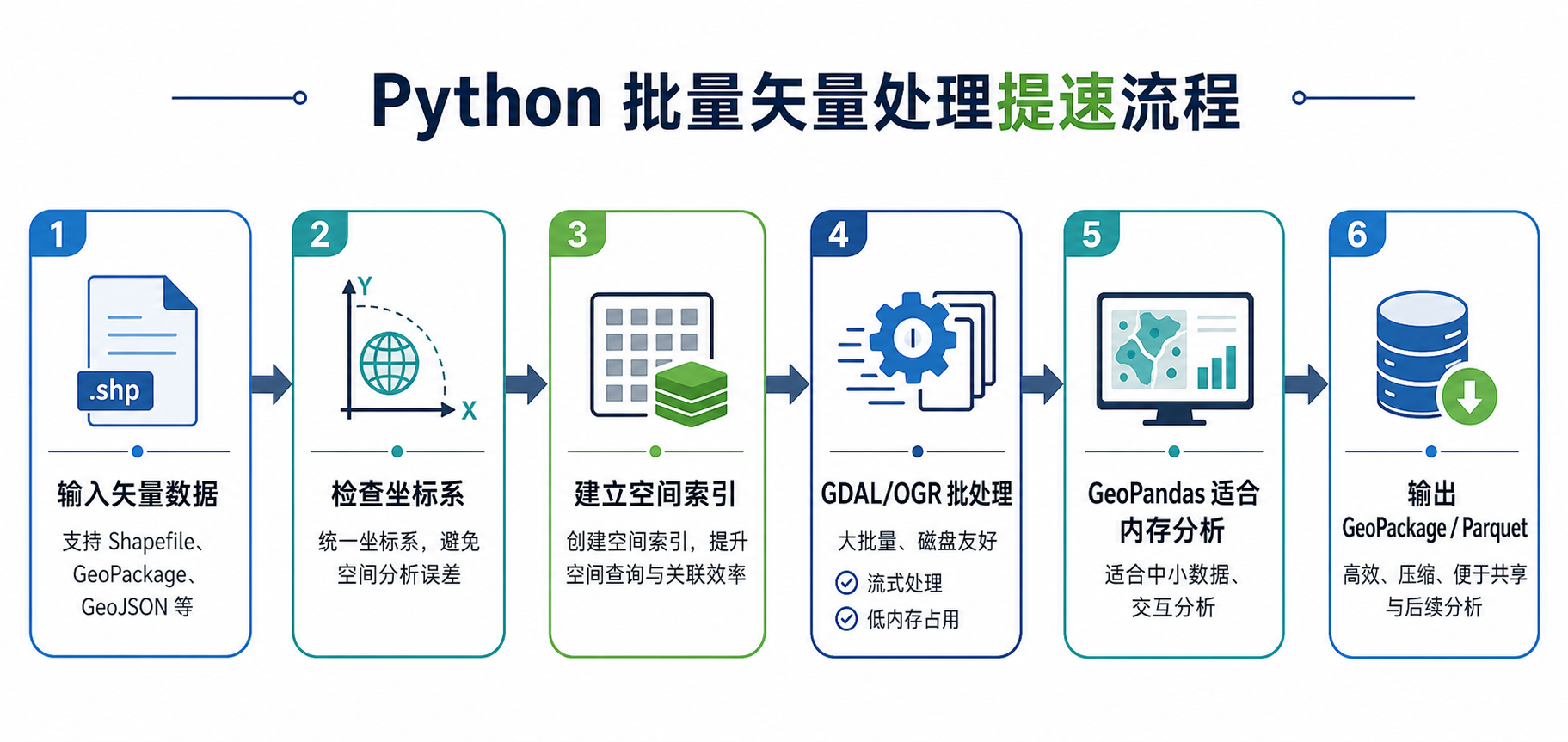
背景:哪些批量矢量处理任务最容易变慢
在日常 GIS 项目中,Python地理处理常见于以下批量任务:
- 把多个 Shapefile 批量转换为 GeoPackage。
- 将不同坐标系的数据统一重投影为 CGCS2000、WGS84 或 Web Mercator。
- 按行政区边界批量裁剪道路、建筑、POI、用地等矢量图层。
- 清理字段、修改编码、删除空几何、修复无效几何。
- 从大量矢量文件中按空间范围筛选数据。
- 把多个分幅图层合并成一个数据库图层。
这些任务有一个共同特点:数据量不一定特别大,但文件数量多、格式复杂、字段不一致、坐标系混乱。此时,如果脚本每次都完整读入内存,或者每个小文件都反复打开关闭,就会出现明显的性能瓶颈。
原理:Python地理处理提速要抓住四个瓶颈
1. 磁盘 I/O 比计算更容易成为瓶颈
矢量数据处理不是纯计算任务。读取图层、解析几何、写出字段、更新索引,都会访问磁盘。尤其是 Shapefile,一个图层通常由 .shp、.shx、.dbf、.prj、.cpg 等多个文件组成,批量处理时文件碎片会放大 I/O 成本。
因此,批量处理矢量数据时,优先考虑使用 GeoPackage、FlatGeobuf 或数据库型格式,而不是把中间结果继续写成大量 Shapefile。
2. 空间索引决定空间查询是否高效
空间索引可以理解为“给几何对象建立目录”。没有空间索引时,程序需要把每个要素都拿出来判断是否相交、包含或落入范围;有空间索引时,可以先快速缩小候选要素范围。
对于裁剪、相交、范围筛选、点落区等任务,空间索引通常比多进程更重要。GDAL/OGR、GeoPackage、PostGIS、GeoPandas 都可以使用空间索引,但具体效果取决于数据格式和调用方式。
3. 坐标系统一可以减少重复转换
如果输入图层、裁剪范围、输出目标坐标系不一致,脚本可能在每次处理时都做坐标转换。少量数据看不出来,批量数据就会明显变慢,还容易引入面积、长度和拓扑判断误差。
建议在批处理前先做一次坐标系检查,把所有输入数据统一到项目坐标系,再执行裁剪、叠加、统计等分析。
4. 工具选择会影响整个流程上限
GeoPandas 适合表格化空间分析、字段计算、和 Pandas 结合的数据处理;GDAL/OGR 更适合格式转换、批量重投影、裁剪、按 SQL 筛选和流式写出。真正高效的 Python地理处理通常是二者配合,而不是只用一个库完成所有任务。
步骤:批量处理矢量数据的提速实战流程
步骤一:先扫描输入数据,生成处理清单
不要一上来就处理。先扫描目录,找出真实需要处理的矢量文件,排除临时文件、重复文件和已经完成的结果。
from pathlib import Path
input_dir = Path(r"D:gis_projectinput")
output_dir = Path(r"D:gis_projectoutput")
output_dir.mkdir(parents=True, exist_ok=True)
vector_files = []
for ext in ["*.shp", "*.gpkg", "*.geojson"]:
vector_files.extend(input_dir.rglob(ext))
print(f"发现矢量文件数量:{len(vector_files)}")
for f in vector_files[:10]:
print(f)这个清单的意义不只是“找到文件”,还可以用于后续断点续跑、日志记录和失败重试。
步骤二:优先把中间结果写入 GeoPackage
如果你的批处理链路中有多个中间步骤,建议把中间结果统一写为 GeoPackage。它比 Shapefile 更适合现代 GIS 流程,支持较长字段名、统一单文件存储、多图层、空间索引和 UTF-8 编码。
from osgeo import ogr
from pathlib import Path
def convert_to_gpkg(src_path, dst_gpkg, layer_name):
driver = ogr.GetDriverByName("GPKG")
if Path(dst_gpkg).exists():
ds_out = ogr.Open(str(dst_gpkg), update=1)
else:
ds_out = driver.CreateDataSource(str(dst_gpkg))
ds_in = ogr.Open(str(src_path))
if ds_in is None:
raise RuntimeError(f"无法打开输入文件:{src_path}")
layer_in = ds_in.GetLayer(0)
if ds_out.GetLayerByName(layer_name):
ds_out.DeleteLayer(layer_name)
ds_out.CopyLayer(layer_in, layer_name)
ds_in = None
ds_out = None
convert_to_gpkg(
r"D:gis_projectinputroads.shp",
r"D:gis_projectoutputresult.gpkg",
"roads"
)如果只是格式转换,命令行版 ogr2ogr 通常更简洁,也更适合写入批处理脚本。
ogr2ogr -f GPKG D:gis_projectoutputroads.gpkg D:gis_projectinputroads.shp -nln roads步骤三:用 ogr2ogr 批量重投影,避免在分析中反复转换
批量重投影建议独立成一个预处理步骤。这样后续所有空间分析都在同一坐标系下执行,结果更稳定,速度也更容易控制。
from pathlib import Path
import subprocess
input_dir = Path(r"D:gis_projectinput")
output_dir = Path(r"D:gis_projectprojected")
output_dir.mkdir(parents=True, exist_ok=True)
target_epsg = "EPSG:4490"
for shp in input_dir.rglob("*.shp"):
out_file = output_dir / f"{shp.stem}_4490.gpkg"
if out_file.exists():
print(f"跳过已存在:{out_file}")
continue
cmd = [
"ogr2ogr",
"-f", "GPKG",
str(out_file),
str(shp),
"-t_srs", target_epsg,
"-lco", "SPATIAL_INDEX=YES"
]
print("运行:", " ".join(cmd))
subprocess.run(cmd, check=True)这里的 -t_srs 表示目标坐标系,-lco SPATIAL_INDEX=YES 表示创建图层空间索引。对后续空间查询、裁剪和加载都有帮助。
步骤四:用空间范围先过滤,再做精确分析
如果你只需要某个研究区范围内的数据,不要先读入全国或全省数据再用 Python 裁剪。可以先让 GDAL/OGR 在读取阶段做空间过滤。
ogr2ogr -f GPKG D:gis_projectoutputroads_clip_bbox.gpkg D:gis_projectinputroads.gpkg roads -spat 113.0 22.0 114.0 23.0-spat 使用的是矩形范围过滤,速度快,但它不是精确裁剪。适合先缩小数据量,然后再用精确边界做裁剪。
如果需要按边界图层精确裁剪,可以使用 -clipsrc:
ogr2ogr -f GPKG D:gis_projectoutputroads_clip.gpkg D:gis_projectinputroads.gpkg roads -clipsrc D:gis_projectboundarycity_boundary.gpkg步骤五:字段清理尽量用 SQL 或批量操作
逐要素逐字段修改会很慢。对于字段选择、重命名、类型转换等操作,优先用 SQL 表达式完成。
ogr2ogr -f GPKG D:gis_projectoutputpoi_clean.gpkg D:gis_projectinputpoi.gpkg poi -sql "SELECT name, type, address, geom FROM poi WHERE name IS NOT NULL"如果字段逻辑比较复杂,再考虑使用 GeoPandas:
import geopandas as gpd
src = r"D:gis_projectinputpoi.gpkg"
dst = r"D:gis_projectoutputpoi_clean.gpkg"
gdf = gpd.read_file(src, layer="poi")
gdf = gdf[gdf["name"].notna()].copy()
gdf["type"] = gdf["type"].fillna("未分类")
gdf["name_len"] = gdf["name"].str.len()
gdf.to_file(dst, layer="poi_clean", driver="GPKG")原则是:简单筛选、投影、裁剪、格式转换交给 GDAL;复杂字段计算、表连接、统计分析交给 GeoPandas。
步骤六:修复无效几何,减少叠加分析失败
批量处理矢量数据时,经常会遇到无效几何,例如自相交面、空几何、重复节点。这些问题会导致裁剪、相交、合并时失败或变慢。
GDAL 可以使用 -makevalid 尝试修复几何:
ogr2ogr -f GPKG D:gis_projectoutputlanduse_valid.gpkg D:gis_projectinputlanduse.gpkg landuse -makevalidGeoPandas 中也可以检查几何有效性:
import geopandas as gpd
gdf = gpd.read_file(r"D:gis_projectinputlanduse.gpkg")
invalid_count = (~gdf.geometry.is_valid).sum()
empty_count = gdf.geometry.is_empty.sum()
print("无效几何数量:", invalid_count)
print("空几何数量:", empty_count)
gdf = gdf[gdf.geometry.notna()]
gdf = gdf[~gdf.geometry.is_empty]注意,几何修复可能改变局部边界结构。用于权属、地籍、规划红线等高精度数据时,不建议盲目自动修复,应该先备份并抽样核查。
步骤七:把日志和断点续跑写进脚本
批量任务最怕运行到 90% 时中断,然后无法判断哪些文件已经完成。最简单的做法是:输出文件存在就跳过,失败文件写入日志。
from pathlib import Path
import subprocess
input_dir = Path(r"D:gis_projectinput")
output_dir = Path(r"D:gis_projectoutput")
log_file = output_dir / "failed_files.txt"
output_dir.mkdir(parents=True, exist_ok=True)
failed = []
for src in input_dir.rglob("*.shp"):
dst = output_dir / f"{src.stem}.gpkg"
if dst.exists():
print(f"已完成,跳过:{dst.name}")
continue
cmd = [
"ogr2ogr",
"-f", "GPKG",
str(dst),
str(src),
"-t_srs", "EPSG:4490",
"-lco", "SPATIAL_INDEX=YES"
]
try:
subprocess.run(cmd, check=True)
print(f"完成:{src.name}")
except subprocess.CalledProcessError:
print(f"失败:{src}")
failed.append(str(src))
if failed:
log_file.write_text("n".join(failed), encoding="utf-8")
print(f"失败文件已写入:{log_file}")这个模式看起来简单,但非常适合生产环境。它能让 Python地理处理从“临时脚本”变成“可重复执行的工作流”。
步骤八:谨慎使用多进程,不要让磁盘先崩
多进程适合每个文件相互独立、CPU 计算较重、磁盘读写压力可控的任务。如果任务主要是读写大型文件,多进程可能让多个进程同时抢磁盘,结果反而更慢。
下面是一个适合独立文件转换的多进程模板:
from pathlib import Path
import subprocess
from concurrent.futures import ProcessPoolExecutor, as_completed
input_dir = Path(r"D:gis_projectinput")
output_dir = Path(r"D:gis_projectoutput")
output_dir.mkdir(parents=True, exist_ok=True)
def convert_one(src):
src = Path(src)
dst = output_dir / f"{src.stem}.gpkg"
if dst.exists():
return f"跳过:{src.name}"
cmd = [
"ogr2ogr",
"-f", "GPKG",
str(dst),
str(src),
"-t_srs", "EPSG:4490",
"-lco", "SPATIAL_INDEX=YES"
]
subprocess.run(cmd, check=True)
return f"完成:{src.name}"
files = list(input_dir.rglob("*.shp"))
with ProcessPoolExecutor(max_workers=4) as executor:
futures = [executor.submit(convert_one, str(f)) for f in files]
for future in as_completed(futures):
try:
print(future.result())
except Exception as e:
print("任务失败:", e)max_workers 不要盲目设置为 CPU 核心数。对于普通机械硬盘或网络共享目录,2 到 4 个进程往往更稳;对于 SSD、本地临时目录和独立小文件,可以适当增加。
常见坑:Python地理处理提速前必须排查的问题
坑一:输入数据坐标系缺失或错误
如果 .prj 文件缺失,或者图层声明的坐标系和真实坐标不一致,重投影会得到错误结果。提速前先确认坐标系,否则速度再快也只是更快地产生错误数据。
- 经纬度坐标通常数值在 -180 到 180、-90 到 90 范围内。
- 投影坐标通常是米单位,数值可能是几十万、几百万。
- 同一项目中用于叠加的数据必须处于同一坐标系。
坑二:Shapefile 字段名被截断
Shapefile 字段名通常存在长度限制,中文字段和长字段名容易被截断或乱码。批量处理后如果发现字段丢失,不一定是脚本逻辑错,也可能是格式本身限制导致。
建议中间成果和最终成果优先使用 GeoPackage。如果必须交付 Shapefile,最后一步再导出,并检查字段名、编码和字段类型。
坑三:一次性读入超大图层
GeoPandas 很方便,但它通常会把数据读入内存。对于几百万要素的图层,一次性读取可能造成内存不足。此时应先用 GDAL/OGR 按范围、字段、图层进行过滤,再把较小结果交给 GeoPandas 分析。
坑四:没有建立空间索引
空间叠加、裁剪、点面匹配很慢时,先检查空间索引。GeoPackage 通常可以创建空间索引;PostGIS 需要为几何字段建立 GiST 索引;GeoPandas 则依赖底层空间索引库。
CREATE INDEX idx_roads_geom ON roads USING GIST (geom);如果数据已经进入 PostGIS,建立空间索引往往比在 Python 里继续优化循环更有效。
坑五:并行写同一个输出文件
多进程批处理时,不建议多个进程同时写同一个 GeoPackage 图层或同一个文件。更稳妥的方式是每个进程写独立临时文件,全部完成后再合并。
方法比较:GDAL、GeoPandas、PostGIS 怎么选
| 工具 | 适合任务 | 优势 | 注意事项 |
|---|---|---|---|
| GDAL/OGR | 格式转换、重投影、裁剪、字段筛选、批量导入导出 | 稳定、速度快、适合流式处理和命令行自动化 | 复杂业务逻辑写起来不如 Python 表达直观 |
| GeoPandas | 字段计算、空间连接、统计分析、和 Pandas 结合处理 | 语法友好,适合数据分析人员 | 大数据量时容易受内存限制 |
| PostGIS | 长期管理、多用户查询、复杂空间 SQL、大规模空间检索 | 空间索引强,适合生产数据库和 WebGIS 后端 | 需要数据库部署和 SQL 能力 |
| ArcPy | ArcGIS Pro 环境内的地理处理模型、企业地理数据库任务 | 与 ArcGIS 工具箱集成紧密 | 依赖授权环境,跨平台自动化不如 GDAL 灵活 |
简单判断:如果目标是“批量处理矢量数据并尽快得到标准输出”,优先从 GDAL/OGR 开始;如果目标是“分析字段和几何关系”,使用 GeoPandas;如果数据要长期查询和共享,考虑 PostGIS。
检查清单:批处理脚本运行前后这样验收
运行前检查
- 输入文件是否完整,Shapefile 是否包含 .shp、.shx、.dbf、.prj。
- 坐标系是否明确,是否需要统一到目标 EPSG。
- 输出格式是否合适,是否可以改用 GeoPackage。
- 是否需要建立空间索引。
- 是否需要先修复无效几何。
- 输出目录是否有足够磁盘空间。
- 脚本是否支持跳过已完成文件。
运行中检查
- 是否记录了当前处理文件名。
- 失败文件是否写入日志。
- CPU、内存、磁盘占用是否异常。
- 多进程数量是否导致磁盘长时间满负载。
运行后检查
- 输出文件数量是否和预期一致。
- 要素数量是否明显异常。
- 坐标范围是否落在正确区域。
- 字段名、字段类型、编码是否正确。
- 抽样打开成果图层,检查几何是否偏移、缺失或破碎。
- 对裁剪结果检查边界附近是否存在异常空洞或多余要素。
FAQ:Python地理处理提速常见问题
Python地理处理一定要用多进程吗?
不一定。多进程只是提速手段之一。对于批量矢量数据处理,坐标系统一、空间索引、减少中间文件、使用 GDAL/OGR 流式处理,往往比直接多进程更有效。只有在任务相互独立、磁盘压力可控时,多进程才值得使用。
批量处理矢量数据时,为什么推荐 GeoPackage?
GeoPackage 是单文件数据库格式,支持多图层、较完整字段名、UTF-8 编码和空间索引。相比 Shapefile,它更适合作为 Python地理处理的中间结果和成果格式,尤其适合批量转换、裁剪和重投影流程。
GDAL脚本库和 GeoPandas 能不能一起用?
可以,而且很推荐。GDAL脚本库适合处理格式转换、重投影、裁剪、范围过滤等偏底层的任务;GeoPandas 适合做字段计算、空间连接、统计汇总等分析任务。二者结合可以兼顾速度和代码可读性。
为什么同一个裁剪任务,QGIS 很快,Python 脚本却很慢?
常见原因是 QGIS 背后调用了 GDAL 或原生处理工具,并使用了空间索引;而 Python 脚本可能把所有要素读入内存后逐条判断。可以检查脚本是否使用了空间过滤、是否建立空间索引、是否避免了逐要素写出。
ogr2ogr 命令适合放进 Python 脚本吗?
适合。很多生产环境中的 Python 地理处理脚本,实际上就是用 Python 管理文件清单、日志、异常和批处理流程,再调用 ogr2ogr 执行高效的数据转换与裁剪。这种方式简单、稳定、容易维护。
处理超大矢量数据时,GeoPandas 内存不够怎么办?
可以先用 GDAL/OGR 按空间范围、字段条件或图层范围过滤,生成较小的中间数据,再交给 GeoPandas。也可以考虑把数据导入 PostGIS,通过空间 SQL 和索引完成筛选、叠加和统计。
结论:先优化流程,再优化代码
Python地理处理如何提速,关键不在于写出更复杂的 Python 语法,而在于把批量处理矢量数据的流程设计正确:统一坐标系、减少 Shapefile 中间文件、建立空间索引、用 GDAL/OGR 做批量转换和裁剪、用 GeoPandas 做分析、用日志和断点续跑保证稳定性。
如果你正在处理大量矢量文件,可以先从本文的 GDAL脚本库模板开始,把“扫描文件、跳过已完成、统一重投影、创建空间索引、记录失败日志”这几件事固定下来。这样即使数据规模变大,整个 Python 地理处理流程也会更可控、更容易排错。